本篇论文目录导航:
【题目】套利视角下我国资本管制有效程度探析
【第一章 第二章】资本管制程度测算方法的文献综述
【第三章】境内外人民币远期市场间的套利机制分析
【第四章】基于AB-SETAR模型的资本管制程度实证分析
【结论/参考文献】我国资本管制有效性研究结论与参考文献
第 4 章 基于 AB-SETAR 模型的资本管制程度实证分析
4.1 模型简介及适用性分析
4.1.1 SETAR 模型简介
SETAR 模型,即 Self-Exciting Threshold Autoregression 模型,国内一般译为自激励门限自回归模型,最早由 Tong(1978)[33]提出。随后,Tsay (1989)[34],Chan (1991)[35],Hansen (1999a[36],1999b[37])等学者对模型假设,模型检验及模型参数估计等方面进行了深入研究,目前 SETAR 模型在研究非线性时间序列方面占有重要地位。之所以叫做自激励模型(Self-Exciting),是因为 SETAR 模型与普通 TAR 模型的区别在于它的判别变量是因变量的滞后变量,而非外生变量,因此是变量自身的变化激发了不同状态之间的转换。这里以最简单的 SETAR(1,1,2)模型为例对 SETAR 模型的核心建模思路进行简要介绍。

如(4.1)式所示,ty 的自回归函数与t1y相对于 r 大小有关:当t1y?大于等于 r时,ty 遵循t 1 t 1 1ty β yε?= + ,否则有t 2 t 1 2ty β yε?= + .一般来讲,SETAR 模型可以由SETAR(d,p,r)的形式描述。其中,d 为自回归阶数,p 为判别变量阶数,r 为制度个数(即门限个数加 1)。本文所采用的 SETAR 模型是非对称区间自激励门限自回归,它具有两个门限即三个制度(regime),在每个制度中分别对应着不同的自回归形式。
具体形式如(4.2)所示。
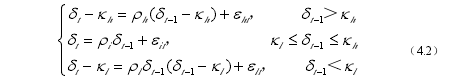
(4.2)式中,tδ 为被研究的时间序列,2(0, ), , ,jt jε N σ j = i h l, ,h lκ κ 分别为上阀值与下阀值。此处对 AB-SETAR 模型里的非对称和边界的含义结合(4.2)式给出解释。非对称指的是 ,h lκ κ 两个阀值的绝对值不相等,也就意味着模型测度出来的上下套利成本是不相同的。Pasricha(2007)[24]证明了即使外汇套利行为中买卖两个方向的交易成本与管制强度是对称的,其相应的回归门限也可能不同,因此在度量资本管制程度时假设对称的上下门限是不合适的。边界回归是指 SETAR 的自回归并非将偏离值拉向原点,而是在套利行为的驱动下,将价差拉向套利区间的边界,因此在上下两种制度中时间序列应为平稳序列;而在中间制度中,由于套利成本的存在,时间序列应符合随机游走(random walk)假定。
4.1.2 SETAR 模型在本文中的适用性分析首先,SETAR 模型与普通 TAR 模型的区别在于,它的判别变量是因变量的滞后变量,而非外生变量,这一特性与套利者在实际中的行为高度吻合。现实中的套利者正是通过观察并分析上一期的价格是否出现偏离,或者两类商品的价差是否在合理范围内,进而判断是否存在可实现的套利机会。
其次,SETAR 模型假定时间序列在不同的区域内服从不同的模型,因此应用SETAR 模型可以区别存在套利行为和不存在套利行为两种情况下时间序列的表现形式。无论价差序列出现正向还是负向的偏西,套利行为总是会促使价差朝着合理(无套利区间)移动。而在无套利区间内,套利者会因为没有套利机会而不参与交易,此时的价格波动会受到其他随机冲击而不会出现调整,因此更符合随机游走过程。
最后,SETAR 模型计算出来的无套利区间(Band)是基于实际价差计算出来使模型残差平方和最小的区间,这一特点非常适合度量由资本管制带来的交易成本。根据资本管制的定义,一切能够阻碍资本自由流动的措施都可以算作资本管制,而这些限制资本自由流动的措施显然会阻碍境内外两类市场上的套利行为。虽然套利者可以通过规避资本管制实现套利,但是规避行为本身并不是零成本的,这需要套利者通过各类手段和方式实现资本的流入或流出。此时规避行为本身的成本,即由资本管制带来的成本自然而然就应当作为套利者的套利成本并加入总交易成本中,低于此时总交易成本的套利机会也就会被套利者视为非套利机会。因此,这种由资本管制带来交易成本一方面是衡量一国资本管制强度相当好的替代变量,而另一方面又很难通过直接的方式,如资本管制指数进行准确测量。应用 SETAR 模型计算出的 Band 正是实际套利行为所面临的套利成本,当由手续费造成的正常交易成本不变时,SETAR 模型计算出的 Band 的变化就是资本管制程度变化的最佳度量。
4.2 数据选取和检验
4.2.1 数据来源与处理
本文主要用到人民币 DF(即境内远期)汇率和人民币 NDF 远期汇率两类数据。
其中,人民币远期汇率取中国外汇交易中心每天公布的 3 个月远期外汇买卖平均报价,数据来源为 Wind 金融数据库;人民币 3 个月 NDF 汇率的数据来源为 Bloomberg数据库。远期的时间跨度之所以 3 月期是因为无论在境内还是在境外,只有一年期以内的人民币远期类衍生品较为活跃,而三个月的 DF 和 NDF 是其中最活跃的品种之一,因此 3 个月的远期报价数据也更有价值。
另一方面,由于我国人民币远期市场成立时间较晚,DF 数据最早可取到 2006年 11 月 27 日,因此本文所取数据时间跨度为 2006 年 11 月 27 日到 2013 年 4 月 26日。在对境内外远期交易日进行对照筛选之后,最终的交易日样本共计 1564 个。在确定原始数据之后,本文用 dif 表示人民币 NDF 汇率减去人民币 DF 汇率的差,即:dif = NDF ? DF(4.3)此时,dif 表示 NDF 与 DF 之间的偏离。当 dif 的偏离程度超过套利成本之后,套利者就会通过相应的套利方式进行无风险套利,最终迫使价格回归到正常区间。本章以下部分所研究的时间序列即为 dif 序列。
图 4-1 到 4-3 分别为 2006 年 11 月 27 日到 2013 年 4 月 26 日 DF 升贴水,NDF升贴水和 dif 数据随时间的走势图。此处需要说明的是,图 4-1 到 4-3 中的单位分别为基点,即万分之一个单位,这是因为远期合约报价的方式就是以基点为单位进行报价。但是在计算的过程中,依然以普通汇率值进行计算。
从图 4-1 到 4-3 可以看出,人民币 DF 和 NDF 的走势区别较大,因此带来的偏差不仅在幅度上较大,而且在存续时间上也较长。图 4-3 可以明显看出,在一些时间段内,dif 为负值的存续时间相当长,这也给出了我国外汇管制有效的直观证据。同时,dif 的正负随时间的变化并不具有规律性,且负值出现的此处远大于正值出现的次数,因此可以看出相对于 DF 市场来讲,NDF 市场上人民币的升值预期更为强烈。
4.2.2 滚动一阶自回归检验与 BP 间断点检验
本文借鉴 Hutchison(2010)等人[25]的研究思路,首先对 dif 序列做滚动一阶自回归的检验(rolling AR(1))。滚动一阶自回归是,对给定数据长度为 N 的时间序列,指取定一个时间序列长度 m(m<N),对第 1 个时间序列数据到第 m 个时间序列数据进行一阶自回归,得到的一阶自回归系数记做第 m+1 日的 AR(1)系数。然后对对第 2 个时间序列数据到第 m+1 个时间序列数据进行一阶自回归,得到的一阶自回归系数记做第 m+2 日的 AR(1)系数。依次类推,直到加入回归的时间序列末端取到第 N 个交易日。这样对时间序列数据进行回归可以直观的判断该序列自回归方程的系数是否随时间的推移发生了显着变化。图 4-4 为时间长度取 60 个交易日的滚动一阶自回归检验结果。
dif 的一阶自回归系数随着时间的推移呈现出较为明显的不稳定性,尤其是自 2011 年 8 月之后,回归系数的不稳定性显着加强。这就表明仅用一个单一的线性回归方程来描述 dif 序列的特征必然是不准确的,必须要采用更为复杂的时间序列模型来考察 dif 序列的特征。
应用 Bai 和 Perron(2003)提出的检验间断点(breakpoints Test)的方法,本文对dif 序列进行了间断点检验。如表 4-1 所示,在 BIS 和 RSS 双重准则下,检验结果均表明序列存在三个间断点,并给出相应的 5%和 95%置信区间。
BP 间断点检验面临的一个主要问题在于如何解释通过计量方法得到的间断点,即应该赋予间断点实际意义。从表面上来看,上述三个间断点并未涉及重大的改革试点,但是本文依据国家外汇管理局及相关单位的法律法规的颁布和废止,试图给出一个对上述间断点的合理解释。
第一个间断点位于 2008 年 8 月中下旬,正处于全球金融危机在发达国家爆发的初期,大量资本纷纷逃离发达国家,涌入新兴市场国家。为了抵御热钱的流入,国家外汇管理局于 2008 年 8 月 29 日发布了《国家外汇管理局综合司关于完善外商投资企业外汇资本金支付结汇管理有关业务操作问题的通知》。这一通知旨在强化银行对外商投资企业办理结售汇业务的审查,加强国家外汇管理局对银行办理外商投资企业资本金结汇等业务的监管。因此,这一规定实际上是加大了我国资本管制的程度,尤其是加大了对资本流入的管制程度。反映到境内外远期市场则是两市场间的的套利成本增加,体现在正向汇率差的套利区间变大。
第二个间断点位于 2009 年底到 2010 年初。这一时期,我国 4 万亿投资和 10 万亿信贷带来的负面效应开始显现,房地产市场泡沫此时也开始成为遏制中国政府的。
国际投资者此时开始将各类短期投机资本纷纷撤出,资本外逃现象日益严重。正如国家外汇管理局《中国外汇管理年报--2009》中提到的 2010 年资本项目外汇管理工作的主要思路:"进一步加强跨境资本流动监测分析预警,反映到境内外远期市场则是两市场间的的套利成本增加。有效防范资本流动冲击,维护国家经济金融安全。"相对与上一阶段,此时国家重点防范的是刚见苗头资本外逃,因此国家外汇管理局加强了对资本流出的管制。反映到境内外远期市场体现在负向汇率差的套利区间变大。
第三个间断点位于 2011 年 4 月低到 2011 年 5 月下旬。这期间我国国家外汇管理局分别于 2010 年 5 月 23 日和 5 月 27 日发布了《国家外汇管理局关于取消和调整部分资本项目外汇业务审核权限及管理措施的通知》和《境内居民通过境外特殊目的公司融资及返程投资外汇管理操作规程》。上述管理文件的发布表明一方面我国资本管制有所减弱,资本项目开始逐步放开,另一方面我国资本管制开始向对称监管发展,对资本流入和流出的监管将进一步走向均衡。反映到境内外远期市场则是两市场间的的套利成本减小,体现在正向和负向汇率差的套利区间趋于一致。
4.2.3 序列线性检验(Linearity Test)
正如 Hansen(1999b)所指出的,如果在研究中要应用非线性时间序列模型对相关问题进行研究,那么首先要面临的问题就是,非线性的设定是否优于线性的设定?应用统计学的语言来说就是,是否能够通过拒绝时间序列为线性过程的假设来支持非线性的假设。这个问题是应用 SETAR 模型时的核心问题。本文应用 Hansen(1999b)提出的时间序列线性检验方法,对全样本时间序列数据及四个阶段的时间序列数据分别进行线性检验。同时,本文对不同的门限个数(1 个门限和两个门限)分别进行了检验。
"1vs2"表示原假设为序列为线性过程(一种机制),备择假设序列为非线性,且存在序列一个门限值(两种机制),"1vs3" 原假设为序列为线性过程(一种机制),备择假设序列为非线性,且存在序列两个门限值(三种机制)。从表 5-可以看出,除了在第一阶段进行"1vs2"线性检验时,无法在 10%的显着性水平下拒绝原假设,其余各阶段,包括全样本数据均能在进行"1vs2","1vs3"检验时同时拒绝原假设。也就是说,无论是全样本还是各个阶段,假定时间序列为线性过程是不合理的,非线性时间序列模型更适合描述这一过程。与此同时,四个阶段的检验表明,时间序列存在两个门限值,即时间序列是在三种机制之间相互转换。因此,本文应用AB-SETAR 模型不仅在模型原理上有较好的适用性,同时在模型设定上也有合理性。
4.3 AB-SETAR 模型的回归结果
4.3.1 描述性统计
如表 4-3 所示,四个阶段的样本数据在各个基本统计量上的表现均不同,这也从另一方面证实了本文选择非线性时间序列模型的合理性。从均值来看,第一阶段最小而第二阶段最大;从标准差来看,则第二阶段仍然最大。偏度和峰度都显示第三阶段最接近正态分布,其次为第一阶段,第四阶段偏离最大。总而言之,基本统计量只能进行描述性统计,还需通过进一步的实证分析研究时间序列更重要的特点。
4.3.2 回归结果
4.3.2.1 滞后期的选取
应用任何 AR 类的模型都必须要选取合适的滞后期,此处的滞后期包括两方面,一是 AR 模型的滞后期,二是判别变量的滞后期。首先,Hansen(1999b)[37]在检验SETAR 模型之前首先应用线性模型对时间序列进行拟合,然后利用 AIC 和 SIC 准则确定相应的模型滞后期。本文参照这一方法对各个阶段的数据在不同滞后期的设定下分别进行了回归。结果表明,四个阶段的数据在拟合滞后期超过 1 的线性自回归模型时,AIC 和 SIC 都显着变大。因此,本文将模型滞后期定为 1 阶。对于判别变量的滞后期,前人应用 SETAR 研究套利问题时,往往考虑到其实际意义,将其确定为 1 阶滞后,如 Hutchison 等人(2010)[25].综上,本文应用的模型可以确定为 AB-SETAR(1,1,3)。
4.3.2.2 门限值的确定
应用 SETAR 模型要解决的另一个关键问题是如何确定回归的门限值。本文参照Hansen(1999a)[36]和 Pasricha(2008)[24]的方法,用格点搜寻的思路,以 dif 在每一阶段 10%分位数和 90%分位数之间的所有数为基础,找到所有可能的门限值组合,然后分别计算各门限值组合的模型回归残差,最终选择使残差平方和最小的门限值组合。但是,考虑到在实际情况中套利成本至少为 0,因此本文将 0 到 90%分位数之间的数据作为上门限值可选集,将 5%分位数到 0 之间的分位数之间的数据作为下门限值可选集。同时,为了保证中间状态能有至少 10%的回归样本,本文依据上述原则对不同阶段内的门限值可选集上下区间做了相应调整。
Hmax,Hmin,Lmax,Lmin 分别表示上门限值的上界,上门限值的下界,下门限值的上界和下门限值的下界。在确定上下门限值可选集之后,本文对上述门限值进行了格点搜寻的,即利用所有可能组合进行回归拟合,并选取能使回归残差平方和达到全局最小的门限值组合。以第一阶段为例,如图 4-5 所示,水平上的两个坐标轴分别代表了上门限值的取值和下门限值的取值,垂直坐标轴则表示对应门限值组合下的回归残差平方和。从图 4-5 可以看出,首先,不同的门限值组合可以达到多个局部回归残差平方和最小值,但有且只有一个全局回归残差平方和最小值,此时回归残差平方和约为 0.08617,对应的门限值组合为上门限值为 0.0085,下门限值为-0.042.因此,(0.0085,-0.042)就是第一阶段的门限值组合,这种方法以数据为唯一依据,在很大程度避免了人为设定门限值的随意性和主观性。
再次应用上述方法对其余三个阶段的数据进行检验,各阶段的门限值组合取值结果如表 4-5 和图 4-6 所示。
从表 4-5 可以看出,第二阶段对应的套利成本最高,第一、三、四阶段的套利成本差别并不明显。结合 3.2.3 的分析,从套利成本在正负两方面的不对称性可以看出,我国在第一阶段和第三阶段对资本流出的管制程度要远大于对资本流入的管制程度,而第二阶段则恰恰相反,对资本流入的管制程度要远大于对资本流出的管制程度。第四阶段则体现出较好的对称性,说明我国此时对资本流入和资本流出的管制基本一致,并且相对前三个阶段来讲单向管制强度有所减弱。
4.3.2.3 模型回归结果
依据上述门限组合,应用 AB-SETAR 模型分别对四个阶段的数据进行 OLS 回归分析。
各阶段三个系数所对应的系数标准差都较小,这说明 AR(1)系数是显着的。由 AR(1)模型可知,回归系数的越小,说明上一期对下一期的影响越小,也即是说时间序列的收敛速度也就越快。在表 4-7 中,三个区域的 AR(1)系数在四个阶段内分别呈现出不同的特点。在上部区域,即 dif 大于上门限值时,模型在第一、三、四阶段均能较快收敛,而在第二阶段的系数则较大,说明此时的收敛速度相对较慢。而在下部区域,即 dif 小于下门限时,模型在四个阶段的收敛速度变化不大,但总体上相对与上部区域则要慢一些。但是,在第二阶段,下部区域的收敛速度达到最大,这与上部区域的结论恰好相反。由于中部区域最初认为是随机游走或其他不平稳过程,因此不多做讨论。





