
1 引 言
随着计算机和网络技术的普及与发展,各种数字资源急剧增长,日渐成为信息资源的主流.数字资源具有复杂性、多样性、异构性和海量性等特点,这使得为用户提供更加智能、整合的资源发现与获取服务变得至关重要,而元数据则是其中的关键.由于历史和现实的原因,各数字图书馆往往采用各自不同的元数据标准和软硬件平台来描述与存储数字资源,并且基本上是各自独立管理与维护,造成大量分布式异构数据的存在,形成了许多局部范围内组织良好但整体上分散独立的信息孤岛.为了能够将这些异构分散的资源整合在一起,实现统一检索与访问,促进资源的发现与共享,图书馆采取了一系列解决方案,如 OAI?PMH协议、Z39.50协议、跨库检索、信息链接等[1],但是这些方法都只能解决资源结构和语法上的异构问题,无法解决语义上的异构和互操作问题.另一方面,当前的信息整合方式基本上都是在有限范围内进行,无法形成一个开放的、可无限延伸与扩展的资源整合体系.
语义网的出现改变了 Web以及基于 Web的各种应用,这其中也包括数字图书馆.由于语义网天生具有数据互联和集成的特性,因此将语义网技术应用于资源整合具有强大的潜力.早在 20世纪 90年代就有国外学者开始探索将本体应用于信息资源整合[2],但是由于本体通常是面向特定领域的,因此基于本体的资源整合体系的开放性和扩展性还不够理想.
2006年,伯纳斯·李在语义网的基础上提出了关联数据(linkeddata)的概念[3].关联数据是指在网络上发布、共享、连接各类数据、信息和知识的一种方式,它克服了本体的领域局限性,实现了数据之间开放的无缝互联.当前,越来越多的研究者和组织机构认识到关联数据在数据发布、共享和互联方面的独特优势,开始将其应用于各个领域.就目前关联数据在图书情报领域的应用来看,其主要应用模式还只是将关联数据作为一种结构化数据的网络发布方式,譬如将受控词表、书目数据、科技论文元数据等发布为关联数据[4],注重的是单一数据集的网络发布,而非不同数据集间的互通互连,没能很好地利用关联数据具有的数据关联特性,更很少对关联数据之上的应用(如浏览和查询)做进一步的探索.
本研究的目的是探索将关联数据应用于数字图书馆信息资源的整合,提出一个本体与关联数据相结合的资源层次化语义整合模式,从而实现图书馆内部不同类型、不同格式的文献资源间的语义整合与互操作;实现不同知识集合中资源的集成与相互关联,使图书馆中的各种数字资源构成一个有机联系的统一整体;实现图书馆馆藏资源与外界其他资源的无缝链接,形成一个开放的资源整合体系.
2 相关研究综述
2.1 传统的图书馆信息资源整合
图书馆面对的是复杂多样的数字资源,针对不同范围、不同类型的数字资源,往往选择不同的整合方式.按照整合程度的不同,马文峰和杜小勇将数字资源整合方式分为 3个层次:数据层面的整合、信息层面的整合和知识层面的整合.在图书馆领域通常采用以下 3种方式实现数据层面的整合:
(1)采用 OAI-PMH协议从分布异构的数据源中对元数据进行收割和集成,构建数据仓库,并在此基础上提供统一的检索服务,譬如 CALIS高校学位论文数据库[5].
(2)将 Z39.50协议作为中间协议层,实现异构系统间的交换式通信和分布式异构数据源间的无缝集成,譬如 CALISOPAC(联合目录公共检索)系统[6].
(3)采用跨库检索技术为多个分布式异构数据库提供统一的用户检索界面和统一的结果整合输出界面,譬如 CNKI(中国知网)[7].
数据层面的整合解决了异构数据库中数字资源的物理异构难题,实现了统一检索,但是却无法对资源实体间存在的各种关系进行揭示和关联,这需要提升到信息层面的整合.目前图书馆领域通常采用以下两种方式实现信息层面的整合:
(1)通过超链接机制将具有相互关系的资源实体链接成一个有机统一体.譬如,CNKI通过静态超文本链接机制将来自本地不同数据库中相互引证的期刊论文、学位论文、会议论文等各类文献资源链接成一个有机信息网络.在 CALISOPAC系统中,通过在 MARC纪录里增加 856字段记录数字资源的访问地址和获取方式,使得通过该系统既能检索到印刷型图书的书目信息,又能同时获取相关电子资源或音频视频资源的地址链接,从而实现图书馆内实体馆藏和数字馆藏以及不同类型资源间的纵向集成,构成一个全方位的OPAC资源体系[8].
(2)构建信息门户.采用分类法、主题词表等传统的知识组织工具将学科领域内本地馆藏资源和外部网络资源整合、组织成一个有序的等级系统,提供统一的访问入口.譬如,中国科学院国家科学数字图书馆的"学科信息门户"[9].
数据层面和信息层面的整合方式都只能在有限范围内实现不同资源系统中各种数字资源在物理、逻辑和结构上的整合.在整合深度上,没能解决资源整合中语义异构和互操作的难题,也无法使资源在深层次的语义和概念层面进一步相互关联;整合范围主要限于图书馆内部资源,不能无限扩展到外部的相关资源.
近年来,随着语义网技术的成熟与发展,资源整合的重点从物理和语法上的整合上升到语义和知识的整合,基于本体的知识整合方式成为当前资源整合的研究热点.
2.2 基于本体的信息资源整合
早在 20世纪 90年代,国外就对基于本体的信息整合方式展开了研究.该整合方式主要是基于领域本体模型对异构数字资源进行语义标注并构建统一的(元数据)知识库,从而实现对资源的统一语义检索.
本体在其中的作用是提供对资源进行语义标注的词汇标准.德国不来梅大学的 H.Wache等人对本体在信息整合中的应用进行了调研,将基于本体的整合方法归纳为单一本体法、多本体法和混合法 3种类型[10].
作为一种新兴的知识组织工具,本体可以实现资源的语义化标注并支持语义互操作,在一定程度上解决资源语义异构的难题,从而使资源整合上升到语义和知识的层面.在本研究中,笔者采用混合法对文献资源进行了整合,采用专门元数据本体描述不同类型的文献资源,采用一个共享的核心元数据本体作为不同专门元数据本体间的公共词汇表.但是,本体的一个很大的局限性是:本体往往是领域相关的,因此基于领域本体,对某个领域或某个知识集合内的资源进行整合比较有效,对于不同领域或者不同知识集合的资源进行整合比较困难,往往需要借助本体间的映射或关联关系.譬如,基于书目元数据本体只能对图书馆内的文献资源进行整合,无法与图书馆中的其他资源(如知识组织资源、人名、地名等)相集成,更无法与外界的相关资源建立关联.关联数据的提出为解决资源的开放互联与开放整合问题提供了可能.
2.3 基于关联数据的信息资源整合
关联数据作为构建数据之网的关键技术,在资源整合和共享方面具有天然的优势.它通过发布和链接结构化数据使得分散异构的数据孤岛实现语义关联,从而使资源整合成为无缝关联、无限开放的整体,还可以通过与本体技术相结合增强资源之间的语义相关性.目前将关联数据应用于资源整合的领域主要是企业信息资源和金融数据(相关研究见文献[11]和[12]),在图书馆领域的应用实践尚不多见.
我国对关联数据应用的研究目前还处于起步阶段,主要是对关联数据在信息资源整合中的应用进行理论探讨.譬如,丁楠和潘有能提出了一个基于关联数据的图书馆信息聚合模型[13];苏春萍等人则提出了一个基于关联数据和 SOA的医学图书馆信息资源整合模型[14];游毅和成全对基于关联数据的馆藏资源聚合模式进行了理论阐述[15];郑燃等人提出了基于关联数据的图书馆、档案馆和博物馆数字资源整合模式[16].虽然上述研究者都提出了基于关联数据的资源整合模型或模式,但都仅限于理论阐述,并没有进行相应的应用实践.2011年,马费成等人提出了一个基于关联数据的网络信息资源集成框架,并依据此框架,设计和实现了以"武汉大学"为基本单位的免费网络学术资源集成实验系统[17].该研究是我国图书情报领域将关联数据应用于资源整合的极少实践研究之一,其主要是针对网络信息资源,直接采用工具将关系型数据库发布到网络上并进行关联,缺乏本体的有效支持,因此对资源间隐含关系和深层次语义关系的识别不够充分.此外,该研究也没有对资源整合的应用效果进行验证与测评.
3 图书馆信息资源语义整合框架
本研究提出了一个本体与关联数据驱动的图书馆信息资源语义整合框架,该框架具有 3层结构(见图1),旨在实现不同层次与范围的资源整合:①基于本体,实现图书馆内部不同类型、不同来源、不同时期、不同格式的文献资源异构书目元数据的整合.②基于关联数据,实现文献资源与知识组织资源等其他相关资源的整合,使图书馆内部的各种资源构成一个有机联系的统一整体.③基于关联数据,实现图书馆馆藏资源与外部相关资源的无缝链接,从而促进图书馆资源的发现和利用.
3.1 第一层:基于本体的文献资源整合
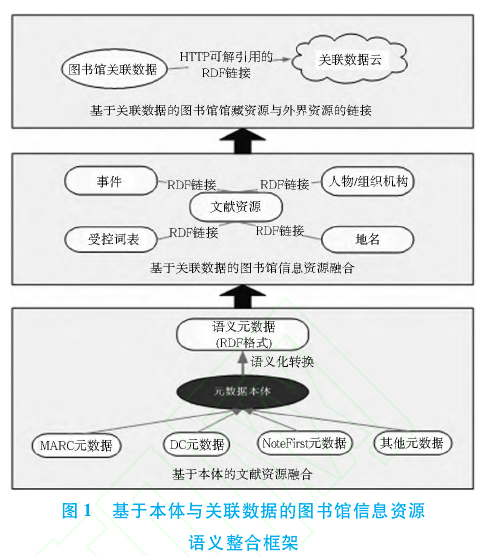
在图书馆中,针对不同类型、不同来源的文献资源通常采用不同的元数据规范进行描述,使得同一图书馆内部往往并存着多种元数据规范,不同图书馆之间使用的元数据规范更是千差万别.元数据虽然提供了数字图书馆的语义基础,但是却无法解决文献资源描述的异构性和语义性问题[18].鉴于元数据的上述局限性,需要在文献资源元数据描述的基础上构建某图 1 基于本体与关联数据的图书馆信息资源语义整合框架种机制,实现不同类型、不同格式的异构元数据间的语义互操作,这就是本体的作用.在本研究中,笔者采用混合法实现基于本体的文献资源语义整合.针对不同类型的文献资源,首先构建一个共享的核心元数据本体,该本体并不试图容纳各种元数据规范的所有元素,而是形式化地描述各种元数据规范所共有的核心元素.针对某种特定类型的文献资源,其特有的属性或相互间关系可以动态地加入到核心元数据本体中,从而对核心元数据本体进行定制化扩展,生成针对该类资源的专门元数据本体.基于专门元数据本体,可以实现某种类型文献资源的语义化描述;基于核心元数据本体,可以实现不同类型文献资源元数据之间的语义整合和互操作.
3.2 第二层:基于关联数据的图书馆信息资源整合
虽然基于元数据本体,可以在语义层面上描述文献资源的元数据信息并揭示它们之间的语义关系,但是这种相互关系仅限于文献资源集合内部的显性关系(如两个资源是整体与部分的关系),无法揭示文献资源间深层次或隐含的相互关系(如两个资源属于同一主题),更无法扩展到图书馆中的其他资源.此外,目前对于图书馆不同知识集合中资源的访问需依靠各自的 WebAPI进行,无法实现统一检索与浏览.通过在不同领域的本体间建立关联关系,可以将图书馆不同知识集合中的资源在语义层面上相互关联起来,使得图书馆中的各种资源构成一个有机联系的统一整体.通过采用关联数据的形式发布图书馆信息资源,可以使得每个资源都可通过 HTTP协议直接进行访问,并可沿着 RDF链接访问其他相关资源,自由地在不同数据集中进行切换,有效地揭示资源间的相互关系.此外,还能够实现统一检索等语义互操作.
3.3 第三层:与外界资源的链接与集成.
图书馆的关联数据还可进一步与其他图书馆的关联数据或外界的关联数据(如 DBPedia[19])相关联,成为整个关联数据云的一部分,更容易被读者所发现和使用.基于本体与关联数据的图书馆信息资源语义整合方式不仅是致力于深度优化图书馆的资源,更是试图将图书馆资源纳入到不断扩大的整个数据之网中,在为整个 Web空间贡献高质量的信息资源的同时,也使图书馆资源的利用率最大化.
4 图书馆信息资源整合的实施
本节将以实际的图书馆数据为例,基于上文所提出的基于本体与关联数据的图书馆信息资源整合框架(见图 1),构建一个演示性的图书馆信息资源整合系统,实现图书馆中以文献资源为核心的不同类型信息资源的语义整合.
4.1 元数据本体的构建.
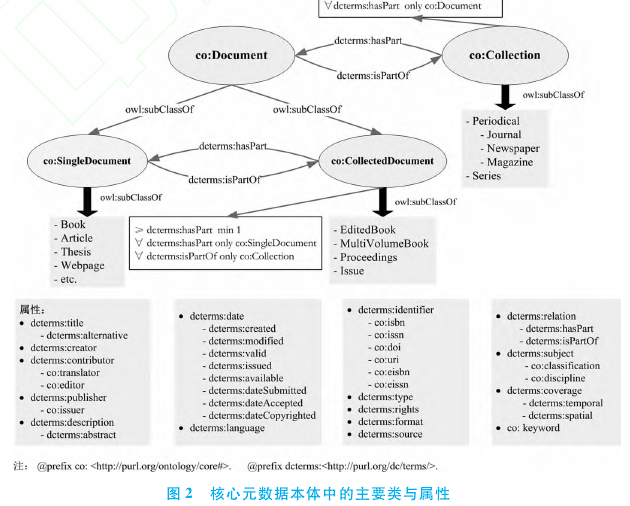
为了实现文献资源的语义化描述,首先需要构建一个元数据本体.在本研究中,笔者采用 OWL本体语言基于 DC/DCTERMS元数据标准构建了一个通用的核心元数据本体(见图 2),其目的是对文献资源的核心属性以及文献资源之间的主要关系进行精确的语义化描述[4].核心元数据本体是各种类型文献资源共享的一个通用本体.特定类型的文献资源,除了通用属性外往往还具有各自特殊的属性,是核心元数据本体中所没有容纳的,譬如,学位论文的学位和学位授予时间.此时通过为核心元数据本体定义新属性(如 cox:degree等)或者为现有属性添加子属性(如 cox:dateConferred等)对其进行扩展,生成针对某种特定类型文献资源(如学位论文)的专门元数据本体.基于专门元数据本体,可以将相应类型文献资源的普通元数据转换为以RDF格式表示的语义元数据.
4.2 语义元数据的生成
在本研究中,笔者以国家图书馆书目数据库、万方数据库和 C-DBLP数据库作为数据源,以普通图书、期刊论文、会议论文和学位论文 4种文献为例,基于元数据本体,实现文献资源元数据的语义化转换,生成语义元数据.为了使样本数据内部具有较强的潜在关联性,下载的文献资源记录主要集中在作者单位---"南京大学信息管理系(学院)".所下载的文献资源的元数据格式有 3种:来自国家图书馆书目数据库的 CNMARC格式、来自万方数据库的 NoteFirst格式 和来自 C-DBLP的 BibTEX格式.通过在元数据本体与元数据规范间建立映射关系,笔者采用 JAVA语言实现了元数据记录从原始格式到 RDF格式的语义化转换,生成上述文献资源的语义元数据.在这一阶段,对文献资源的描述基本上全部采用数据类型属性,即属性值为文本字符串.
通过基于本体的元数据语义化转换,不同格式、不同类型的元数据转换成为了具有统一格式的 RDF语义元数据.虽然不同类型文献资源的 RDF元数据中的属性不尽相同,但是因为它们共享同一个核心元数据本体,因此具有相同的语义共享部分,这使得实现不同类型文献资源元数据之间的语义互操作成为可能.
4.3 受控词表的语义化描述
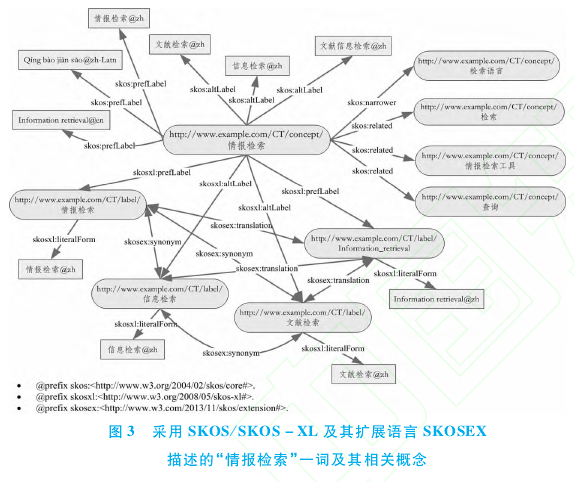
在本研究中,笔者采用 SKOS和 SKOS-XL语言对上述文献资源中所涉及的受控词汇进行语义化描述.由于在 SKOS数据模型中定义的词汇有限,SKOS标准语言有时无法描述中文词表中所具有的一些特殊概念、属性和关系.为了实现中文词表的无损语义化转换,笔者对 SKOS标准语言进行了定制化扩展,扩展语言命名为 SKOSEX.图 3为采用 SKOS/SKOS-XL及其扩展语言 SKOSEX描述的《汉语主题词表》中"情报检索"一词及其相关概念的 RDF图.在实际应用中,采用 RDF/XML序列化格式进行表示:
4.4 其他资源的语义化描述.
除受控词汇外,文献资源的描述中还涉及大量其他相关资源,如人物、组织机构、会议、地名等.对于这些资源,主要利用现有本体或者现有本体的扩展进行描述,形成相应的数据集.
对于人物和组织机构,基于目前应用最广泛的描述人及其行为的 FOAF本体进行描述[20],并对该本体进行必要的扩展(扩展部分为 foafx).对于样本文献资源中所涉及的人物和组织机构,笔者从万方数据库的科技专家信息库与学术机构库以及 C-DBLP数据库中下载相关的描述记录,然后基于 FOAF本体自动转换为 RDF格式的语义化描述.对于万方和 C-DBLP数据库中没有的人物和组织机构记录,则从机构主页、个人主页、维基百科中手工提取并进行语义化描述.对于会议等事件,基于伦敦大学玛丽皇后学院数字音乐中心于2004年开发的 Event本体进行描述[21],并对该本体进行必要的扩展(扩展部分为 eventx).对于时间概念,同样采用该中心构建的 TimeLine本体进行描述[22].
对于地名,笔者直接从 GeoNames地理数据库中获取其描述.GeoNames地理数据库包含了约 620万个地名,并已发布为关联数据[23].
4.5 不同数据集间的语义关联
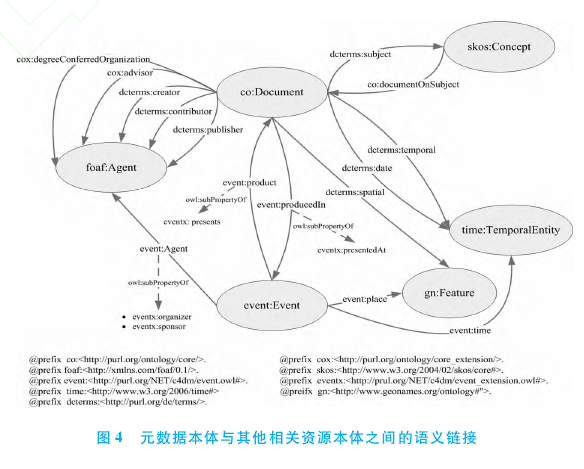
为了明确描述文献资源与相关资源之间的语义相关关系,笔者在元数据 本 体、FOAF本 体、Event本 体、GeoNames本体和 SKOS数据模型间建立了 RDF语义链接(见图 3),形式化地描 述资 源 间 各种 关系 的 类 型 和语义.
在上一阶段生成的 SKOS/RDF数据中,数据之间的关联关系隐含地存在于数据类型属性中,在该阶段需要将这种隐性的语义关系转换为显性的 RDF语义链接,即采用 URI地址替换原有的文本字符串属性值,将数据类型属性转换为对象属性.通过图 4中设定的 RDF链接的值域,笔者定位相应的数据集,然后采用字符串模糊匹配的方法自动从该数据集中查找与原有属性值相匹配的实体,用其 URI地址替换原有的文本字符串值,从而实现数字图书馆中文献资源、人物、组织机构、会议、地点、受控词汇之间的相互关联,构成图书馆的关联数据.
4.6 关联数据的发布
在本研究中,笔者直接利用 RDF存储器发布关联数据,发 布 方 式 采 用 "JenaTDB + JenaFuseki+Pubby"的组合.整个发布系统运行在 Windows环境下,采用 ApacheHTTPServer(2.0.64)作为 Web服务器,Tomcat(7.0.25)作为 Servlet容器以支持 Fuseki和Pubby的运行.Fuseki是由 HP实验室开发的开源语义网工具包 Jena中所带的一个 SPARQL服务器,它内置有 TDB模式的三元组存储器,支持 RDF数据的持久化存储,并为 RDF数据提供一个独立的 SPARQL查询终端.但是通过该终端获得的 SPARQL查询结果中的URI地址是无法被 HTTP协议解引用的,因此无法进行进一步访问和浏览,不能体现出数据的关联性.
Pubby(0.3.3)是由柏林自由大学开发的一个关联数据前端,通过将其置于 Fuseki前端,并配置一个将原有URI地址转换成可解引用的 URI地址的映射,可以将不可解引用的 URI地址转换为能够被 HTTP协议解引用的,从而实现 SPARQL查询结果的关联数据化访问.
4.7 关联数据的检索与访问
图书馆关联数据的检索需通过 SPARQL查询来实现,Fuseki提供了专门的 SPARQL查询界面,但是SPARQL查询的构建比较复杂,对于普通用户来说难度很大.因此,笔者采 PHP语言开发了字段检索界面,用户可在选定的检索字段(如作者、主题、题名)中直接输入检索词进行检索,见图 5.在后台,预先定义了一系列 SPARQL查询模板,系统将用户输入的检索词自动填充到相应模板的相应槽中,生成完整的SPARQL查询并发送给 Fuseki,该 SPARQL查询终端从存储在 TDB中的 RDF数据集中提取出答案并按照用户指定的格式返回给用户.这种检索方式的界面与CALISOPAC和 CNKI的检索界面相类似,不同点在于:返回的检索结果均是可以点击访问的,用户可以沿着 RDF链接继续访问其他相关资源,如文献→作者→作者出生地,文献→主题→相关概念→文献.
5 实验测评
为了证明基于本体与关联数据的资源整合方式的图 5 图书馆关联数据的字段检索界面有效性,本研究将其与传统的资源整合方式进行对比测试,选取 CALISOPAC(联合目录公共检索)系统和CNKI(中国知网)作为参照对象.CALISOPAC是基于Z39.50协议整合信息资源的一个典范,CNKI是采用跨库检索方式进行资源整合的一个知识整合平台.笔者以两个具体的检索需求为例,对不同的资源整合方式进行对比,从而发现它们各自的优缺点.

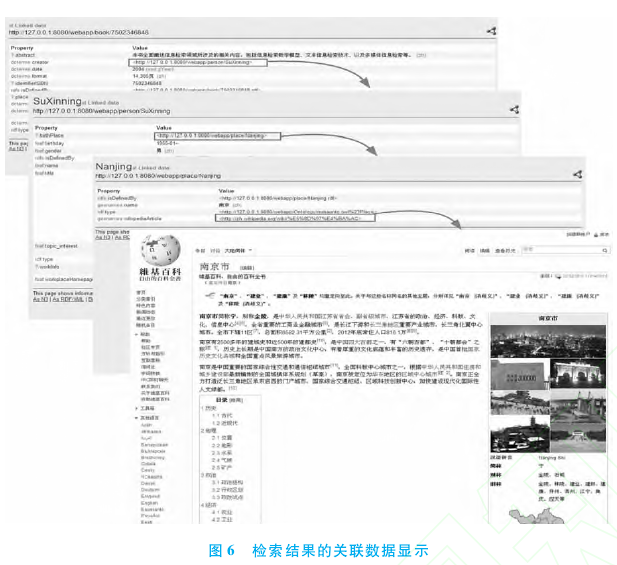
5.1 实验一:查询作者为"苏新宁"的所有文献资源5.1.1 基于本体与关联数据的资源整合演示系统在该系统中,能够采用统一的检索界面实现对不同类型文献资源的统一检索,所有检中文献的 URI地址都是可访问的,点击可查看每个文献资源详细的书目数据.文献资源所涉及的其他相关信息也是可访问的,如作者信息、作者出生地信息等.从地名信息中还可进一步链接到维基百科中的相应页面,整个过程见图6.由此可见,采用关联数据,除了能够实现对不同类型文献资源的统一检索,还能够实现不同类型资源之间(即文献资源、人物信息、地名信息之间)以及图书馆内部数据与外部数据之间的无缝链接与跳转.
5.1.2 CALISOPAC CALISOPAC系统能够对分布在不同成员馆的文献资源进行整合并实现统一检索,但是这种整合仅局限于图书馆的书目数据,无法对大量的学术论文资源进行整合和统一检索.它虽然能够对"图书 -丛书"这种相关关系的文献资源进行集成和链接,但是这种集成无法扩展到同一主题、相互引用等更复杂关系的相关文献资源,更无法链接到其他类型的资源.
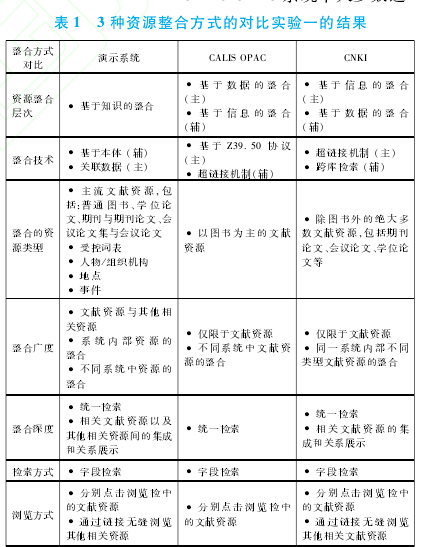
5.1.3 CNKI CNKI提供了除图书外主要类型文献资源数据库的整合和跨库检索.该系统的一大特色是提供对多种相关文献资源的集成和链接,如被引用的文献、内容相近的文献、被读者同时关注的文献、同一机构作者的文献、同一关键词的文献,从深层次上揭示了文献资源之间的相互关系.但是这种集成和链接同样局限于文献资源内部,无法提供对其他类型相关资源的支持.这 3种资源整合方式对比实验一的结果总结见表 1.
5.2 实验二:查询主题为"信息检索"的所有文献资源5.2.1 基于本体与关联数据的资源整合演示系统根据《汉语主题词表》,"信息检索"是一非叙词,所对应的规范叙词是"情报检索".该叙词共对应 3个非叙词,即"文献检索"、"文献信息检索"和"信息检索",见图 3.当查询主题为"信息检索"的文献时,用户希望获取的是与"信息检索"这一概念相匹配的所有记录,而非仅仅是与"信息检索"这个字符串相匹配的纪录.但是对于大多数用户来说,很难知晓表示同一概念的所有同义词汇并将它们分别作为检索词进行多次检索以获取所有相关记录,因此不可避免地造成大量漏检.在基于本体与关联数据的资源整合方式中,文献资源所涉及的受控词汇均采用 SKOS语言进行语义化描述,该描述以概念为核心并明确揭示词汇间的义关系,同义词只是同一概念的不同标签.不论文献资源的原始元数据记录采用何种词汇进行主题标注(如"情报检索"或"信息检索"),在 RDF语义元数据中均已转换为 URI标识符表示的 SKOS概念.因此,在检 索时,采 用 图 7所 示 的SPARQL查询语句,可一次检索到在原始元数据记录中以不同同义词汇进行主题或关键词标注的所有文献:此外,用户还可以基于受控词表对查询词进行精炼和扩展,譬如将"信息检索"精炼为其下位词"检索语言",或者扩展为相关词"检索"、"查询"等,从而提高检索性能.
5.2.2 CALIS OPAC 在CALISOPAC系统中大多数还是使用叙词"情报检索"对文献进行标注,使用非叙词的情况比较少.在使用该系统检索时,系统没有对检索词的选择提供任何提示和帮助,用户需对《汉语主题词表》比较熟悉,尤其需要了解词汇之间的同义关系,才能尽可能选用所有同义词进行多次检索,较为全面地检中所有相关记录,否则将会遗漏大量有用的结果.

5.2.3 CNKI CNKI的"主题检索"是同时在"篇名"、"关键词"和"摘要"3个字段中进行字符串匹配检索,其实质上仍是一种自由词检索,而非采用规范主题词进行标引和检索的真正主题检索.因此,在 CNKI中用户需要采用同义词汇进行多次检索才不至于漏检大量结果.CNKI同时也提供了"相关搜索"功能,系统自动列出与当前检索词相关的一系列词汇,用户可以利用这些相关词汇检出更多的结果或者进一步精炼检索结果.但是这些相关词汇范围较广,包括语义相关词汇、同义词汇、上位词汇、下位词汇等,用户很难从中识别出哪些是同义的词汇.
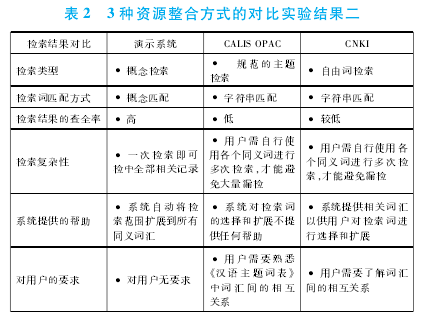
这 3种资源整合方式对比实验二的结果如表 2所示:
通过上述两个实验可以看出,相对于传统的资源整合方式,基于本体与关联数据的资源整合方式具有 3个明显特点:①能够对各种类型的资源实现统一检索,而其他方式只能对一定范围内的文献资源实现统一的检索,资源整合的广度低于前者;②能够在检索结果中提供对各种相关资源的无缝链接,深度揭示资源间的语义关系,有助于资源的进一步发现与利用,而其他方式或者对检索结果不提供进一步的相关资源链接或者仅在文献资源集合内部提供链接,资源整合的深度低于前者;③基于受控词表能够为用户提供具有语义功能的概念检索,在检索中自动实现对检索词的概念匹配,在扩大检索范围的同时又保持了检索的精度,而其他方式只能实现机械的字符串检索,查全率和查准率都低于前者.但是这种检索方式对受控词表的依赖性很大,对于词表中没有的词汇,将无法实现上述概念检索.
6 结论与展望
针对目前图书馆领域普遍存在的资源封闭异构难题,本研究提出了一个基于本体与关联数据的图书馆信息资源语义整合框架,并基于该框架构建了一个资源整合演示系统,使图书馆不同知识集合中的资源构成一个有机联系的统一整体,真正实现资源在知识层面的整合.
为了说明基于本体与关联数据的图书馆资源整合方式的有效性,本研究将其与 CALISOPAC系统和CNKI这两种采用传统资源整合方式的信息系统进行了实验对比.结果证明,基于本体与关联数据的资源整合方式在资源整合的深度和广度上都优于传统的整合方式,而且在检索的智能性和查全率上也具有相当大的优越性.利用本体与关联数据进行资源整合,不但解决了当前图书馆资源异构的难题,还实现了图书馆资源与外界信息资源间的无缝链接,使图书馆资源由封闭走向了开放,成为开放的数据网络的一部分.
以关联数据的形式发布和整合图书馆数字资源,不仅强化了图书馆馆藏资源间的语义粘合度,同时为外界发现和访问图书馆内部资源提供了更大的可能性,大大提高了图书馆信息资源的利用率.然而,这一资源整合方式也存在着诸多问题,譬如,数据源一旦发生变动会引起链接失效;目前沿着链接的访问只能前进而无法后退;有些文献资源采用自由关键词标引,但目前只能采用手工方式将其与受控词汇进行映射,如何实现大数据量的自动映射等,这些问题都需在后续研究中予以关注和解决.
在本研究中,目前还只是把单一学科领域的 4种文献资源以及相关资源进行了整合,没能将更多的信息资源纳入到整合范围中.在后续研究中,笔者将把整合范围扩展至更多类型的文献资源和其他相关资源,尤其是进一步发挥关联数据无缝链接的优势,将图书馆资源与更多的外部资源相关联.此外,笔者还将开发界面友好的自然语言查询界面,支持用户以自然语言的方式精确地表达信息查询请求,方便用户的使用.
参考文献:
[1]杜小勇.数字资源整合:理论、方法与应用[M].北京:北京图书馆出版社,2007.
[2]ArensY,CheeC,HsuC,etal.Retrievingandintegratingdatafrommultipleinformationsources[J].InternationalJournalofIntelligentandCooperativeInformationSystems,1993,2(2):127-158.
[3]Berners?LeeT.PersonalnotesondesignissuesfortheWorldWideWeb[EB/OL].[2013-12-30].http://www.w3.org/DesignIssues/LinkedData.html.
[4]欧石燕.面向关联数据的语义数字图书馆资源描述与组织框架设计与实现[J].中国图书馆学报,2012,38(6):58-71.
[5]赵阳,姜爱蓉.基于 OAI的"CALIS高校学位论文全文数据库"建设[J].上海交通大学学报,2003(S1):234-238.
[6]张俊娥.CALISZ39.50联机编目客户端功能特色和应用[J].现代图书情报技术,2002(5):21-24.
[7]中国知网(CNKI)[EB/OL].[2013-12-30].
[8]CALIS联合目录公共检索系统[EB/OL].[2013-12-30].
[9]中国科学院国家科学图书馆化学学科信息门户[EB/OL].
[10]WacheH,VoegeleT,VisserU,etal.Ontology?basedintegrationofinformation?Asurveyofexistingapproaches[C/OL]//Gómez?
PérezA,GruningerM,StuckenschmidtH,etal.ProceedingsoftheIJCAI-01Workshop:OntologiesandInformationsharing.
CEUR-WS.org,2001:108-118.[2013-12-30].
[11] MihindukulasooriyaN,CastroR,GutiérrezM.Linkeddataplatformasanovelapproachforenterpriseapplicationintegration[C/OL]//HartigO,SequedaJ,HoganA,etal.Proceedingsofthe4thInternationalWorkshoponConsumingLinkedData.CEUR-WS.org,2013.[2013-12-30
[12]O'RiainS,HarthA,CurryE.Linkeddatadriveninformationsystemsasanenablerforintegratingfinancialdata[C]//YapA.Information Systems for GlobalFinancialMarkets: EmergingDevelopmentsandEffects.Hershey,PA:IGIGlobal,2012:239-270.
[13]丁楠,潘有能.基于关联数据的图书馆信息聚合研究[J].图书与情报,2011(6):50-53.
[14]苏春萍,张鲁,伍静,等.基于关联数据和 SOA的医学图书馆信息资源整合模型设计[J].中华医学图书情报杂志,2013,22(3):6-9.
[15]游毅,成全.试论基于关联数据的馆藏资源聚合模式[J].情报理论与实践,2013,36(1):109-114.
[16]郑燃,唐义,戴艳清.基于关联数据的图书馆、档案馆和博物馆数字资源整合研究[J].图书与情报,2012(1):71-76.
[17]马费成,赵红斌,万燕玲,等.基于关联数据的网络信息资源集成[J].情报杂志,2011,30(2):167-170.
[18]刘炜,李大玲,夏翠娟.元数据与知识本体[J].图书馆杂志,2004,23(6):50-54.
[19]DBpedia[EB/OL].[2013-12-30].
[20]BrickleyD,MillerL.FOAFVocabularySpecification0.98[EB/OL].[2013-12-30].
[21]RaimondY,AbdallahS.Theeventontology[EB/OL].[2013-09-28].
[22]RaimondY,AbdallahS.Thetimelineontology[EB/OL].[2013-12-30].
[23]GeoNamesontology[EB/OL].[2013-12-30].





