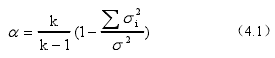第 4 章 调查研究设计与数据统计分析
4.1 调查研究综合设计
4.1.1 调查对象与研究环境
为了进一步验证理论模型中提出的各个研究假设,本研究采用发放调查问卷的方式来收集数据,调查对象为吉林大学在校大学生。在调查对象的选取上主要遵循以下原则: ○1 取样的代表性。大学生是进行学习活动最活跃的群体,同时又在时间和移动设备的占有率上占有绝对优势,可以说大学生群体是移动学习潮流的引领者。○2 样本的可获得性,样本是否能够容易获得是关于调查研究是否顺利开展的基本前提,本研究以在校大学生为调查对象充分考虑到了研究的成本和可行性。○3 抽样的随机化。在抽样方法上主要采用了分层随机抽样,吉林大学是一所学科门类齐全的综合性大学,并且在校区分布上具有学科特色,其六个校区在学科发展上分别主要侧重人文社科类、工学类、医学类、农学类、地学类和电子通信类,为了尽可能的避免因为抽样带来的误差,本研究结合现实条件以学科类别为分层标准,分别进入各个校区的图书馆和餐厅进行纸质问卷的发放。
4.1.2 实证分析方法
(1)SPSS 统计分析方法
本研究中使用 SPSS22.0 进行描述性统计、问卷内部一致性检验与因子分析。
其中描述性统计主要用以对被调查者的性别、学历、专业和移动学习的使用频率等个人基本信息描述;问卷内部一致性检验用以分析问卷的信度,而探索性因子分析主要用以探索变量因子结构、检验模型的效度。
(2)结构方程模型分析法
结构方程模型(Structural Equation Model)是社会科学中常用的数据分析技术,主要进行多变量的统计。在 Amos 中绘制的标准结构方程模型如图 4-1 所示。
结构方程模型中包含有观察变量、潜在变量以及干扰/误差变量,其中观察变量是可以直接测量的变量,而潜在变量是观察变量所反映的某种构念,不能直接测量1.完整的结构方程模型包括测量模型和结构模型,测量模型表示的是观察变量与潜在变量之间的关系,结构模型表示的是潜在变量之间的关系。Bollen 与Long 认为,结构方程模型是计量经济学、社会计量与心理计量发展过程的合成物1.其广受欢迎的原因在于,相比较于传统的分析方法具有以下优势:○1 理论先验性,其理论假设必须建立在一定的理论之上。○2 同时处理多个因变量,克服了线性回归中只能处理一个因变量的不足。○3 允许自变量和因变量同时还有测量误差,心理学等社会科学领域涉及的态度、行为等等变量不可避免的会存在误差而传统的统计分析无法处理这些误差。○4 同时处理测量与分析问题,有利于处理社会科学中不能直接观察的变量之间复杂的关系○5 包含多种统计技术,整合了相关分析、回归分析、因子分析、以及 T 检验和方差分析等。
鉴于本研究中涉及的信息焦虑是一个难以直接观测的心理学变量,涉及个体的心理体验和主观感受,结构方程模型在统计分析上的优势将有利于保证本研究的严谨性、科学性。
4.2 调查问卷设计
4.2.1 问卷变量的概念化与操作化
在教育研究活动中,变量的概念化与操作化是定量研究的一项重要环节,它能将模糊的、不具体的概念转化为我们能够理解和操作的术语。概念化能使各种模糊的印象变得明晰,而且能对各种观察和测量进行梳理,而操作化是概念化的延伸,它明确了用来测量的研究变量之属性,有利于研究过程的开展2.只有通过概念化和操作化,那些具有思辨色彩的理论知识才能成为检验的具体事实。
一般而言,将一个抽象术语转化为可测量的具体指标需要经过图4-2所示的流程:在上文中理论模型的假设中已经对各因素构念的进行解析并形成了相应的名义定义,本节参照已有测量量表的基础上对各相关变量的概念化与操作化过程如下:
(1)可用性
国际标准化组织(ISO)针对产品开发过程中质量属性的标准 ISO/IEC9126-1将可用性的内涵划分为可理解、可操作、可学习和吸引力1.结合 Flavian 等人对网站可用性的基本要素规划2以及本研究中移动学习的特点,确定移动学习中可用性的操作化测量题项如表 4-1 所示:
(2)沉浸体验
关于沉浸体验的测量,国外最广为采用的是 Jackson 和 Marsh 编制的沉浸体验测量量表(Flow State Scale1996)3,结合国内学者张红霞4关于青少年网络游戏中沉浸体验的测量方式,本研究确定移动学习中沉浸体验的操作化测量题项如表 4-2 所示:
(3)信息污染
信息污染过程中常常伴随着虚假信息、冗余信息和老化信息对人们日常生活产生的不良影响。国内学者夏日1构建的信息污染指标体系分别从“实物型”、“文献型”、“网络型”、“电子型”的侧重点设置指标,本文主要参考其中“网络型信息污染”的测量方式,此外还借鉴了翟婷2对于信息污染表现形式的研究,形成了移动学习中信息污染的操作化测量题项如表4-3所示:
(4)信息超载
学界对信息超载的测量方式并没有代表性的研究结果,但是信息超载与认知负荷理论有着密切的关系,基于sweller对于认知过程的解释,信息加工需要的资源超过了认知资源总量时,认知超载就会产生。本文借鉴Shadiev3等人对于移动学习中认知负荷水平的测量结合国内对于认知负荷测量以及在多媒体学习中应用的探索4,编制了移动学习中信息超载的操作化测量题项如表4-4所示:
(5)网络自我效能
本研究中对于网络自我效能感的操作化定义主要参考了谢幼如1编制的大学生网络学习自我效能感量表,并结合移动学习在设备、学习方式上的特点,进行合理的修订,最终形成的操作化测量题项如表4-5所示:
(6)移动设备依赖
本研究中对移动设备依赖的操作化定义主要参考了刘雪的硕士毕业论文设计的青年人手机依赖问卷2以及Leung设计的手机依赖指数量表3(Mobile phoneaddiction index,MPAI),最终形成的操作化测量题项如表4-6所示:
(7)信息素养
本研究中对移动设备依赖的操作化定义主要参考了吴晓伟和娜日等设计的大学生网络信息素养量表1,结合移动学习可能涉及到的学习信息处理活动进行修订,形成的操作化测量题项如表4-7所示:
(8)信息焦虑倾向
有关信息焦虑的概念化定义,前文已经系统表述,在此不再赘述。在信息焦虑倾向的操作化定义上,本研究主要参考的是王畅2所编制的信息焦虑量表,鉴于其对信息焦虑的测量主要侧重于信息的检索过程,笔者还参照信息焦虑的最早提出者Wurman对于信息焦虑的基本特点的界定3,形成的操作化测量题项如表4-8所示:
4.2.2 问卷结构设计
在通过概念化和操作化过程确定了各个变量的具体测量题项之后,本研究遵循问卷设计的一般原则1,设计了移动学习信息焦虑的影响因素调查问卷。力图做到措辞规范、问题清晰明确、内容简单详尽、题项设置避免诱导性。问卷整体结构设计分为以下三个部分:第一,指导语部分。指导语主要说明问卷调查的目的与意义以及作答要求,并声明关于匿名的保证以达到消除被调查者的顾虑、引导其客观真实作答的目的。需要特别强调的是,考虑到很多在校大学生虽然可能每天都在进行移动学习但是对于这个概念并未真正了解,本调查问卷在指导语部分对移动学习进行了明确的界定并举出了日常生活中常见的移动学习例子,来帮助被调查者加强对概念的理解。第二,个人基本信息部分。旨在从性别、学历、专业以及移动学习频率等方面对被调查者进行考察。第三,测量量表部分。以李克特(Likert)五级量表的方式,对理论模型中关于移动学习中信息焦虑的 7 个影响因素以及信息焦虑倾向分别设置测量题项,每个题项的选项依次按照 “非常不同意”、“不同意”、“一般”、“同意”、“非常同意”的顺序赋予为 1 分、2 分、3 分、4分、5 分的分值。
另外,考虑到过多的测量题目容易引起被调查者的厌烦和疲倦,失去填写耐心进而影响到问卷的信度与效度,本问卷在将量表的题项控制在 30 题左右;为避免被调查者按照固定的倾向作答而产生反应心向,问卷不同层面的影响因素涉及的题项适当打乱并设立反向计分题。
4.3 问卷的初测与项目分析
4.3.1 初测问卷的调查对象与发放
初测问卷的发放主要选择在吉林大学中心校区图书馆,共发放问卷 60 份并全部当场收回。剔除答题不完整、选项大面积完全相同、前后反向问题答题自相矛盾等不合格的问卷,共获得有效分卷 55 份,问卷有效率为 91.6%.
4.3.2 初测问卷的项目分析过程
1.信度分析
一般而言,问卷的项目分析过程主要包括极端组比较、题项与总分的相关性和同质性检验。其中极端组比较主要采用将量表总分按照临界分数分成高低组并通过 t 检验检验出高低组在每个题项上差异的方法,题项与总分的相关性检验主要通过 pearson 相关来检验各个题项的得分与总分的相关程度,同质性检验主要指信度检验和共同性与因素负荷的量的测量。但是由于本调查问卷的所包含的因素构念是两种以上不同的面向,这些面向的分数加总并没有实际意义。如问卷在移动学习信息焦虑影响因素的个体层面上设立了网络自我效能、信息素养和移动设备依赖三个子维度,将这些维度所涉及的题项得分相加所得的总分并不能具有什么意义。因此本问卷的项目分析过程主要采用信度检验分析进行项目基本性质和内部一致性检验。
需要特别说明的是,根据吴明隆对于包含两种以上构念的量表进行内部一致性分析的建议,此类量表的内部一致性分析要以各不同的因素构念分别进行计算,而不能估计整份量表的信度系数。内部信度的 Cronbach's Alpha 系数计算公式为:
式(4.1)中的 k 为项目数,s2i为每个题项的得分方差,s?为所有题项总得分的方差。α系数的范围在 0~1 之间,对于其数值所反映的信度水平社会科学领域有不同的界定标准,吴明隆在总结国内外学者关于信度系数可接受范围观点的基础上,总结了出了量表的内部一致性信度系数指标判断原则如表 4-9 所示1,检验结果显示,问卷的整体 Cronbach's Alpha 值为 0.755,问卷中各变量的信度分析结果如 4-10 所示。
从上表中可以看出各个变量的 Cronbach'sAlpha 值范围在 0.659~0.872 之间,部分变量的整体效度一般,需要对其中各个题项删除后各个维度的α系数改变程度进行考察,如果某一题项删除后其所在的维度整体α系数会提升而且其对应的校正的项总相关性小于 0.4,则表示该题项与其他题项的同质性不高,需要将其删除。根据上述标准分析各个题项与其所在维度的α系数的关系可以发现,题项FE2、IO1、SE4 和 IL1 不符合上述指标,可以考虑予以删除。
2.项目基本性质分析
为了进一步分析项目的基本性质,需要对量表各个题项的得分进行平均值、偏态以及标准差分析。平均值用户衡量题项的极端倾向,如果项目的平均值过大或者过小则表明该题项在作答上有明显的极端倾向;偏态系数用来衡量偏斜的程度,绝对值越大的偏态系数则表示偏斜程度越大,标准差则用来衡量个体在该项目上的差异程度,标准差越小得分分布范围越小则表明项目鉴别能力越差。统计结果见表 4-11.
从表中可以看出,各题项得分的平均值没有接近 1 或者 5 的,表示题项作答情况没有非常极端倾向;从标准差上看,本量表中没有出现鉴别能力未达标准的题项(一般小于 0.5 的题项应该考虑删除);从偏态系数上看,发现题项 IL1 的绝对值接近于 1.综合考虑以上分析过程本研究决定删除题项 FE2、IO1、SE4和 IL1 形成正式量表。
4.4 正式调查与数据分析
正式的调查采用分层抽样法,分别在吉林大学各个校区的学生餐厅随机发放问卷 60 份,六个校区共计发放 360 份。收回问卷 351 份其中有效问卷 328 份,有效问卷率为 91.9%.根据 Bentler 和 Chou1的观点,样本容量的大小应遵循的一个基本原则就是,保证问卷题项与受访者的比例最好保持在 1:5 以上,本问卷经过修订后剩余题项 26 个,被调查者与题项的比例远远超过了该比例。
4.4.1 描述性统计
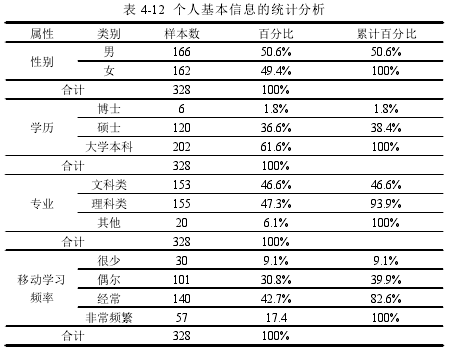
描述性统计旨在对被调查者的个人基本信息的分布情况进行统计和考察,从性别上看本研究中被调查者的男女比例接近,符合随机抽样的特点;从学历层次上看,被调查者主要为大学本科生,博士研究生较少,样本的学历层次分布符合实际情况;从被调查者所学专业上看,文科大类和理科大类的人数相当;从移动学习使用频率上看,大多数人都是经常进行移动学习的,这一数据充分反映了移动学习在大学生群体中的受欢迎程度。
4.4.2 信度分析
正式调查结束之后,需要对修订的正式问卷进行信度的再次检验,问卷的整体 Cronbach's Alpha 值为 0.853,说明问卷的整体信度很可信,分别对各个变量的进行信度检验结果如表 4-13 所示,从表中可以看出各变量的信度系数范围在0.711~0.893 之间,说明问卷在各个变量上的信度也比较良好。
4.4.3 效度分析
(1)探索性因子分析
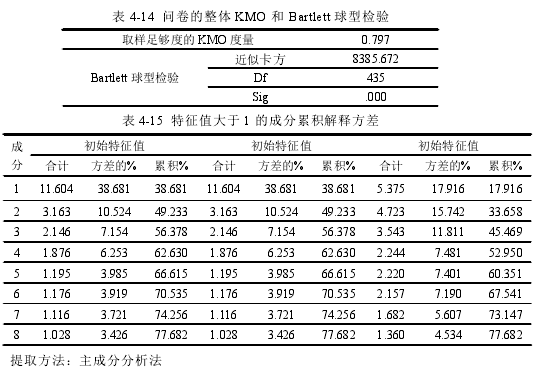
在使用 SPSS22.0 进行探索性因子分析之前,需要先以 KMO 和 Bartlett 球形检验来判断是否达到因子分析的标准。KMO 是用于比较变量间简单相关和偏相关的系数,范围在 0~1 之间,越接近 1 说明变量间的共同因子越多,越适合做因子分析。一般认为 KMO<0.5 时不适合做因子分析,其值至少应该在 0.6 以上。
本文采用主成分分析的方法,抽取特征值大于 1 的因子,对问卷各个潜在变量进行效度分析,结果如表 4-14 与 4-15 所示:
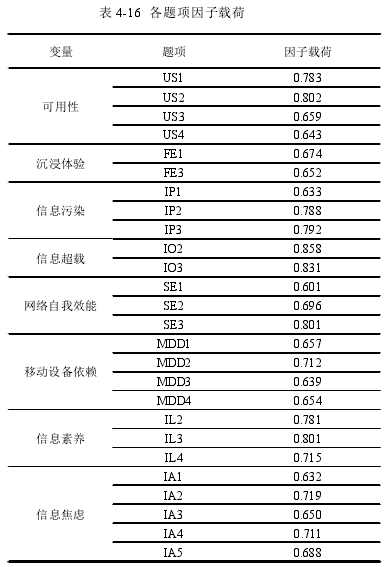
问卷的整体 KMO 值达到 0.797,Bartlett 球型检验达到显着水平,提取到特征值大于 1 的成分有 8 个,并且累积解释方差为 77.682%,说明问卷整体的构建效度良好,适合做因子分析。经过转轴之后发现各潜在变量的题项与提取的主成分基本符合。各题项的因子载荷见表 4-16因子载荷反映的是某一题项与问卷的关联强度,因子载荷越大,表示关联性越强。在因子载荷的衡量标准上,研究者需要考虑到样本容量的大小,较小的样本容量其因子载荷选取标准要较高,相反,如果样本容量较大其因子载荷的衡量标准可以较低。一般认为因子载荷的选取标准最好是在 0.4 以上。由表 4-16 可知,各题项的因子载荷在 0.6 以上,说明各题项与问卷的关联性较好。
(2)验证性因子分析
本文通过 AMOS22.0 建构了各潜在变量的测量模型并进行验证性因子分析。
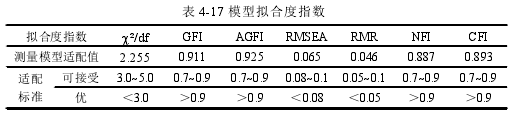
在模型的估计上选择了常用的极大似然法,模型输出结果如图 4-3 所示,观察模型中各个观察变量的标准化路径系数可以发现,其数值都超过了 0.5,表示各个测量变量对于潜在变量的测量效果较好。此外,根据结构方程模型拟合度的评价标准,将本模型中的适配指数进行比对,结果如表 4-17 所示。发现其基本达到了良好拟合的标准。说明本问卷具有良好的构建效度。