
1引言
语音是人们交流的主要方式,语音信号不仅传递语义信息,而且通过高低强弱、抑扬顿挫来表达说话人丰富的情感信息。当说话人愤怒时,音调升高、语速加快;悲伤时,语调低沉、语速缓慢。听者可以通过语音信号感受说话人的情感变化。如何使计算机从语音信号中自动识别出说话人的情感状态及其变化,是实现自然人机交互界面的关键前提,具有很大的研究价值和应用价值。例如:可以用于对电话服务中心用户紧急程度的分拣,从而提高服务质量;用于对汽车驾驶者的精神状态进行监控,从而在驾驶员疲劳时进行提醒,避免交通事故的发生;用于对抑郁症患者的情感变化进行跟踪,从而作为疾病诊断和治疗的依据等。计算机的语音情感识别能力是计算机情感智能的重要组成部分。目前,国内外学者在这方面进行了大量的研究。
对语音情感相关特征的有效提取是该领域内十分重要的研究课题。由于语音情感本身自有的复杂性,还没有占据重要地位的有效情感特征被提出[1].寻找合适的情感识别算法,也是本领域研究者一直以来努力的目标。
Origlia等人[2]使用基频和能量相关特征的最大值、最小值、均值、标准差组成了一个31维的韵律特征集,在一个包含有意大利语、法语、英语、德语在内的多语种情感语料库上取得了接近60%的识别率。
Sepp?nen等人[3]使用基频、能量、时长相关的43维全局韵律特征进行芬兰语的情感识别,在说话人不相关的情形下取得了60%的识别率。
Li等人[4]提取了频率微扰和振幅微扰并将其作为声音质量参数对SU-SAS数据库中的语料数据进行了说话人不相关的情感识别,HMM(Hidden Markov Model)被用作识别器,同仅使用Mel频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)的基线性能65.5%的识别率相比,MFCC和频率微扰的特征组合可以得到68.1%的识别率,MFCC和振幅微扰的特征组合可以得到68.5%的识别率,最佳性能69.1%的识别率由MFCC、频率微扰和振幅微扰的共同组合获得。
Nwe等人[5]将HMM用作分类器对包括生气、厌恶、害怕、高兴、悲伤和惊讶在内的6类情感进行说话者相关的识别,结果表明LF-PC取得了77.1%的识别率。
Breazeal等人[6]利用高斯混合模型(Gaussian Mixture Model,GMM)分类器对面向婴儿的KISMET数据库进行情感分类,并使用一种基于峰态模型的选择策略对Gaussian成分的数量进行优化,由基频和能量的相关特征训练得到GMM模型,最优性能可达到78.77%.
Nichoson等人[7]基于MLP(multi-layer perceptron)建立了一个OCON网络模型,对8种情感进行识别,所使用的数据库是自行录制的,有100位说话者参与录制。实验表明,该模型的最优识别率为52.87%.上述研究大多数都是针对西方语种的语音情感。而针对普通话语音情感的研究则较少,基本都是在国内进行,主要研究机构有东南大学、微软亚洲研究院、清华大学、浙江大学及台湾的一些大学和研究所等。由于普通话与西方语种发音的方式不同,普通话是声调语言,而英语等西方语种是重音语言,因此能准确表达情感的特征必然不尽相同。
针对普通话的语音情感,本文在普通话情感语料库上提取了一些与其它研究不同的语音情感特征参数组合,接着对原始特征集合利用主成分分析(Principal Component Analy-sis,PCA)来降低维数,然后采用多类分离支持向量机(Sup-port Vector Machine,SVM)进行建模,最后进行大量识别测试实验。
2语音情感识别系统结构
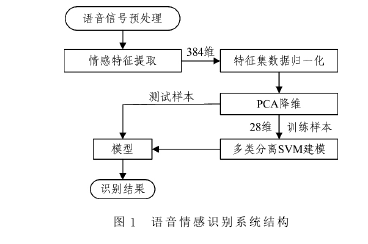
本文的语音情感识别系统结构如图1所示,每个步骤之间通过样本数据进行关联。情感特征的提取、PCA降维和SVM建模是其中的关键环节。
3语音情感特征的提取
情感语音库能为情感建模和情感语音声学特征分析提供统计数据支持,同时也为情感语音识别提供必要的训练和测试语料数据。情感语音库的质量高低,决定了由它训练得到的情感识别系统的性能好坏。目前,领域内存在的情感语音库类型多样,并没有统一的建立标准[1],多数研究会建立自己的语料库。为了使实验结果有更好的横向比较依据,本文采用国内具有代表性的中科院自动化所模式识别实验室提供的普通话情感语料库CASIA[8].该语料库由中文普通话情感短句组成,是在实验室受控环境下,对两位女性和两位男性分别录制所得。语料的采样率为16KHz,采样精度为16bit,音质清晰,无明显噪声干扰。语料涵盖了愤怒(angry)、高兴(happy)、悲伤(sad)、害怕(fear)、惊讶(surprise)和中性(neu-tral)这6种类别。每个说话人每个类别均包括50个已标记情感类别的短句,整个语料库由1200个短句组成。
实验中,首先对所有的1200句语料进行预处理、分帧和加窗,再基于各语音分析帧提取声学特征。用于语音情感识别的声学特征主要有韵律学特征、基于谱的相关特征和声音质量特征这3种类型。这些特征以帧为单位进行提取,以全局特征统计值的形式参与情感的识别。全局统计的单位是听觉上独立的语句或者单词,本文采用的统计指标有极值、极值范围、均值和方差等。
基于谱的相关特征被认为是声道形状变化和发声运动之间相关性的体现[9],已经在包括语音识别、说话者识别等在内的语音信号处理领域有着成功的运用。
Nwe等人[5]通过对情感语音的相关谱特征进行研究发现,语音中的情感内容对频谱能量在各个频谱区间的分布有着明显的影响。例如,表达高兴情感的语音在高频段表现出高能量,而表达悲伤的语音在同样的频段却表现出差别明显的低能量。本文提取其中的一种倒谱特征---MFCC.
韵律是指语音中在语义符号之上的音高、音长、快慢和轻重等方面的变化,是对语音流表达方式的一种结构性安排。它的存在与否并不影响我们对字、词、句的听辨,却决定着一句话听起来是否自然顺耳,它的情感区分能力已得到语音情感识别领域研究者们的广泛认可。普通话的声调特性决定了它的韵律特征在情感识别中的重要作用。本文提取3种韵律特征:基频、短时能量和短时平均过零率。
声音质量是语音的一种主观评价指标,用于衡量语音是否纯净、清晰、容易辨识等[10].对声音质量产生影响的声学表现有喘息、颤音、哽咽等,并且常常出现在说话者情绪激动、难以抑制的情形下。声音质量的变化被多数研究者认定为同语音情感的表达有着密切的关系。本文提取的共振峰频率就是其中之一。
3.1 MFCC特征
MFCC是语音情感识别中常用的一种特征参数。它根据人耳的听觉特性,将频谱最终转化为倒谱域上的系数[11].MFCC具有较好的识别性能和抗噪能力,它的值大体上对应于实际频率的对数分布关系,具体关系可用式(1)表示:
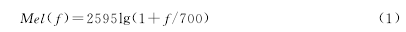
3.2基音频率特征
基音是指发浊音时声带振动所引起的周期性。声带振动频率称为基频。因为普通话是一种有调语言,基音的变化模式称为声调,它携带着非常重要的信息,基音频率反映了语音情感的重要特征。本文采用短时自相关函数来检测基音:
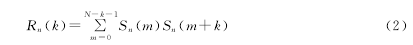
3.3短时能量
设语音时域信号为x(l),窗函数为w(m),加窗后的第n帧语音信号为xn(m),则该帧的短时能量为

3.4短时过零率
短时过零率指帧语音信号时域波形穿过时间轴的次数。加窗后第n帧语音信号xn(m)的短时过零率为:
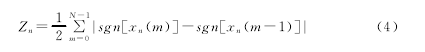
3.5共振峰特征
共振峰是反映声道信息的重要参数,代表了发音信息最直接的来源。本文采用线性预测法求取第一共振峰。首先估计出预测系数,然后估计声道的功率谱,再用峰值检测法检测出各共振峰的频率。提取出每句语料的各个特征后,再计算每个特征的12个统计量。这些共同组成384维的统计特征向量,用来表征对应语句的情感信息。提取的情感特征及相对应的统计量如表1所列。

4基于PCA的特征抽取
表1中提取的特征向量属于高维空间,为了降低运算开销同时提高分类正确率,需要利用特征抽取方法将原始空间的特征属性转移到新的低维空间。目前,语音情感分析中常用的特征抽取算法有主成分分析PCA、线性判别分析(Linear Discriminant Analysis,LDA)、核主成分分析(Kernel PCA)、等度规映射(Isometric Feature Mapping,ISOMAP)等。
主成分分析PCA是经典的线性降维算法,其基本思想是在样本空间中寻找若干个变化最为显著的方向,通过投影达到有效降低特征维数的目的。
Lee[12]在分离对话语料的两种情感状态时采用了PCA技术;Chuang[13]采用PCA从33个声学特征中抽取了14个主元特征。在特征抽取过程中,对于给定的n个d维的训练样本特征向量x1,x2,…,xn,xi均为列向量形式,可将其构成一个d行n列的数据矩阵Xd×n=[x1,x2,…,xn],则PCA的计算流程如下:
1.计算特征向量x1,x2,…,xn的均值μ和协方差矩阵COVd×d.
2.计算矩阵COVd×d的本征值和本征向量,每个本征向量都对应一个本征值,组成多个本征值-本征向量对(λi,ei),按照本征值从大到小排序为:(λ1,e1),(λ2,e2),…,(λd,ed),其中λ1≥λ2≥…≥λd≥0.
3.选取前k个本征值(k?d)所对应的本征向量e1,e2,…,ek作为主成分方向,即低维子空间的基向量,构造出大小为d×k的映射矩阵A,其中A的第i列(1≤i≤k)就是所选取的第i个本征向量。
4.将高维原始数据按照下式投影到低维子空间:PCA(x)=AT(x-μ)。
根据所选取的主成分本征值之和占协方差矩阵所有本征值总和的百分比大于95%,确定参数k的值为28.因此,通过PCA方法将原来的384维的特征向量降为28维。由于特征向量中各维元素的单位不统一,因此在主成分分析前对所有的特征向量做了归一化处理。本文的归一化处理方法是把各维元素都化为均值为0、方差为1的正态分布参数。
5 SVM分类模型的构建
常用的分类模型的构建方法有支持向量机SVM、K近邻法(K-Nearest Neighbor,KNN)、隐马尔可夫模型HMM、高斯混合模型GMM、人工神经网络(Artificial Neural Network,ANN)。本文采取的分类算法是SVM,它在解决小样本数据集、非线性以及高维模式识别问题中表现出特有的优势。
SVM是建立在结构风险最小化准则的基础上的,它根据有限的样本信息,通过对推广误差上界的最小化达到最大的泛化能力。对于线性可分的样本空间,该算法寻找最优分类超平面,能够同时最小化经验误差与最大化几何边缘区,最优分类超平面能够尽可能多地将两类样本正确地分离,同时使分离的两类样本距离超平面最远,这是一个受限的二次规划问题求解。
对线性可分的样本集(xi,yi),i=1,2,…,n,x∈Rd,y∈[-1,+1],利用Lagrange优化方法可以把最优分类面问题转化为对偶问题。即在约束条件

由于传统的SVM是针对二分类问题的,在本文中对二类分离SVM模型进行扩展,构造15个SVM子分类器。每个子分类器负责分离其中的两个类别。比如分离类别i和j的子分类器将属于类别i的数据标记为1类,属于类别j的数据标记为2类。测试时,每个子分类器都对测试数据进行分类标记,最后的结果由所有的子分类器参加投票,得票最高的类别就是测试数据的类。
本文通过非线性变换将原问题转化为线性问题,转化过程采用RBF核函数:
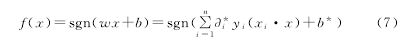
对于参数值的选取,本文根据多次实验测试,选取实验结果最好的情况:惩罚因子C=10,参数r=0.01.
6实验结果与分析
为了验证生成模型的可靠性和实用性,本文采用10折交叉验证。重复实验10次,每次将90%的数据用于训练,而10%留作测试数据。因此,每次实验中,1080个样本用于训练,120个样本用于测试。
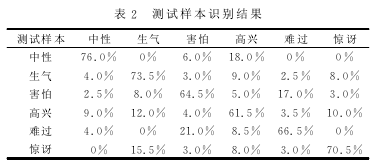
经过测试,实验得到的结果如表2所列。从表2中的对角线上观察到,6种情感的识别率分别为76.0%、73.5%、64.5%、61.5%、66.5%和70.5%,都处于合理的范围内。另外可以看到,生气与高兴、惊讶间的误判率,还有害怕与难过间的误判率,是相对较高的。原因是这两组情感之间相似度较高,以至于容易发生误判。
本文选取了其它一些有代表性的研究结果与上述实验方法及结果进行了对比,如表3所列。从表3可以看出,各个研究使用的语料库、语音情感特征、特征维数和分类模型都不尽相同。在有使用普通话情感语料的研究中,本文的平均识别率68.8%处于中等水平。在这些研究当中,本文最终选取的特征维数属于中等,但平均识别率还是较高,处于中上水平。
通过对比表明本文的方法及实验结果是有效的。
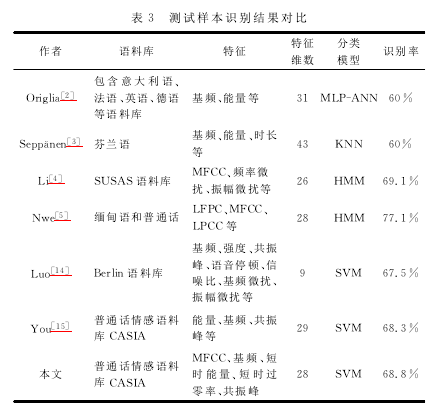
从表3看出,本文与You[15]选取的语料库相同,但特征不完全相同,特征维数和分类模型基本一致。为了有更强的对比和更深入的研究,本文与You[15]的方法进行详细对比,结果如表4所列。

从表4中观察到,两个研究中6种情感识别率之间互有高低,但本文的6个识别率之间相差较小,并且总识别率略高。原因是本文选取了更为合理有效的情感特征。另外,虽然两者都是采用SVM构建分类模型,但参数设定不一样。
结束语
本文在中科院的普通话情感语料库上进行语音情感识别实验,并与相关成果进行了比较。结果表明,本文选取的特征值是合理的,进行的抽取方法是有效的、可行的。在今后的研究工作中可以提取更多不同、有效的特征值并选取不同的抽取方法进行实验,对于相似度较高的情感可以有针对性地研究,减少相互的误判率,以达到更高的识别率。





