摘 要: 本文通过感知实验和声学分析, 比较了普通话人群 (母语组) 和香港粤语人群 (粤语组) 在不同前字调和不同语境 (孤立词、宽焦句中词、窄焦句中焦点词) 下产出的普通话轻声词。感知实验表明, 粤语组轻声的自然度总体上低于母语组, 其中孤立词的自然度下降最多, 句中焦点词其次, 宽焦句中词下降最少。声学分析表明, 首先粤语组的最大问题是轻声音节时长过长、时长占比过大、与前字的基频绝对差偏小;其次, 对于句中焦点位置的轻声词, 粤语组未能掌握基频编码的规则。对感知与声学结果关系的分析, 也验证了对粤语组轻声自然度影响最大的因素是轻声时长。实验结果启示我们, 在针对粤语人群的普通话轻声的教学中, 应当重视轻声的时长特征、重视焦点位置轻声词的音高特征, 从而有针对性地纠偏。
关键词: 普通话; 香港粤语; 轻声; 焦点; 二语韵律偏误;
Abstract: This study compared Mandarin neutral tone ( T0) produced by native speakers ( L1 group) and Hong Kong Cantonese L2 learners ( L2 group) , through both perceptual experiment and acoustic analysis. The T0 syllables after four tones in three types of word contexts ( i. e., isolated word, word in a broad-focus utterance, and on-focus word in a narrow-focus utterance) were investigated. The perceptual experiment showed that T0 had a lower score of naturalness in the L2 group than in the L1 group; the difference between L1 and L2 was larger in isolated words than in sentences. Acoustic analysis showed that T0 in general had longer duration, larger durational ratio, and smaller F0 difference between the two syllables in the L2 group than in the L1 group. In addition, for T0 syllables in focused words, L2 group failed to acquire the rules of F0 encoding effectively. Comparison of the perceptual and acoustic results shows that syllable duration is the most important factor contributing to the naturalness of T0 syllables produced by the L2 group. This study suggests the importance of paying attention to the context-dependent characteristics of T0 in learning Mandarin as L2.
Keyword: Mandarin; HK Cantonese; neutral tone; focus; L2 prosodic error;
在二语习得的过程中, 语音习得一直是重点和难点, 可以说“在汉语作为第二语言语音习得的许多难点中, 最敏感最影响可懂度的是声调”。[1]粤语作为一种很重要的汉语方言, 使用人数多, 分布范围广, 影响力大。粤语在语音、词汇及语法上都与普通话存在较大差异, 使得粤语人群习得普通话有较大困难。在声调的习得上, 有研究表明粤语人群对普通话声调的感知和产出表现并不比英语母语人群好多少。[2]对于粤语中并不存在的轻声, 粤语人群掌握起来更是困难, 轻重音处理不当也成为其方言口音的重要表现之一。[3]
早在20世纪30年代, 赵元任就根据听感描述了普通话轻声音节的音高和时长特征。他认为轻声的音高由前字调决定:阴平、阳平之后是半低, 上声之后是半高, 去声之后是个低调;同时, 轻声的时长较短。[4,5]后来的学者借助现代仪器, 对轻声的基频和时长进行了声学测量, 得出了相似的结论:轻声在上声之后表现为一个中平调, 而在其他声调之后是个降调, 只不过在起点基频上有所不同, 阳平后起点基频最高, 阴平后次之, 去声后最低[6,7,8,9];轻声音节时长较短, 大约是非轻声音节的一半[6], 约为前字时长的60%[7]。
轻声研究的一个主要目标是寻找轻声感知的声学线索。林焘采用合成语音考察了音长、音强和音高在普通话轻声感知中的作用, 他发现音强并非轻声感知的可靠线索, 而音高、时长对轻声感知起主要作用, 但音高作用要小于时长。[10]前一点得到了后来学者们的验证[7,11], 而关于音高和时长的关系, 很多学者却持不同观点, 认为在轻声感知上音高的作用要大于时长[7,8,12,13,14]。也有研究对其他声学线索进行了探讨, 如发现频谱倾斜 (spectral tilt) 有一定作用但重要性小于音高和时长。[15]
与丰富的本体研究相比, 普通话作为二语的轻声研究较少。王功平等实验考察了母语为无声调语言的留学生在普通话双音节轻声词上的音高偏误, 他们发现:调型偏误表现为趋平、调域偏误表现为偏窄;不同声调组合的偏误程度不同, 其中上声+轻声组合的调型偏误率最高, 阴平+轻声组合的调域偏差幅度最大;母语负迁移、语音同化和语内干扰是造成上述偏误的原因。[16]汤平在对日本留学生的研究中得出了类似的结论, 调型偏平、调域偏窄同样是日本留学生轻声产出的主要偏误, 此外, 轻声音节时长过长。[17]

研究发现, 二语人群的普通话轻声偏误受母语负迁移影响。但是, 前人研究对象较少涉及母语为声调语言的学习者。粤语是没有轻声的声调语言, 针对粤语人群的普通话轻声习得研究有特别的意义。Cheng考察了粤语人群感知和产出普通话轻声的能力, 发现普通话水平较高的组产出的轻声较好, 水平较低的组能够掌握语法轻声词 (具有特定语法标记的轻声词, 如带有后缀“子”的轻声词) , 但是对词汇轻声词 (没有特定语法标记的轻声词) 的掌握较差, 作者认为母语迁移是词汇轻声词偏误的主因。[18]
考虑到轻声调型由前字调决定, 其二语偏误模式可能随前字调而异;另外, 在孤立词和连续语句中, 在句中的焦点词和非焦点词上, 轻声的表现都有可能不同, 特别是焦点词的重读和轻声这对相矛盾的因素如何交互作用, 这些都会给偏误模式造成影响。因此, 本文将深入考察香港粤语人群说普通话时, 在不同前字调、不同语境下的轻声偏误模式。
一、实验语料
1. 语料设计
首先, 我们分别设计了四声加轻声的双字组, 每种声调组合选了三个常用轻声词, 全部选自《普通话水平测试用必读轻声词语表》。[19] (P251-P259) 其中一个是叠词, 一个带词缀“子”, 一个没有特定语法标记。所有字的声母都是阻塞音。具体词表如下:
T1+T0:哥哥, 箱子, 师傅
T2+T0:婆婆, 绳子, 媳妇
T3+T0:姐姐, 剪子, 姐夫
T4+T0:舅舅, 扇子, 大夫
以上轻声词分别放在以下三种语境中考察:
(1) 孤立词 (记为IW) 。
(2) 宽焦句中词 (下文简称非焦点词, 记为NF) :设计了两个全阴平的承载句“他帮XX开车”、“他将XX搁在桌上”, 第一个承载句中的XX是叠词轻声词或无标记轻声词, 第二个承载句中的XX是带词缀“子”的轻声词。
(3) 窄焦句中焦点词 (下文简称焦点词, 记为OF) :将目标词置于句中焦点位置, 通过对话诱导出焦点。例如, 以目标词“哥哥”为焦点时, 对话如下 (B为被试) :
A:他是帮弟弟开车吗?
B:他帮哥哥开车。
2. 发音人
实验安排了两组被试, 分别是熟练使用普通话的内地学生 (母语组, 记为L1组) 、以香港粤语为母语的普通话学习者 (粤语组, 记为L2组) 。每组被试包括年龄相仿的8名大学生 (4男4女) , 母语组平均年龄为24岁, 粤语组平均年龄为20岁。母语组被试都是硕士研究生, 普通话水平测试均达到二级甲等。粤语组被试都是在南京读大学的香港学生, 母语为粤语, 都有一至两年的普通话课堂学习经历, 普通话能力中等, 未参加过普通话水平测试。所有发音人均无言语或听力障碍。
3. 语音录制与数据提取
录音在隔音室内完成, 录音软件为Adobe Audition 1.5[20]。录音前, 要求发音人充分熟悉语料、认识所有的词。录音时, 要求发音人语速平稳、发音自然, 发错或者不流利的词或句子要重新录制。对IW、NF、OF三种语料分别录制, 录制时各自按随机顺序排列。其中, IW、NF语料由发音人直接念出, OF语料由主试与发音人对话完成。录音完成后, 采用Praat[21]对录音进行切分, 共获得576个目标词 (4声调×3语境×3词×8发音人×2组) 。
二、听辨实验
为比较两组被试轻声词的自然度, 我们设计了一个听辨实验。听辨人为8名 (4男4女) 年龄相仿的普通话熟练使用者, 都是南京师范大学的硕士研究生, 与发音人没有交集, 平均年龄25岁, 普通话水平测试均达到二级甲等, 无言语或听力障碍。听辨内容为576个目标轻声词, 按随机顺序组成18个语音文件, 每个文件包含32个语音刺激, 相邻刺激之间有5秒的无声段间隔。听辨实验在隔音间进行, 采用E-Prime 2.0[22]呈现刺激并采集听辨人的反应, 实验范式为恒定刺激法。听辨人佩戴AKG K271 MKII耳机, 在每个5秒无声间隔内, 判断刺激词后字 (即轻声字) 的声调是否恰当, 并通过按键选择:“恰当”、“不恰当”、“说不清”, 超时未选则系统自动判为“说不清”并跳转到下一个词。实验采用特制键盘, 主键区只有三个按键, 各按键之间有足够距离以避免误按。实验开始前听辨人充分练习, 熟悉实验流程。每听完一组32个词, 听辨人可以休息。实验结束后, 选择结果自动保存到相应文件。
根据听辨数据的特点, 我们选择混合逻辑模型 (mixed logit models) 进行统计分析, 该方法适合因变量为二项分布的数据, 能够同时控制被试、项目等随机因素, 比方差分析更有效。考虑到“说不清”的选择也意味着发音不准, 我们将听辨结果中的“说不清”与“不恰当”合并, 然后用R语言[23]的afex包[24]建立模型, 因变量参考水平设置为“不恰当”, 固定效应设置为组别、前字调和语境, 随机效应设置为发音人、词条和听音人, 采用LRT方法计算p值, 结果如表1所示。再用R语言的lsmeans包[25]做事后检验和简单效应分析, 多重比较的p值采用Tukey校正。将轻声词被判“恰当”的比率定义为自然度, 从图1的自然度模型分析结果可见:
(1) 组别的主效应显着 (p<0.001) , L2组的自然度低于L1组;前字调的主效应显着 (p<0.05) , 其中T2+T0的自然度显着低于T4+T0 (p<0.05) ;语境的主效应显着 (p<0.01) , 其中IW的自然度显着低于NF (p<0.001) , 而NF的自然度显着低于OF (p<0.05) 。
(2) 组别和前字调的交互效应显着 (p<0.01) 。进一步的简单效应分析发现, 在四种前字调下, L2组的自然度均显着低于L1组 (p<0.01) , 其中差距最大的是T2+T0。多重比较结果表明, L1组内各调类间均无显着性差异, L2组内T2+T0同T4+T0之间存在显着性差异 (p<0.05) 。
(3) 组别和语境的交互效应显着 (p<0.01) 。简单效应分析表明, 在三种语境下, L2组的自然度均显着低于L1组 (p<0.01) , 其中IW条件下差距最大, OF条件下次之, 而NF条件下差距最小。多重比较结果表明, L1组内各语境间均无显着性差异, L2组内各语境间均存在显着性差异 (p<0.01) 。
表1 各因素对轻声自然度的作用
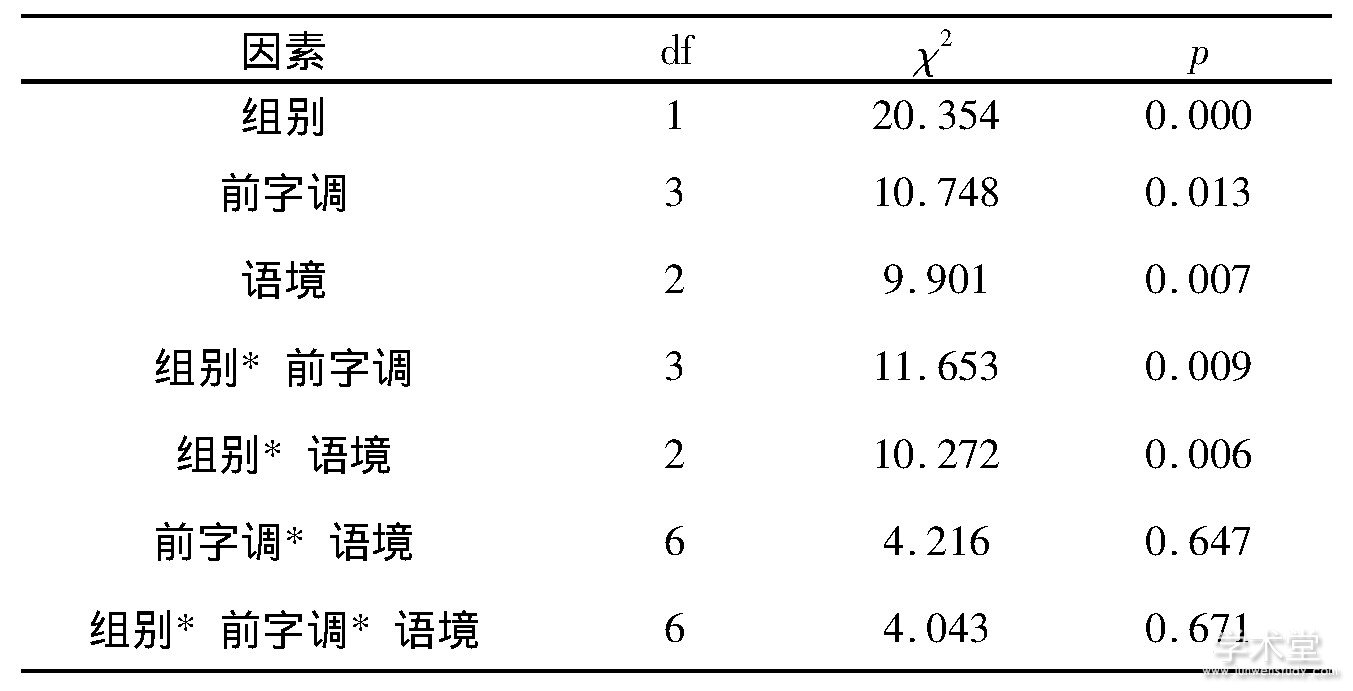
(注:df为自由度, χ2为检验统计值, p为显着水平。)
图1 不同前字调和语境下的轻声自然度
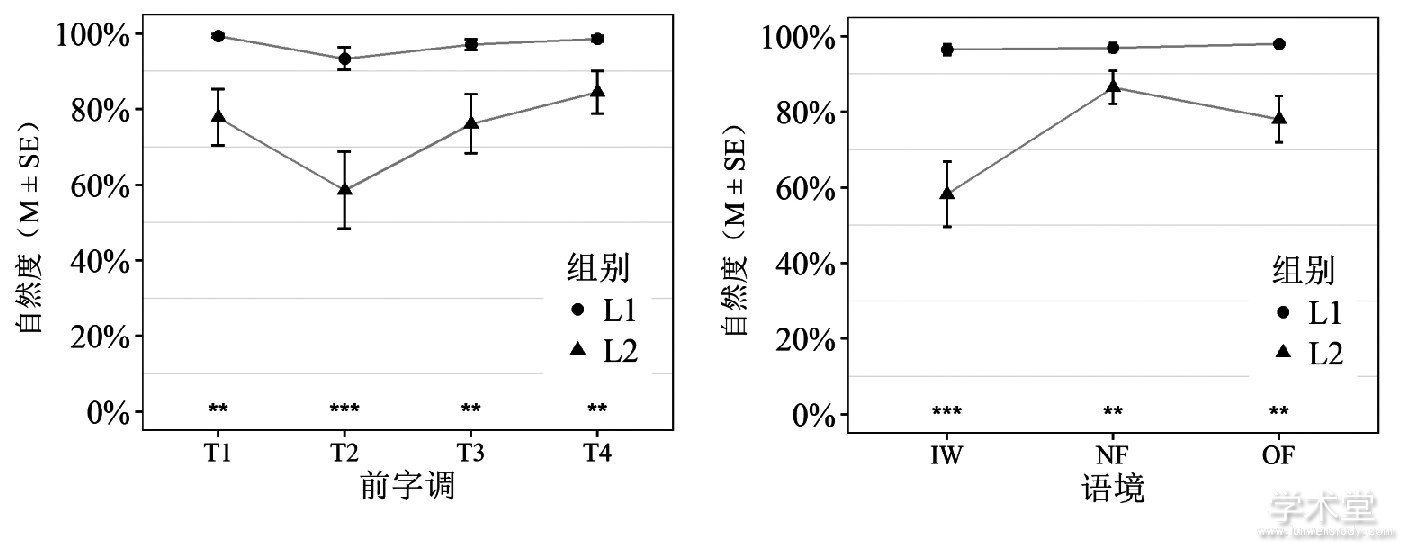
(注:***p<0.001, **p<0.01, *p<0.05;下同。)
三、声学分析
首先使用p raat脚本提取目标词各音节的声学参数, 包括:基频范围 (St) 、基频均值 (St) 、音节时长 (s) 、时长占比 (%) 。其中, 基频的单位为半音St (以50Hz为参考值计算而得) , 时长占比是指轻声音节在双音节词中的时长比例。此外, 计算了前后字基频的绝对差值 (St) , 并通过线性回归计算了各音节的基频斜率 (St/s) 。
1. 不同前字调和语境下的声学参数
统计分析采用线性混合效应模型 (linear mixed-effects models, LMM) , 同样用afex包建模, 固定效应为组别、前字调和语境, 随机效应为发音人和词条, 前后字的各声学参数分别作为因变量, 统计分析得到的p值如表2所示。事后检验和简单效应分析方法同听辨实验一样, 根据统计结果, 图2、图3分别给出各声学参数的组别和前字调、组别和语境的交互作用。本文的主要目的是研究二语偏误, 所以重点考察与组别有关的因素, 分析发现:
表2 各因素对前后字声学参数的作用p值
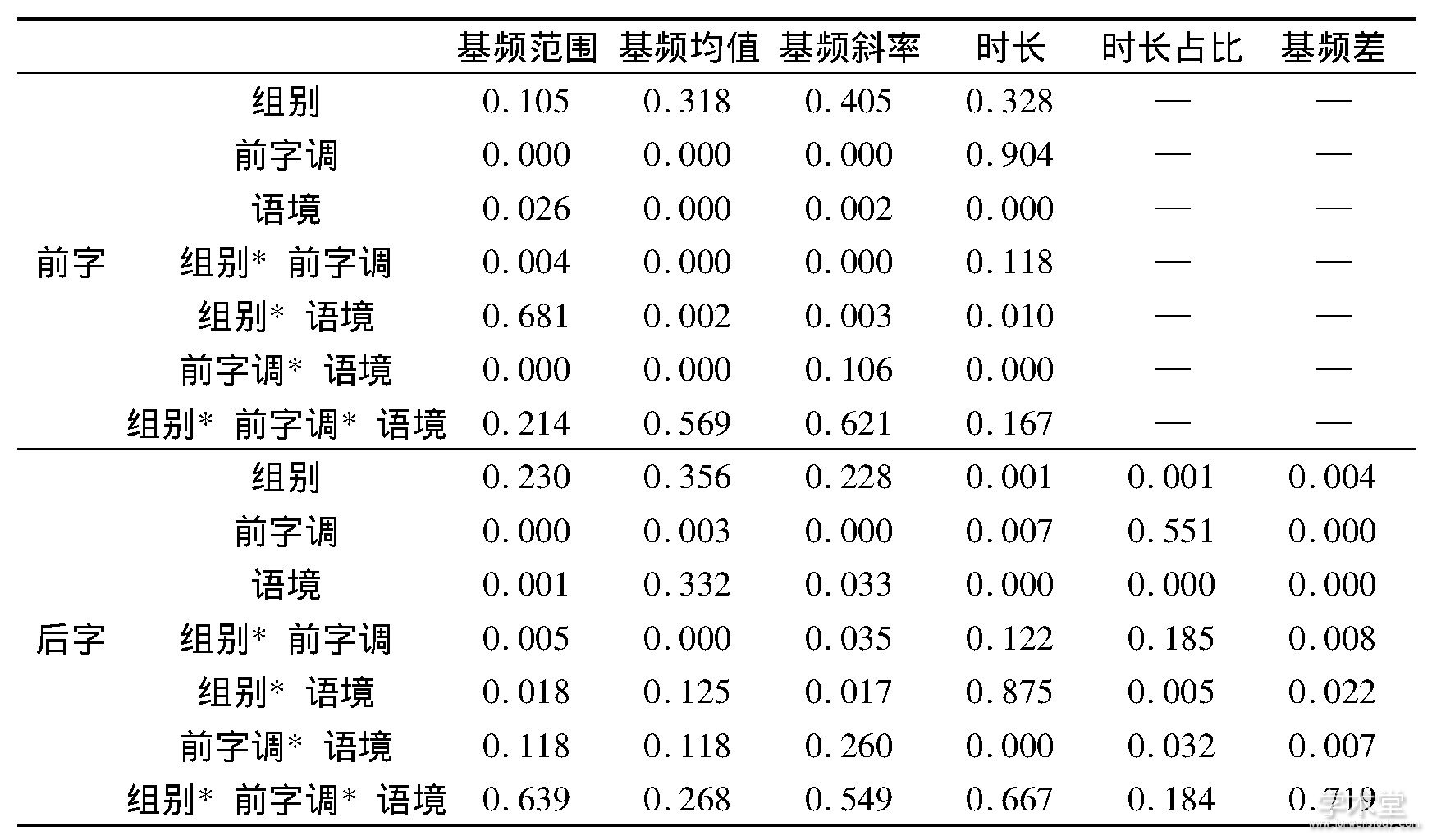
图2 组别与前字调对各声学参数的交互作用
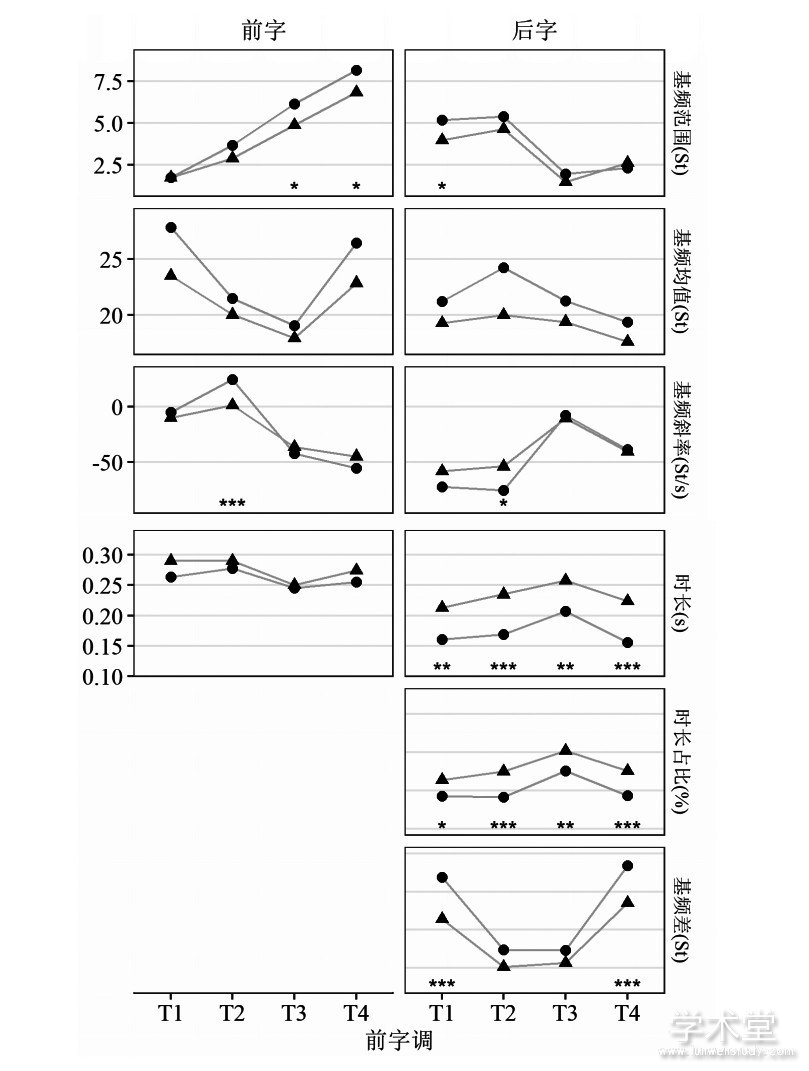
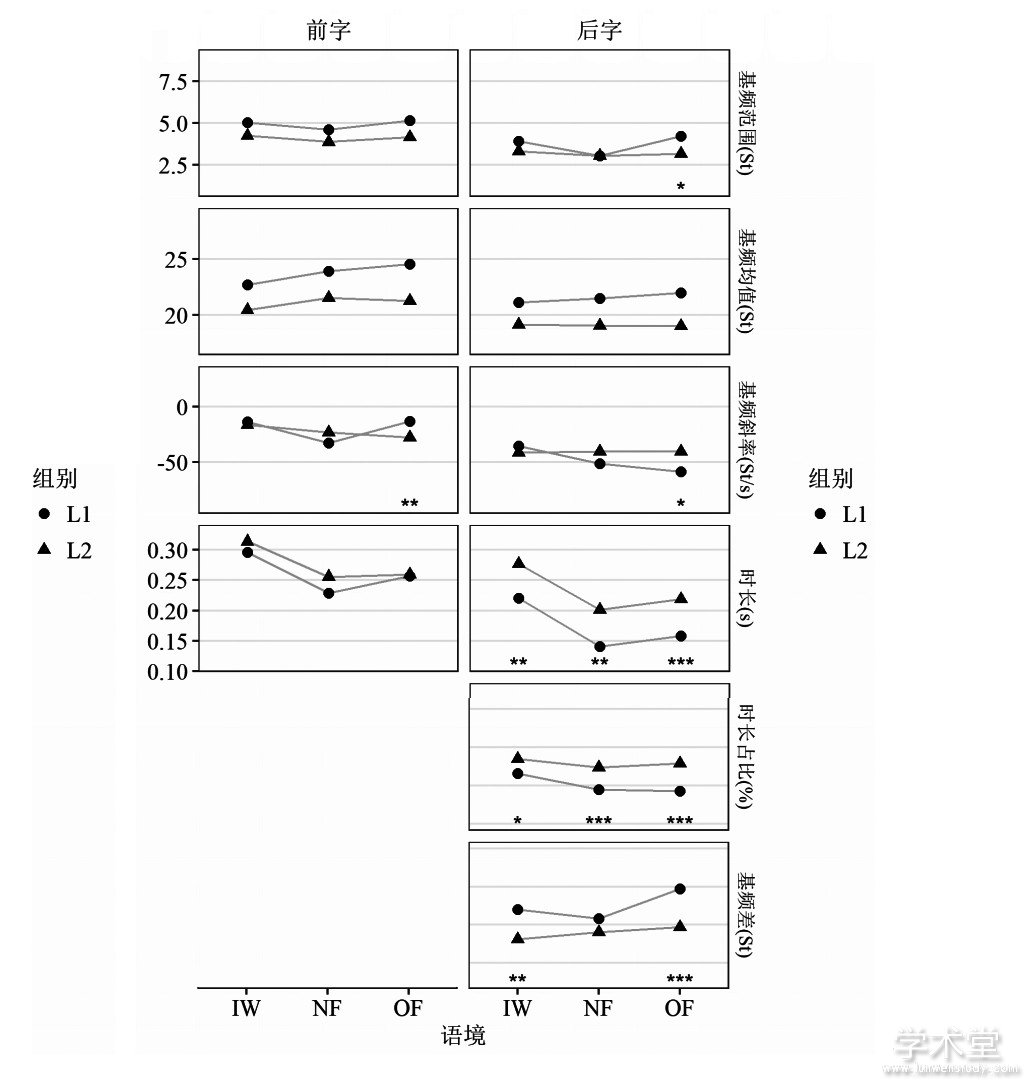
图3 组别与语境对各声学参数的交互作用
(1) 组别的主效应在后字时长及时长占比、基频绝对差值上显着 (p<0.01) 。L2组的后字时长及时长占比均显着大于L1组, 表明粤语人群的轻声音节不够“短”;L2组绝对基频差值也显着小于L1组, 表明L2组轻声词前、后字音高差距比L1组减少了。
(2) 组别和前字调的交互效应在前后字基频范围、均值、斜率以及基频差上均显着 (p<0.05) 。由图2可以看出, 在不同前字调水平的变化模式上, L2组与L1组基本一致, 交互效应主要体现在不同前字调水平上两组间差异量存在区别。
(3) 组别和语境的交互效应在大多数参数上显着 (p<0.05) , 只有在前字基频范围、后字基频均值和时长上不显着。由图3可以看出, 在OF条件下的后字, L1、L2组间差异较大, 除基频均值外, 各声学参数均存在显着性差异 (p<0.05) 。
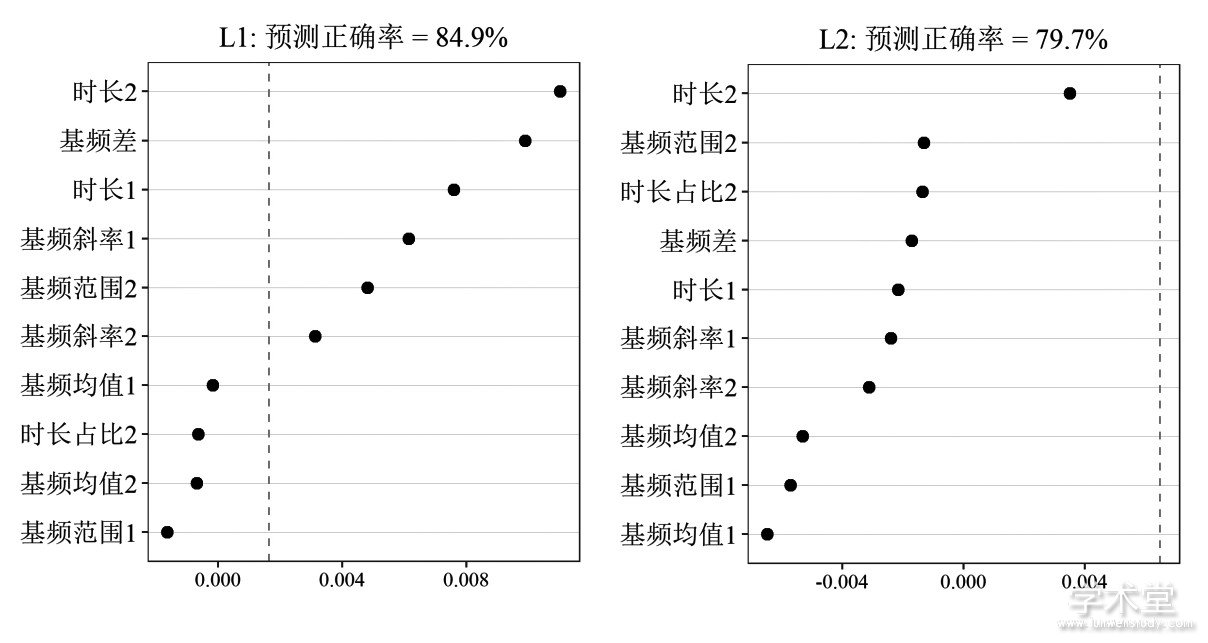
组内多重比较结果表明, 两组在IW条件下前后字时长均长于NF、OF。在NF和OF的对比上, L1组存在显着差异的参数包括前字的基频均值、斜率和时长, 后字的基频范围和时长, 以及前后字的基频绝对差值, 而L2组只在后字时长上存在显着差异。这些差异显着的参数反映了焦点的编码方式。为了进一步考察各参数的贡献大小, 我们采用随机森林 (random forest, RF) 的分类算法[26]在每组内对NF、OF做自动分类, 计算各声学参数的变量重要性评分 (variable importance measure, VIM) 。VIM计算将某变量取为随机数时模型预测正确率的减量, VIM数值越大表明该变量越重要。采用R语言的party包[27], 以语境 (NF或OF) 为响应变量, 各声学参数为预测变量, 分别建立L1、L2组的随机森林模型, 计算预测正确率和各声学参数的VIM。由于预测变量之间存在相关性, 计算VIM时设置conditional参数为TRUE[28]。结果如图4所示, 其中声学参数后面的“1”代表前字、“2”代表后字;虚线为参考线, 取为所有VIM中最小值的绝对值;一般认为居于参考线右侧的变量是重要性较高的变量[29,30]。
L1组的模型预测正确率是84.9%, VIM最大的是后字时长和基频绝对差值, 同时前字的时长和基频斜率, 后字的基频范围和斜率也都有较高的评分;但是此前LMM分析中NF、OF存在显着差异的前字基频均值, VIM却很低。L2组的模型预测正确率是79.7%, 低于L1组, 且VIM全部在参考线左侧, 其中大于0的只有后字时长。综合以上分析, L1组焦点位置轻声词的主要实现方式是拉长前后字时长、增大前后字基频差值, 同时伴有基频曲线变陡、后字基频范围变大的特征;L2组对焦点位置的轻声词编码时, 只是采用了拉长轻声音节的策略, 但是没有掌握基频的变化规则, 导致焦点位置的轻声词产出有明显偏误。
图4 各声学参数对语境 (NF或OF) 的VIM值
2. 轻声自然度与声学参数的关系
2我们进一步考察感知实验获得的自然度评分与声学分析获得的各声学参数之间的关系。采用随机森林算法, 建立两者之间的回归模型, 计算各声学参数的VIM, 结果如图5所示。
图5 各声学参数对自然度的VIM值
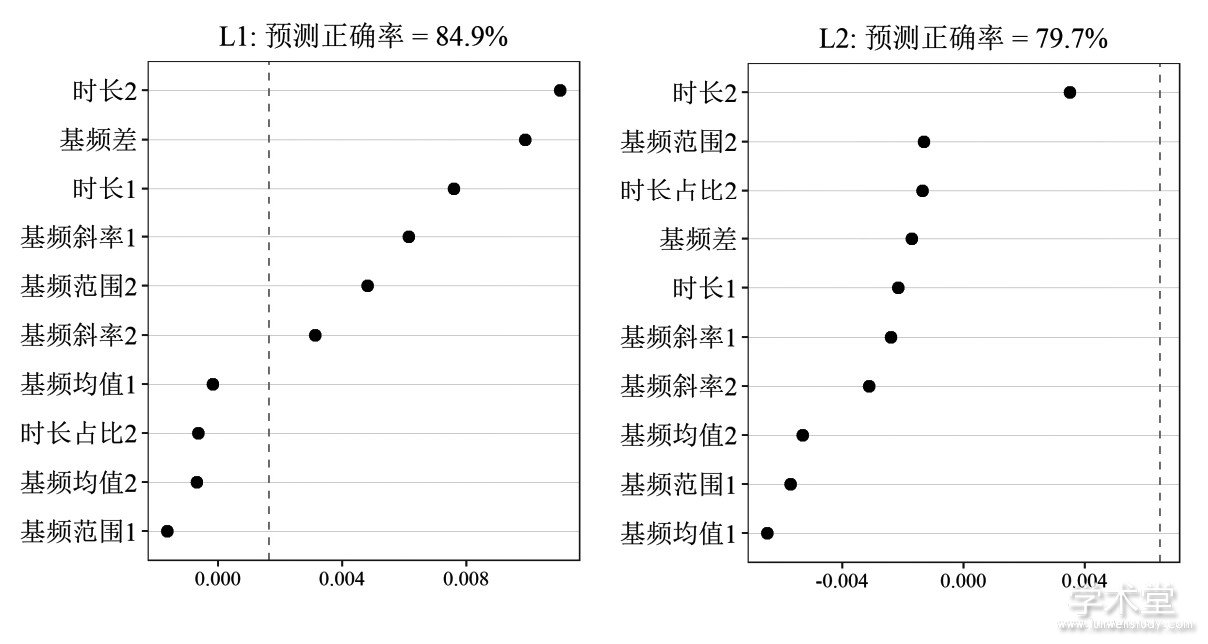
可以看出, L1组由于自然度高, 各声学参数对自然度的VIM都较小, VIM最高的声学参数是基频绝对差值。对比听辨实验和声学分析的结果可见, 基频绝对差值较小的T2+T0和T3+T0对应的自然度也略低。
对于L2组, 则是后字时长对自然度的VIM最高。声学分析表明L2组轻声音节不够短, 造成自然度整体偏低。L2组IW的后字时长显着长于NF、OF, 造成了IW时的自然度显着偏低;此外, L2组的前字基频斜率、前后字基频绝对差值也对自然度有一定贡献, 这就解释了听辨结果中T2+T0与T4+T0之间的显着性差异:观察图2可以看到, T2在前字基频斜率上远高于T4, 而在前后字基频绝对差上又远低于T4。
总的来说, L1组只有基频差对自然度具有较高的贡献;对于L2组而言, 轻声时长是影响自然度的最重要参数, 这说明L2组的偏误主要在于轻声时长。
四、结论
本研究系统考察了香港粤语人群在不同前字调和不同语境条件下的普通话轻声偏误。听辨实验表明, 粤语组的轻声自然度总体上低于母语组。并且, 在不同声调组合中, 阳平+轻声组合的自然度下降最多;在不同语境中, 孤立词的自然度下降最多, 句中焦点词其次, 句中非焦点词下降最少。
声学分析的结果表明, 粤语组最大的问题在于轻声音节时长过长、时长占比过大、与前字的基频绝对差偏小, 说明没有掌握轻声“短”、“轻”的特征, 这很可能是“粤语无轻声”的母语音系规则负迁移的结果。特别是, 在焦点词上轻声字的偏误尤为严重。通过焦点和非焦点位置轻声词的对比发现, 母语组对于焦点位置轻声词的主要编码方式是拉长前后字时长、增大前后字基频差值;L2组只是采用了拉长轻声音节的策略, 没有掌握焦点的基频编码规则。
对照听辨实验与声学分析的结果, 我们进一步考察了各声学参数对轻声自然度的贡献。由于母语组自然度总体较高, 各声学参数对自然度的贡献都比较小, 其中基频绝对差值是影响自然度的主要参数;而对于粤语组, 后字时长对自然度有相当大的影响, 进一步表明粤语组的轻声偏误主要在轻声时长上。
本研究表明, 在不同前字调和不同语境下, 粤语人群的普通话轻声偏误存在差异。针对粤语人群的普通话轻声的教学, 应当尤其重视轻声的时长特征、重视焦点位置轻声词的音高特征, 有针对性地纠正轻声偏误。
参考文献:
[1]朱川.汉日超音质特征对比实验[J].华东师范大学学报 (哲学社会科学版) , 1994 (1) .
[2]Hao Y. Second language acquisition of Mandarin Chinese tones by tonal and non-tonal language speakers[J].Journal of Phonetics, 2012 (2) .
[3] 林建平.香港人在普通话水平测试中表现的方言语调[A].语文测试的理论和实践[C].北京:商务印书馆, 2001.
[4]赵元任.汉语的字调和语调[A].赵元任语言学论文集[C].北京:商务印书馆, 2006.
[5] 赵元任.国语语调[A].赵元任语言学论文集[C].北京:商务印书馆, 2006.
[6]林茂灿, 颜景助.北京话轻声的声学性质[J].方言, 1980 (3) .
[7]曹剑芬.普通话轻声音节特性分析[J].应用声学, 1986 (4) .
[8]王韫佳.轻声音高琐议[J].世界汉语教学, 1996 (3) .
[9]Lee W, Eric Z. Prosodic characteristics of the neutral tone in Beijing Mandarin[J]. Journal of Chinese Linguistics, 2008 (1) .
[10] 林焘.探讨北京话轻音性质的初步实验[J].语言学论丛, 1983 (10) .
[11]林茂灿, 颜景助.普通话轻声与轻重音[J].语言教学与研究, 1990 (3 .
[12]Li A, Gao J, Jia Y, Wang Y. Pitch and duration as cues in perception of neutral tone under different contexts in standard Chinese[C]. Proceedings of Asia-Pacific Signal and Information Processing Association, Chiang Mai, Thailand, 2014.
[13]Li A, Fan S. Correlates of Chinese neutral tone perception in different contexts[C]. Proceedings of International Congress on Phonetic Sciences, Glasgow, UK, 2015.
[14]Fan S, Chen A, Li A. The recognition of neutral tone across acoustic cues[C]. Proceedings of International Conference on Oriental COCOSDA, Shanghai, China, 2015.
[15]仲晓波, 王蓓, 杨玉芳.普通话韵律词重音知觉[J].心理学报, 2001 (6) .
[16]王功平, 周小兵, 李爱军.留学生普通话双音节轻声音高偏误实验[J].语言文字应用, 2009 (4) .
[17]汤平.日本高级汉语学习者汉语轻声韵律习得偏误分析[J].华文教学与研究, 2014 (4) .
[18]Cheng H. A study of the perception and production of neutral tone in Mandarin of Hong Kong Cantonese speakers[D]. MA thesis, The Chinese University of Hong Kong, 2013.
[19]国家语言文字工作委员会普通话培训测试中心.普通话水平测试实施纲要[M].北京:商务印书馆, 2004.
[20]Adobe, Inc. Adobe Audition 1. 5[CP]. 2012.
[21]Boersma P, Weenink D. Praat:Doing phonetics by computer[CP]. 2018.
[22]Psychology Software Tools, Inc. E-Prime 2. 0 Reference Guide Manual[CP]. 2012.
[23]R Core Team. R:A Language and Environment for Statistical Computing[CP]. 2018.
[24]Henrik S, Bolker B, Westfall J, Aust F. afex:Analysis of Factorial Experiments[EB/OL]. https://cran. rproject. org/web/packages/afex/afex. pdf. 2017.
[25]Lenth R V. Least-squares means:the R package lsmeans[J]. Journal of Statistical Software, 2016 (1) .
[26]Breiman L. Random forests[J]. Machine Learning, 2001 (1) .
[27]Hothorn T, Hornik K, Strobl C, Zeileis A. Party:A Laboratory for Recursive Partytioning[EB/OL]. https://cran. r-project. org/web/packages/party/party. pdf. 2010.
[28]Strobl C, Hothorn T, Zeileis A. Party on![J]. The R Journal, 2009 (2) .
[29]Strobl C, Malley J, Tutz G. An introduction to recursive partitioning:Rationale, application, and characteristics of classification and regression trees, bagging, and random Forests[J]. Psychological Methods, 2009 (4)
[30]Tagliamonte S, Baayen R. Models, forests, and trees of York English:Was/were variation as a case study for statistical practice[J]. Language Variation and Change, 2012 (2) .





