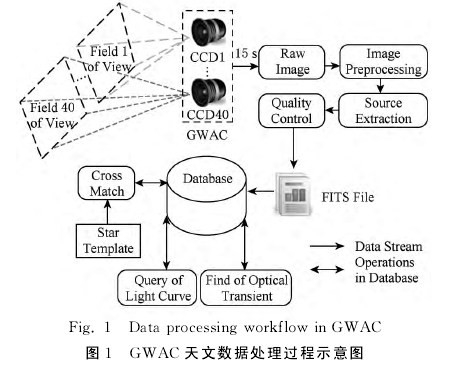
从实时角度来看,持续产生的星表数据主要有以下3个特征:
1)多镜头并行输出。
虽然每个CCD最终产生的星表数据量不大,但是40个CCD每隔15s就会产生规模庞大的数据量。这些数据需要及时存储便于查询。
2)实时瞬变源发现。
异常天文现象稍纵即逝,为了给天文科研人员留出足够的时间观测异常星,要求整个数据处理系统能够实时捕获异常星变化,并给予报警。
3)秒级查询。
天文科研人员往往需要对瞬变源或疑似瞬变源的近期历史数据快速查询,以便综合分析该天文现象。上述需求对后台的天文数据处理系统提出了巨大的挑战,要求系统能够快速响应,尤其对于当晚的星表数据而言要求能够做到快存快取。
从持久化角度来看,GWAC所有的历史数据都要进行持久化操作,以便离线状态下对星表数据进行光变曲线规律的分析和一定的数据挖掘工作。虽然为离线过程,但也要求查询过程要在合理的时间范围给予响应。
对GWAC数据管理系统的要求可总结为:1)高数据吞吐能力,所有相机阵15s内产生的观测星表可用于查询的延迟时间控制在15s以内;2)在数据高速采集下能够完成实时分析,面对持续不断的高密度海量星表的快速关联计算能力,即每个CCD每15s产生的星表数据与模板星表相关联(交叉认证:将观测的目标星映射到模板星表的已知星的过程)形成光变曲线;3)每个观测夜的2TB星表最晚完成持久化时间保证在下一个观测夜开始前;4)从长期存储的角度而言,管理系统需要有极强的海量数据管理能力,至少要能满足6PB数据的存储和离线查询能力。
1.3天文数据管理系统的相关工作目
前国内外天文数据库的主要功能仍集中在电子化归档、搜索和下载等方面,且主要历经3个阶段[7]
1)兴起阶段,此时的天文数据库主要基于文件系统的数据存储。较为着名的有法国特斯拉斯堡的恒星数据中心CDS(centre de Donn?es stellaires,即center for stellar data)的天文天体数据交互服务SIMBAD(set of identifications,measurements,and bibliography for astronomical data),利用计算机管理天文数据,能够将数据加以归档、排序和整理,并为全球星表提供交叉识别和文献目录检索功能。
2)关系数据库实现天文数据管理阶段,以提供星表服务的VizieR和SDSS为代表。到20世纪90年代末,SIMBAD服务已经无法满足更为复杂的查询需求,CDS又开发了更为强大的VizieR系统。VizieR底层依赖关系数据模型,支持基于ID和位置的搜索,且没有最大搜索半径的要求,具有较快的响应速度,但搜索的定制程度较低。此外,另一个专业的天文数据管理服务为斯隆数字巡天SDSS自主开发的数据库。SDSS的天文数据库Skyserver[8]是基于微软的SQL Server定制开发的,具有快速查询、批量下载、SQL检索和可视化图形界面等特点。这一阶段的天文数据管理开始在数据库的基础上定制了各种天文数据的科学应用,以满足天文数据特殊的检索需求。
3)即将到来的超大天文数据库阶段,以美国大口径全景巡天LSST和SKA(square kilometre array)为代表[2]一些新兴的天文领域如伽玛暴、超新星爆发对时域天文观测的要求更加迫切,直接导致天文数据量的爆发式增长。美国LSST设计每15s记录3幅10亿像素级的图像,每晚收集的数据量大约15~30TB,每3d可巡天1次,预计2022年接受观测任务。澳大利亚SKA计划每秒产生的数据量大于12TB,一天产生的原始图像为1EB,预计从2020年开始第一阶段的建设。上述大型天文观测项目已对当前的数据管理框架产生了巨大的挑战,高吞吐量、大规模存储与快速的查找已成为了主要的问题。
值得一提的是,万萌等人[9]已对当前的GWAC数据管理场景进行了一定的研究工作,并提出了基于MonetDB数 据 库 的 管 理 方 案。已 开 发 出 的GWAC数据生成器gwac_dbgen[6]能够模拟一个CCD连续产生的真实数据格式和量级。此外,基于该生成器的模拟数据使用SQL实现了MonetDB数据库内的交叉认证算法以避免数据的移动。但当累计数据规模较大时,MonetDB的扩展性较差且入库时间不够稳定。
2面向GWAC的星表数据管理系统设计
结合GWAC天文大数据的特性和研究现状,本文采用两级缓存架构和星表簇模型,建立一个高性能、可扩展的面向GWAC的星表数据管理系统。该系统能够实现在15s内存储多镜头并行输出的数据、瞬变源发现和提供秒级查询服务,此外星表簇模型有利于平衡持久化时间与离线查询效率。如图2所示,该系统中和数据管理相关的部件主要包括4个部分:一级缓存管理、二级缓存管理、数据持久化和查询引擎。

在文献[9]中,所有CCD产生星表汇入同一个MonetDB数据库后,再使用SQL对其进行交叉认证,从而产生一定的性能瓶颈。本文设计的GWAC星表数据管理系统为分布式结构,一级缓存为分布式节点的本地内存,二级缓存为分布式共享内存。当某CCD客户端发送星表数据进入系统后,系统会在某节点上创建对应客户端的接收端接收星表数据,直接进行交叉认证,然后将星表数据交由瞬变源发现模块进行异常检测,最后每个CCD对应的接收端将星表数据写入分布式共享内存中,供用户实现高速查询。设计一级缓存的目的是:1)不同CCD产生的星表数据是无共享的(shared-nothing),因此处理就具备了并行性;2)瞬变源的发现与预警需要实时检测,因此需要获取数据后尽快在本地处理;3)为了保证分布式共享内存故障后数据高可靠,需要使用本地内存做缓存实现延时写。设计二级缓存的目的是:1)天文研究者会在某颗星异常后,快速查询其最近的光变曲线以快速定位科学发现,但事先并不知道哪颗星会异常,因此需要将一个观测夜的数据缓存入分布式共享内存中供研究者快速查询;2)一级缓存容量是有限的,不足以承载一个CCD的整个观测夜数据。
在观测夜结束后,将当前观测夜的数据持久化到硬盘。因为实际需求决定了星之间没有太多物理关联,因此几乎不做连接操作。介于此,既可以将所有的星存储到一个物理表文件中,又可以将每个星单独建表。单独建表的开销很高,但查询单颗星的光变曲线的效率很高,反之亦然。本文设计一种星表簇存储结构将某些星聚合为大表,兼顾存储与查询。因为星表簇结构的存在,对星光变曲线的查询,需要解析为对星表簇文件的搜索和查询。





