摘 要: 建立我国国内生产总值的时间序列模型,预测国内生产总值的变化趋势,为政府制定相关经济政策提供依据。分别收集1999年~2019年我国国内生产总值的年度数据,经过数据预处理、模型识别、参数估计、模型诊断和优化等分析手段,建立相应的时间序列模型,并对模型给出合理解释。利用构建的最优模型对我国国内生产总值进行5期预测分析,并提出相应建议。我国国内生产总值可用ARIMA(1,1,1)模型进行拟合。利用所得模型能够合理解释数据,并预测未来我国国内生产总值数额,为制定相关政策提供建议和依据。
关键词: 国内生产总值; 时间序列分析; ARIMA模型; 预测分析;
国内生产总值(Gross Domestic Product,简称GDP)是指在一定时期内(一个季度或一年),一个国家或地区的经济中所产出的全部最终产品和劳务的价值,常被公认为衡量国家经济状况的最佳指标。它不但可反映一个国家的经济表现,还可以反映一国的国力与财富。
国内生产总值是评价我国经济发展的一个重要指标,因此,本文利用1999年~2019年我国国内生产总值的年度数据,运用时间序列分析建模的方法,建立相应的时间序列模型,并对模型给出合理解释。同时,利用构建出来的最优模型对我国国内生产总值进行短期预测,并提出发展建议,为提高我国经济发展提出建议。
一、资料与方法
(一)数据资料
数据来源于国家统计局官网,网址为http:∥data.stats.gov.cn/easyquery.htm.cn=C01。根据该网站公布的数据,收集到了1999年~2019年的我国国内生产总值年度数据。
(二)分析方法
国内生产总值年度数据具有明显的时间序列数据的标志,因此,运用时间序列的方式进行建模并分析。根据数据特征,选择ARIMA模型进行建模。ARIMA模型全称为自回归积分滑动平均模型(Autoregressive Integrated Moving Average Model,简记ARIMA),其一般形式为ARI-MA(p,d,q),其中p表示自回归阶数,d表示差分次数,q表示移动平均阶数。
该方法建模的步骤:(1)数据预处理。将数据按照时间顺序整理,并绘制时序图和自相关图。通过时序图可初判断数据的平稳性。通常情况下,平稳序列的时序图表现为在某一常数附近作有界波动,而自相关图会出现自相关系数迅速衰减到零的现象。然后对序列进行白噪声检验。若序列为白噪声,说明序列值之间没有相关关系,这样的序列不符合建模标准。(2)数据平稳化。首先,对于具有确定性趋势的非平稳数据,提取确定性趋势项;对具有随机性趋势的非平稳数据作低阶差分,提取随机趋势。其次,对提取趋势信息之后的数据进行白噪声检验。通常,提取趋势信息之后的数据是平稳的,可用ARMA模型拟合。但是在实际操作中,如果趋势信息没有被完全提取,也会有其他情况出现。(3)模型识别。绘制平稳序列的自相关图和偏自相关图,根据拖尾和截尾的情况,估计自回归阶数p和移动平均阶数q的值。(4)模型估计。又称口径拟合,需要对模型中未知参数进行估计。(5)模型检验。首先对数据拟合的残差进行白噪声检验。如果检验结果不是白噪声,那么模型检验没有通过,需要返回(2)或(3)重新开始;如果检验结果为白噪声,那么进一步对所估参数进行显着性检验,去掉不显着的参数,获得精简模型。(6)模型优化。如果多个模型通过检验,那么依据信息量最小原则,选取最优模型。(7)预测。根据最优模型给出线性最小方差预测。
二、数据结果
(一)数据预处理
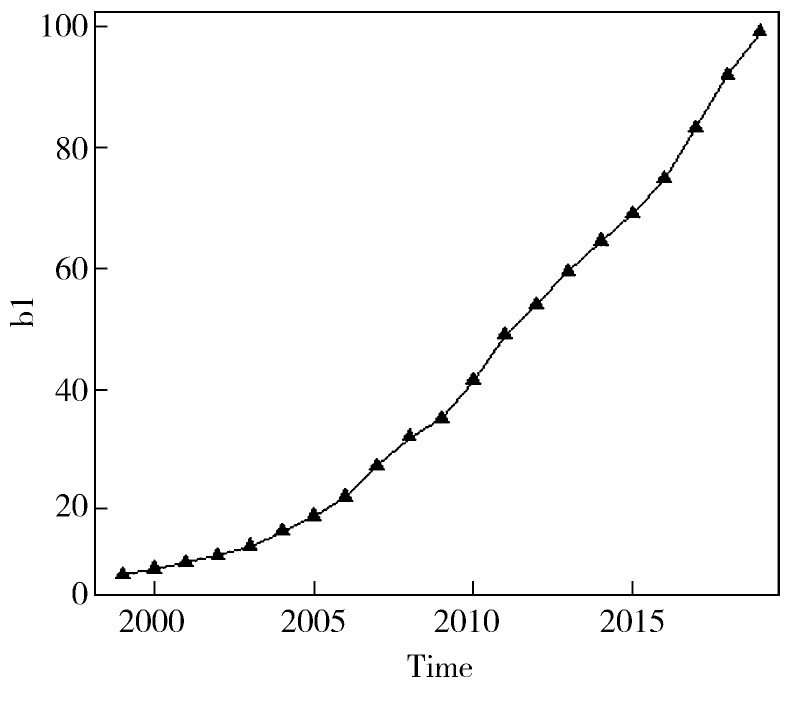
根据我国国内生产总值1999年~2019年的年度数据(单位:万亿元)绘制时序图见图1。根据时序图可以看出来该数据具有明显的递增趋势,不符合平稳性数据的特征,需要将此数据进行平稳化处理。
图1 时序图
(二)数据平稳化
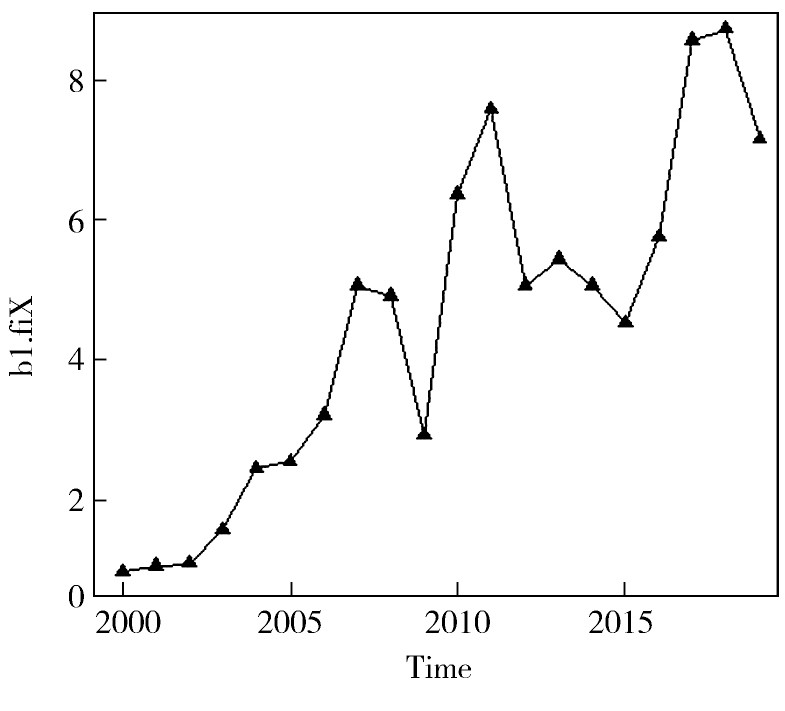
将我国国内生产总值数据进行一阶差分,结果表明一阶差分后的序列为非白噪声,一阶差分时序图见图2。由图2可知,经过一阶差分之后,原序列的线性趋势被提取,此时可确定ARIMA模型中的d值为1。
图2 一阶差分时序图
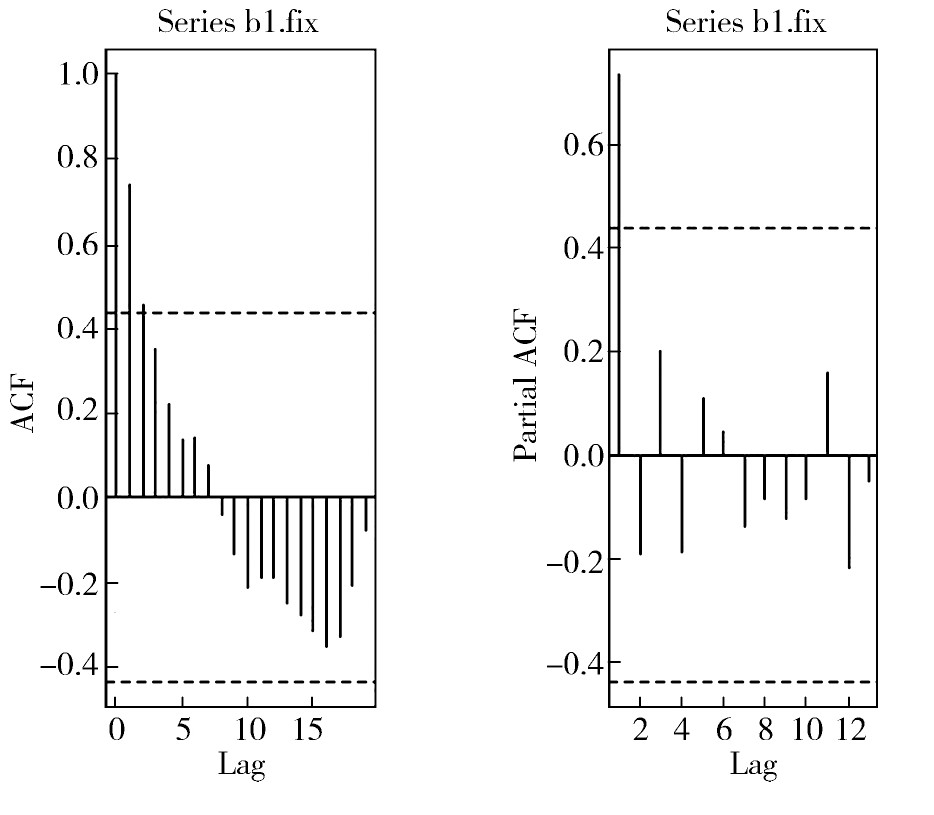
(三)模型识别
根据图3可以将我国国内生产总值的模型识别为ARIMA(1,1,1)。
图3 自相关图和偏自相关图
(四)参数估计、模型检验及优化
将模型识别为ARIMA(1,1,1)后,使用条件最小二乘法对未知参数进行估计,根据结果可以确定该模型的口径。
然后,对该模型的残差进行检验,通过检验。为了防止数据的随机性造成模型识别的偏差,可在不同视角下选择多个备选模型。为此,提供备选识别模型:ARIMA(0,1,2)和ARIMA(1,1,2)。但是由于备选模型并未通过检验,所以可以认为ARIMA(1,1,1)就是最优模型。
(五)预测
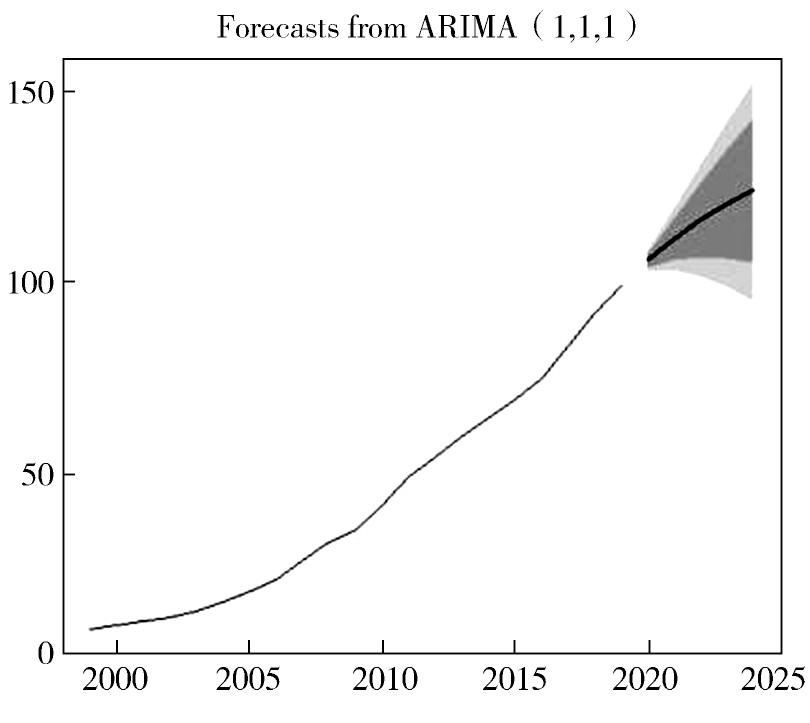
根据最优模型ARIMA(1,1,1)进行五期预测,并给出预测的80%和95%的置信区间,并绘制预测图。预测结果如下,预测见图4。
图4 我国国内生产总值预测图
三、结语
(一)数据结果
根据数据可以看出,我国国内生产总值一直呈现递增态势,并随着时间的推移,增长幅度也在逐年增大。同时,模型预测结果也验证了这一观点。国内生产总值是一个国家经济水平的最好象征,说明我国经济发展长时间呈现较好的发展态势,在未来将持续保持这种发展状态。因此,我国国内生产总值发展情况较好,呈现逐年递增状态。
(二)总结
本文综合使用了ARIMA、趋势拟合等手段完成建模与分析,短期预测效果突出,便于操作。在建模的过程中,从数据本身出发寻找合适的模型,从而保证了模型与数据有较好的拟合效果,为后续的统计分析提供了方便。
参考文献
[1]Massimiliano Giacalone,Raffaele Mattera,Eugenia Nissi.Economic indicators forecasting in presence of seasonal patterns:time series revision and prediction accuracy[J].Quality&Quantity,2020,54(1).
[2] 白晓东.应用时间序列分析[M].北京:清华大学出版社,2017.





