摘要:科学施政的前提是正确评估政策。近年来, 计量经济学方法被广泛应用于公共政策效果评估, 但时常被误用, 这会得出错误的政策评估结论, 进而误导政策制定者。为了避免这一问题, 研究者需要准确把握各类公共政策评估方法的适用前提和技术要点。赛鲁利 (Cerulli, 2015) 的《社会经济政策的计量经济学评估:理论与应用》一书系统介绍了公共政策效果评估的各种计量经济学方法的适用前提和范围, 可为研究者提供相关知识补充和应用参考。本文基于这一著作, 对常见的公共政策评估方法进行了对比和归纳, 期望对相关政策评估研究有所裨益。
关键词:社会经济政策; 政策评估; 计量经济学;

On the Application of Econometric Method in Public Policy Evaluation
YUAN Deyu SONG Xiaoning
University of International Business and Economics Sun Yat-sen University
Abstract:
The prerequisite for scientific governance is the correct assessment of policies. In recent years, econometric methods have been widely used in the evaluation of public policy effects, but they are often misused, which leads to wrong policy evaluation conclusions, and thus misleads policy makers. In order to avoid this problem, researchers need to accurately grasp the premise and technical points of various public policy evaluation methods. Econometrics Assessment of Social and Economic Policy: Theory and Applications (Cerulli, 2015) introduces the applicable premises and scope of various econometric methods for public policy effectiveness assessment, which can be provided to researchers for related knowledge supplements and application references. Based on this work, this paper compares and generalizes common public policy assessment methods to benefit from relevant policy evaluation research as expected.
Keyword:
Socio-economic Policy; Policy Evaluation; Econometrics;
一、引言
(一) 运用计量经济学方法评估公共政策效果的重要意义
科学施政是政府行政的基本需求。公共政策的实施直接影响千家万户, 错误或有偏差的公共政策轻则浪费巨额财政资金, 重则造成产业停滞、大量失业甚至系统性金融风险等。要避免这种灾难性后果, 要求公共政策的制定、实施、评价和调整, 都需要有科学依据。
制定公共政策需要科学依据, 这需要运用科学有效的方法, 评估出已实施的同类政策的效果, 包括国内外各种政策实践的各种短期和长期效果。传统的公共政策评估运用定性和简单的定量分析方法, 这些方法的科学性不足。现代常见的公共政策评估的科学方法有模拟仿真法、实验法和计量经济学方法。模拟仿真法在宏观经济模型中运用较多, 实验法的应用范围极小, 只有计量经济学方法运用最广。
计量经济学方法成为主流的公共政策评估方法, 为科学施政做出了重大贡献。但是, 如果不正确地使用计量经济学方法进行评估, 往往易误解公共政策的效果, 可能会把一些本来不属于公共政策的缺陷或作用强加于之, 从而使研究者和政府部门对公共政策的认识更加偏离其真实面目 (贾文, 2003) 。因此, 正确使用评估公共政策效果的计量经济学方法对科学施政具有重要意义。
值得强调的是, 我国尤其需要运用计量经济学方法来评估公共政策。原因在于, 改革已经进入深水区, 不断出台一系列推进改革的公共政策, 例如“营改增”、国有企业混合所有制改革、精准扶贫等。这些政策效果如何?哪些政策条款发挥作用了?对哪些企业和地区发挥作用了?回答了这些问题才能不断调整政策来推动改革的深化。过往的不少研究对这些问题的回答很容易流于泛泛之谈, 缺乏足够的科学依据, 亟须依据科学的方法来评估政策效果, 为制定深化改革政策提供依据。
(二) 目前公共政策评估计量方法运用方面存在的问题
当前部分研究者关于计量经济学方法运用的恰当性和有效性方面存在着较严重的问题。具体而言, 主要表现在两个方面。
一是计量经济学方法的滥用。运用计量经济方法的主要目的在于利用计量经济学模型对经济现象和规律进行描述和分析, 通过实证回归来验证或反驳某种观点或理论假设。如果计量经济学偏离这一目的, 即为滥用。目前, 计量经济方法滥用主要表现为两种情况:首先是简单问题复杂化。在一些期刊发表的文章中, 一些仅涉及较为浅显的经济现象, 但研究者却费尽心思构建复杂的计量经济模型和运用所谓“前沿”计量经济方法来分析, 以此来展示研究水平和吸引眼球。其次是模型设定随意化。在公共政策的评估中, 计量经济学模型要基于一定的经济学理论 (理论机制) 来设定, 即放入计量经济模型中的解释变量, 不管是主要解释变量还是控制变量均应具有相应的现实经济含义。相反, 如果在设定计量经济学模型时随意加入变量, 变量选择缺乏充分的经济含义, 将导致计量经济学方法的滥用。
二是不考虑计量经济学方法适用前提的误用。任何计量经济方法的运用均具有一定的前提假设和适用范围。例如, 普通最小二乘法 (OLS) 要严格满足线性模型、随机抽样、条件均值为0和误差同方差等前提假设 (Greene, 2012) ;针对违反普通最小二乘法 (OLS) 估计方法适用前提的内生性问题, 研究者通常使用工具变量法 (IV) 解决。这种方法的适用前提是需要找到一个或者多个工具变量与内生解释变量相关而与因变量无关;这里面尤其要注意弱工具变量问题, 即工具变量与内生解释变量弱相关。这是因为, 弱工具变量导致局部平均处理效应 (LATE, Local Average Treatment Effect) , 进而有可能会使工具变量法估计的系数被扩大。姜纬 (Jiang, 2017) 认为, 在弱工具变量的情况下, 工具变量的采用有可能造成只衡量了处理组一部分个体的平均处理效应 (Average Treatment Effect, ATE) , 而非处理组的平均处理效应;相比于OLS回归, 弱工具变量的运用会使得估计参数平均扩大了九倍, 这一发现是针对三大金融学顶级期刊A中255篇运用工具变量进行回归估计的论文进行的研究。双重差分法 (DID) 在公共政策评估中运用最多, 这种方法的适用前提是实验组和对照组具有相同时间趋势。如果两组不具有相同时间趋势, 就难以分清实验组在政策实施前后变化的原因究竟是政策作用还是自身趋势。只有在满足这些条件和范围时, 运用相应的计量经济学方法才能进行正确的系数估计, 得出的公共政策评估结果才正确。否则, 得出的评估结果要么高估、要么低估政策效果, 进而导致政策力度错误的加大和降低, 从而造成政策的误用。正如王美今和林建浩 (2012) 所言, “不顾计量经济学方法的假设前提和适用范围而机械套用或随意适用, 均可能会导致‘无知者无畏’的计量方法的错用和误用”。
总之, 无论是计量经济学方法的滥用还是误用, 均会导致公共政策评估的偏差, 进而可能对现实公共政策制定产生不良影响或者误导。为了避免上述问题, 需要研究者认真学习公共政策效果评估的计量经济学方法, 通晓这些方法的前提假设、适用范围和技术要点。意大利计量经济学家吉奥范尼·赛鲁利 (Giovanni Cerulli) 2015年出版的著作《社会经济政策的计量经济学评估:理论与应用》 (Econometric Evaluation of Socio-Economic Programs:Theory and Application, 以下简称《计量经济学评估》) 可作为众多研究者正确使用政策评估的计量经济学方法的重要参考资料和系统学习手册。
二、《计量经济学评估》一书简介
(一) 本书背景和内容简介
《计量经济学评估》一书作为国际计量经济学大师巴蒂·巴尔塔基 (Badi Baltagi) 和洪永淼、加里·库普 (Gary Koop) 等主编《理论和应用计量经济学前沿研究》的第49辑, 由斯普林格出版集团 (Springer) 于2015年出版发行。这本书不仅涉及公共政策评估计量方法的理论探讨, 而且还给出了基于当前最为流行软件包STATA的具体应用。
《计量经济学评估》全书共分为四章:第一章主要介绍公共政策评估计量经济学方法的统计学基础和基本假设, 提出与处理效应相关的样本选择偏差的概念和分类, 并对不同选择偏差给出校正方法。第二章主要介绍在可观测变量选择 (Selection on Observables) 或可见偏差 (Overt Bias) 假设下平均处理效应的估计方法, 并对这一假设在公共政策评估分析中的意义和适用范围做出了系统性说明;在这一章还具体介绍了回归校正法 (Regressionadjustment) 、匹配法 (Matching) 、复权法 (Reweighting) 等政策评估的常用方法。第三章介绍了不可观测变量选择 (Selection on Unobservables) 或不可见偏差 (Hidden Bias) 假设下的平均处理效应的估计方法。这一章具体介绍了工具变量法 (Instrumental Variables) 、模型选择法 (Selection Models) 和双重差分法 (Difference-in-Difference, DID) 等三种适用不可见偏差假设的计量经济学方法。第四章主要介绍了局部平均处理效应 (LATE) 和断点回归法 (Regression Discontinuity Design, RDD) 两种关系紧密的近似准实验估计法 (Nearly Quasi-experimental Methods) 。其中, 将后者分为清晰断点回归 (Sharp RDD) 和模糊断点回归 (Fuzzy RDD) 。两类方法的区分取决于公共政策的断点划分对个体影响的确定性差异, 政策对个体有确定性影响的是清晰断点回归, 对个体有不确定影响的叫模糊断点回归。
(二) 总体评价
《计量经济学评估》一书尽管只分了四章内容, 但其整体逻辑结构清晰、系统性强, 几乎集合了公共政策效果评价所需用的所有常用方法。这本书内容丰富, 知识层次性强, 其具体内容通常基于某一基本假设展开, 层层推进。不仅侧重公共政策计量评估模型构建的理论探讨, 而且也特别注重这些计量方法的应用与实现。与很多传统微观计量经济学教材相比, 《计量经济学评估》一书具有较强的政策研究针对性和可操作性, 可作为研究者正确利用现代微观计量经济学技术进行公共政策评估的指导手册。
此外, 《计量经济学评估》一书还具有相当的前沿性。当前的经济学经验研究正在从基本的统计上的假设检验转向因果推断, 这种转变甚至被称为“以实验设计为基础的计量经济学”或计量经济学的“实验学派” (Angrist et al., 2017) 。社会科学研究进行因果推断的最大难题是非随机抽样。公共政策所运用的群体通常也非随机抽样, 群体特征与其他群体明显不同。如何有效地区分政策效应和自选择效应, 成为公共政策评估面临的最大难题之一。这也就要求评估公共政策效果所用的计量经济学方法与其他一般性地分析个人和企业问题所用方法之间的较大差异。这本书前瞻性地为公共政策评估提供了计量经济学知识框架, 弥补了一般计量经济学教材在公共政策评估领域叙述的不足。
三、《计量经济学评估》一书的启示:各种计量经济学方法的选择与运用场景
(一) 公共政策评估应准确把握计量经济学方法选择要点
公共政策种类多种多样, 且每种公共政策的实施环境, 如时间、地点、人群等也不尽相同。这就要求研究者在对公共政策效果进行评估时, 需要准确地把握每种计量经济学评估方法的特征和适用前提, 以尽可能准确地评估出公共政策效果, 不高估不低估, 更要避免犯谬误相关这样的统计学错误。进行政策效果的评估以及政策产生作用的机制分析, 对于政策的调整和推广具有重要的现实意义。《计量经济学评估》一书为选择合适的公共政策计量经济学评估方法, 得出正确的评估结论提供了全面的指导。
赛鲁利 (Cerulli, 2015) 认为, 要选择一个合适公共政策计量经济学评估方法, 通常主要把握三个方面:第一, 弄清公共政策实施的制度背景和政策内容, 再与相应计量经济学评估方法的标准要求相对比或匹配;第二, 弄清公共政策实施对相关利益主体的影响机制, 构建具有实际经济含义的计量经济学模型;第三, 将公共政策的影响效应区分为直接效应和潜在间接效应。此外, 对于有限的计量经济学评估方法和模型, 还有一些更为严格的要求, 比如, 要基于公共政策的预定目标设计模型, 要有详细或有效的可用数据, 要对广泛的受益和非受益群体做对比等。
公共政策效果评估, 实际上就是要估计出或计算出公共政策的处理效应。然而, 现实是复杂的, 评估面临重重困难, 比如我们经常遇到观察值缺失、可观测和不可观测偏差、内生性和数据可得性等问题。因此, 研究者要处理出相对可靠的处理效应结果, 就需要很好地应对上述那些棘手的问题。赛鲁利 (Cerulli, 2015) 认为, 对于不同的公共政策运行环境, 研究者可以从三个维度去构建和选择计量经济学评估模型和方法, 即识别假设、模型类型和数据结构 (如表1所示) 。
表1 不同公共政策实施环境的计量经济学评估模型的选择
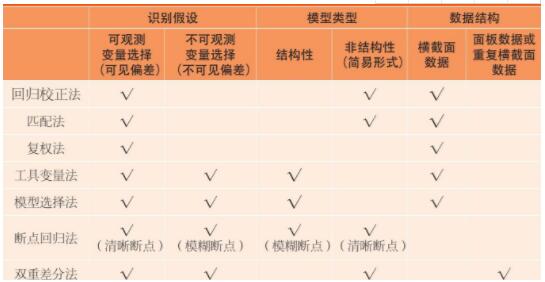
资料来源:赛鲁利 (Cerulli, 2015) , p.38。
1. 识别假设
在识别假设下, 通常我们将影响偏差识别的原因分为两种:可观测变量选择 (形成可见偏差) 和不可观测变量选择 (形成不可见偏差) , 以此来选择适用的计量模型。根据赛鲁利 (Cerulli, 2015) , 回归校正法、匹配法和复权法适用于可观测变量选择的情况, 工具变量法、模型选择法和双重差分法适用于不可观测变量选择的情况。断点回归法因其基于局部实验进行估计, 故既可以适用于可观测选择情况, 也适用于不可观测情况。具体而言, 清晰断点设计适用可观测变量选择情况, 模糊断点法适用不可观测变量选择情况。
2. 模型类型
在对公共政策进行计量经济学评估时, 通常可采用结构性模型和非结构性 (简易形式) 模型两大类。然而, 不同计量经济学评估方法, 却在不同形式模型下具有其特定的适用性。根据赛鲁利 (Cerulli, 2015) , 如表1所示, 工具变量法和模型选择法只适用于结构性模型;而回归校正法、匹配法、双重差分法则仅适用非结构性 (简易形式) 模型;断点回归法对于这两类模型均可适用, 其中模糊断点回归法适用于结构性模型, 清晰断点模型适用于非结构性 (简易形式) 模型。
3. 数据结构
对于公共政策计量评估所使用的数据主要有两类:横截面数据和面板数据。赛鲁利 (Cerulli, 2015) 认为, 在上文所列的七种方法中, 仅双重差分法适用于面板数据或重复横截面数据, 而其他估计方法均适用于一般横截面数据 (如表1所示) 。在实际运用中, 相比于横截面数据, 尽管面板数据能够反映时间维度上的政策效应变化, 但因其数据不易获得, 研究者们更多地使用横截面数据。
(二) 公共政策评估的各种计量经济学方法适用前提和应用场景
对于不同计量经济学评估方法, 均具有其各自的技术关键点, 公共政策评价者只有准确把握这些关键点, 才能有效避免计量经济学评估方法误用现象的发生。在本部分中, 我们遵循《计量经济学评估》一书章节顺序, 对不同计量经济学方法进行评价并总结其应用前提和场景。
1. 回归校正法
这是一种广义估计处理效应的一种方法, 基于可观测变量选择的识别假设。实际上, 这种方法仅在条件独立假设 (Conditional Independence Assumption, CIA) 下才适用。通常我们可以使用参数和非参数方法估算出处理效应的大小, 但这两种处理方法各有利弊。数据稀疏 (Sparseness) 情况下非参数估计结果要比参数估计结果更可靠, 而非参数估计却又很难克服因为弱重叠 (Weak Overlap) 问题而带来的识别问题。因此, 对于回归校正法而言, 使用参数估计还是非参数估计取决于现有数据的稀疏和重叠问题。
2. 匹配法
匹配法是当前在非实验环境下评估处理效应最为常用的方法之一 (Stuart, 2010) 。从技术上说, 匹配法是直接利用可观测结果, 而不是使用可观测条件均值进行估计的回归校正法。相比于控制函数回归法 (Control Function Regression, CFR) A, 匹配法具有三个优点:一是有很多具体匹配方法可供选用, 以通过比较获得相对稳健的结果;二是可以为处理组找到一个特征相近的对照组, 以获得相对准确的处理效应估计;三是匹配原理较为简单, 即通过非处理组找到处理组在相反状态下的潜在结果。具体实施过程中, 需要注意以下四个方面的问题。
(1) 关于处理效应的识别。匹配法可以很好解决弱重叠和弱平衡性 (Weak Balancing) 的问题, 但不能消除不可观测变量选择偏差问题。匹配法要能识别出处理效应, 通常要基于三个假设:一是条件均值独立假设, 即E (Y0|x, D) =E (Y0|x) 和E (Y1|x, D) =E (Y1|x) ;二是重叠性假设, 即0<p (x) <1, 其中p (x) 为倾向得分;三是平衡性假设, 即匹配后处理组与控制组的协变量分布相同。
(2) 匹配估计量的大样本特征。匹配法作为一种特殊的非参数回归校正法, 其获得非观测结果的方法使其渐进性质的识别成为问题。仅有一些匹配方法符合大样本渐进性质, 这其中主要包括核匹配 (Kernel Matching) 和近邻匹配 (Nearest-neighbor Matching) 两种方法。核匹配法在特定条件下的估计量可以满足N-1/2渐进一致性, 但并不满足有效性B;近邻匹配法的估计量不仅可以满足一致性和渐进正态分布, 还可以满足有效性。
(3) 精确匹配与维度问题。通常情况下, 我们可以采取精确匹配方法来实现匹配, 但这仅限于协变量维度较少时。如果协变量维度较多, 而样本容量又较小时, 精确匹配将变得不可行, 即所谓的维度问题 (Dimensionality Curse) 。为了克服这一问题, 罗森鲍姆和鲁滨 (Rosenbaum and Rubin, 1983) 建议将多维协变量转换为倾向得分这一单一维度进行匹配。
(4) 倾向得分匹配。在运用倾向得分匹配法时, 有两个特别重要的特性:平衡性 (Balancing) 和无混淆性 (Unconfoundedness) 。前者是在给定倾向得分p (x) 的条件下, 处理变量D与其他变量x是独立的, 这一特性表明了当倾向得分被正确处理后, 按照倾向得分划分匹配个体和按照协变量x划分匹配个体是无差别的。因此, 在实证研究中检验平衡性是否成立, 是检验倾向得分是否正确地用于划分匹配个体的重要标准。无混淆性是指, 给定p (x) , 处理变量D对于潜在结果的影响是可以忽略的, 这一特性是否成立是检验是否穷尽协变量x的标准。倾向得分匹配法 (PSM) 在研究中被广泛应用, 但需要注重其适用性和缺陷:一是PSM需要比较大的样本容量才能实现高质量的匹配;二是PSM要求处理组与控制组之间要有共同的取值范围 (重叠性) , 否则可能丢失较多观测值, 导致匹配成功变量较少;三是PSM虽然控制了可观测变量, 但仍然可能存在非观测变量选择问题, 仍存在不可见偏差。
3. 复权法
复权法是在可观测变量选择情况下估计处理效应的一种有效方法, 与上文的倾向得分匹配法之间有着密切关系。复权法的基本原理是:由于处理组个体不是随机分配的, 处理组个体和控制组个体之间可能呈现着非常不同的特征, 这样也可能导致协变量x出现不平衡分布。为了构建平衡的协变量分布, 通常针对不同观测值赋予适当权重并且运用加权最小二乘法估计平均处理效应。相比于其他公共政策计量评估方法, 复权法不依赖于对潜在结果m1 (x) 和m0 (x) 的估计, 而仅依赖于倾向得分p (x) 的估计。但这种方法也有一定限制, 因为复权估计量对倾向得分估计方程设定较为敏感, 如果方程设定存在问题, 可能会导致严重的估计偏差。
4. 工具变量法
工具变量法是处理不可观测变量选择 (不可见偏差) 而引起内生性问题的最有效方法之一。应用工具变量法, 首要的是能找到至少一个工具变量, 其要与处理变量D直接相关, 但又不能与因变量 (结果) Y相关。通常情况下, 我们可以选择二阶段普通最小二乘法、Probit (或Logit) 最小二乘法和Probit (或Logit) 二阶段最小二乘法作为工具变量法运用的具体回归方法。但需要注意的是, 第一种方法若遇到弱工具变量问题, 会降低处理效应回归结果的精确度, 但仍然是满足一致性的;第二种方法基于处理变量D的Probit或Logit回归量对选择方程进行回归, 其处理效应回归结果相比第一种方法具有更好的有效性, 但需要依赖Probit或Logit回归方程的正确设定;第三种方法回归并不具有第二种方法的依赖性, 即使Probit或Logit回归方程设定不正确, 仍能满足一致性, 但在一定程度上损失了有效性。此外, 我们在运用工具变量法时, 要特别注意弱工具变量问题, 即工具变量与因变量Y之间不完全外生或与处理变量之间的相关性较差, 这可能导致处理效应的回归结果不一致和较差的有效性 (Bound et al., 2005) 。
5. 模型选择法
模型选择法作为处理数据截断或不可观测变量选择问题的一种方法, 近年被逐渐广泛应用于公共政策的效果评估中 (Cerulli, 2015) 。在对选择模型进行回归时, 由于不同的不可观测变量之间可能存在相关性, 这会导致处理效应估计出现偏差。要获得一致的处理效应估计, 通常要基于不同误差项之间的联合正态分布。在联合正态分布的假设下, 可以利用极大似然估计法, 这样可以获得一致且有效的参数估计量。但是, 一般情况下极大似然估计可能会面对收敛问题, 在回归方程存在离散控制变量时表现尤为突出 (Woodridge, 2010) 。这时, 采用两步法A可能是一个有效的校正方法。
6. 双重差分法
双重差分法也是一种处理内生性问题的有效方法 (Abadie, 2005;Angrist and Pischke, 2008) 。在应用中, 这种方法因不需像工具变量法那样需要寻找工具变量, 也不需像模型选择法那样附加严格的分布假设, 当前已经成为公共政策效果的计量评估中最重要、应用最广泛的方法。双重差分法适用于处理组和控制组在公共政策执行前后的数据均可得的情况, 其基本原理是在公共政策执行前为处理组个体找到相同或相似的非处理组 (控制组) 个体, 以这些非处理组个体在政策实施时点后的结果作为处理组个体在未进入处理组时的潜在结果参照, 通过对比得到公共政策的处理效应。为了获得处理组个体的潜在结果, 通常我们要基于可得的协变量考察处理组和控制组个体之间是否具有共同趋势 (Common Trend) 。相反, 如果处理组和控制组之间不具有共同趋势, 将会严重影响处理效应回归结果的准确性。
7. 断点回归法
断点回归法是另一种准自然实验的估计方法, 近年经常出现在公共政策因果效应评估的文献中。断点回归法适用的基本条件是:存在一个驱动变量 (Forcing Variable) , 以其某一取值作为门槛划分处理组和非处理组个体。在门槛值之上的个体进入处理组, 门槛值之下的个体进入非处理组。门槛值的取值处会出现政策断点, 通过选择适当的门槛值临界区间, 比较处理组和非处理组因变量的平均值, 即可获得公共政策的处理效应。根据政策变量与驱动变量之间是确定关系还是随机关系, 可以将断点回归法分为清晰断点法和模糊断点法, 前者的处理变量会在门限值处出现严格的“跳跃”, 而后者则只形成了模糊的“跳跃”。断点回归法在具体应用中, 通常需要符合四个前提:一是准确识别断点。准确识别的一个标准是在门槛值附近是否符合自然实验的随机抽样标准, 具体可以计算政策变量D和协变量x在门槛值左右两侧的差别。通常可以接受的断点为政策变量D在门槛值两侧具有明显差异, 而协变量x在门槛值两侧的差异不显著。二是断点不能被人为操控, 即不能通过人为修改门槛值来改变断点的位置。三是最优带宽的选择。带宽的选择实际上涉及估计精度和估计偏差的平衡。因为带宽越大, 回归可用的观测值越多, 可以提高回归的有效性, 但同时偏离门槛值较远的个体也就越多, 增加了估计偏差。具体可以利用插入法 (Plug-in) 和交叉验证法 (Cross-validation) 获得最优带宽A。四是额外协变量选择。一个变量是否能够作为协变量进入回归方程, 其标准是在门限值处不会出现统计上显著的断点。
四、总结
科学施政在当前“三期叠加”B的经济新常态下显得尤为重要, 关乎全面深化改革的成败和中华民族的伟大复兴。科学施政的前提是科学评估以往各种改革政策的效果, 为政策调整提供决策依据。系统性地评估改革开放以来的各种改革政策, 也可以为我国道路自信、制度自信和理论自信提供现实基础。
近三十年来, 计量经济学方法被广泛应用于公共政策效果的评估中。然而, 在这项工作中, 计量经济学方法和模型经常出现被滥用和误用的现象, 这可能会得出错误的政策效果评价, 会误导政策制定者继续推行甚至出台贻害百姓的“劣政”和“恶政”C。为了避免这一问题, 研究者需要系统学习并且要准确把握各类公共政策计量经济学评估方法的适用前提和技术要点, 力求得出正确的政策评价结论。赛鲁利 (Cerulli, 2015) 的《社会政策的计量经济学评估:理论与应用》一书系统介绍了公共政策评估的各类计量经济学方法, 如回归校正法、匹配法、复权法、工具变量法、模型选择法、双重差分法、断点回归法等, 不仅介绍了这些方法的适用前提和适用范围, 而且说明了基本统计学原理和软件运用, 很好地填补了公共政策评估计量经济学著作的空白, 可为研究者提供很好的应用参考。这本著作必将为研究者科学地评估我国各种改革政策的效果提供帮助, 从而为政府制定政策提供智力支持。
参考文献
[1]贾文:“认识计量经济模型应走出五大误区”, 《财经科学》2003年第3期。
[2]王美今、林建浩:“计量经济学应用研究的可信性革命”, 《经济研究》2012年第2期。
[3]Abadie, A., 2005, Semiparametric Difference-in-Differences Estimators, Review of Economic Studies, 72:1-19.
[4]Angrist, D., and Pischke, S., 2008, Mostly Harmless Econometrics:An Empiricist’s Companion.Princeton:Princeton University Press.
[5]Angrist, J., Azoulay, P., Ellison, G., Hill, R., and F., Lu, 2017, Economic Research Evolves:Fields and Styles, American Economic Review, 107 (5) :293-297.
[6]Bound, J., Jaeger, A., and M., Baker, 1995, Problems with Instrumental Variables Estimation When the Correlation between the Instruments and the Endogenous Explanatory Variable Is Weak, Journal of the American Statistical Association, 90:443-450.
[7]Cerulli, Giovanni, 2015, Econometric Evaluation of Socio-Economic Programs:Theory and Application, Berlin:Springer-Verlag.
[8]Greene, H., 2012, Econometric Analysis (6th Edition) .Upper Saddle River, New Jersey:Pearson.
[9]Heckman, J., Ichimura, H., and P., Todd, 1998, Matching as An Econometric Evaluation Estimator, Review of Economic Studies, 6 (2) :261-294.
[10]Jiang, W., 2017, Have Instrumental Variables Brought Us Closer to Truth?Review of Corporate Finance Studies, 6 (2) :127-140.
[11]Stuart, A., 2010, Matching Methods for Causal Inference:A Review and A Look Forward, Statistical Science, 25 (1) :1-21.
[12]Wooldridge, M., 2010, Econometric Analysis of Cross Section and Panel Data.Cambridge, MA:MIT Press.
注释
1 金融学期刊 (Journal of Finance) 、金融经济学季刊 (Journal of Financial Economics) 和金融研究评论 (Review of Financial Studies) 。
2 控制函数回归法 (CFR) 是回归校正法的一种特殊形式, 通常事先假定要估计参数和模型形式 (比如线性形式) , 用于条件均值独立条件 (Conditional Mean Independence, CMI) 下公共政策估计中的处理效应识别问题。因此, CFR仅在可观测选择的识别假设下适用。
3 Heckman等 (1998) 对渐进线性回归条件下核匹配估计量的大样本性质进行了证明, 发现要使核匹配具有N-1/2渐进一致性, 除了样本需要满足条件均值独立假设、重叠性假设和独立同分布假设外, 还应满足平滑参数序列收敛、协变量分布密度的期望等于0等条件。
4 通常是基于一定方法, 如拔靴法 (Bootstrap) 等, 获得处理变量D关于1和协变量x的Probit方程估计误差, 以其作为第二步估计处理效应的协变量。
5 具体可参见Cerulli (2015) , pp.260-266。
6 增长速度换挡期、结构调整阵痛期和前期刺激政策消化期。
7 政策制定者的出发点也许是好的, 但结果可能是不好的。





