统计数据汇总是数据发布和数据分析研究的基础,也是统计工作者必不可少的一项工作技能。目前统计工作中数据汇总大体上有两种方式,一种是通过国家统计联网直报平台或其他数据报送平台定制的数据汇总表对调查数据进行汇总,这种汇总方式操作简单,快捷,但是汇总表是通过平台定制,汇总的分组和结构固定,灵活性不足。另一种途径是统计工作者根据工作需要,选取数据汇总软件,对企业或者个人报送的统计数据进行汇总。这种汇总方式灵活性大,时效性强,但是需要借助相应的数据汇总软件完成。
Stata 由美国计算机资源中心研制,是一套提供其使用者数据分析、数据管理以及绘制专业图表的完整及整合性统计软件。Stata 功能强大,相对简单易学,并且能够应对经济普查、人口普查等上百万条样本数据的汇总工作。本文就如何运用 Stata 完成统计数据汇总工作加以介绍。
合并数据文件
统计调查的原始数据经常存放在不同的数据文件里,比如,调查企业通过“调查单位基本情况表”上报企业所在地、登记注册类型等情况,通过 “财务状况表”上报财务相关指标。在数据汇总前,需要将两个数据文件进行合并,才能实现对财务指标的分地区、分行业等交叉分组汇总。最常用的合并方式有两种:
1. 数 据 文 件 的 横 向 合 并。 横 向合并是将两个数据文件的变量合并到一起,合并后数据样本不变 , 但变量数目增加,也就是数据文件变宽了。Stata 中只需指定合并序号变量,使用“merge”命令即可实现两个数据文件的横向合并。实际工作中,常把企业的组织机构代码(zzjgdm)作为序号变量。比如,将“调查单位基本情况(101-1表)”数据文件“jbqk.dta”和“财务状 况 表” 数 据 文 件“cwzk.dta” 按 照zzjgdm 合并的命令为:
use jbqk,clear
merge zzgjdm using cwzk
实 际 上,Stata 不 仅 可 以 将 两 个dta 文件合并,也可以直接读入 csv、txt 等格式的文件,完成数据合并。两个数据文件合并过程中,Stata 还自动生成了一个新的变量“_merge”,_merge 赋值为 1,2,3 中的一个。上例中,_merge 值为 1 代表该样本在“jbqk.dta”数据文件中,为2代表样本在“cwzk.dta”数据文件中,为3代表样本在“jcqk.dat”和“cwzk.dat”中同时存在。这样,通过 _merge 变量,我们就可以方便完成两个数据文件的比对。
2. 数据文件的纵向合并。纵向合并是把两个数据文件的样本加总在一起,合并后样本变量数目不变,样本数增加,也就是数据文件变长了。最常见的纵向合并情况是对一项调查在不同地区或者不同时间得来的数据进行合并。Stata 纵向合并数据文件的命令为“append”.比如,我们将调查得到的包含北京市调查数据的数据文件“bj.dta”和包含天津市调查数据的数据文件“tj.dta”纵向合并的Stata命令为:
use bj,clear
append using tj
需要注意的是,在纵向合并两个数据文件前,两个文件中相同变量的变量名要一致,否则将会被当成两个变量处理,并产生无用的缺失值。同时,相同变量的变量类型要一致。
汇总问卷调查结果
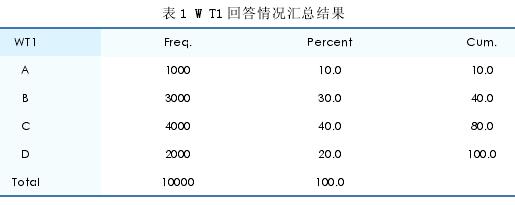
问卷调查时效性较强,调查结果容易量化,便于统计处理与分析,是常用的统计调查方法。问卷调查结果用 Stata 进行汇总非常方便,使用“tabulate”命令,可方便的生成列联表,根据变量的频数分布可以得到问卷回答情况的汇总结果。比如,对 10000个样本企业开展问卷调查,涉及 10 个问 题, 分 别 为:WT1,WT2, ……,WT10(每个问题的答案均为 A、B、C、D 四个选项)。汇总问题 WT1 的回答情况时,只需输入命令:tabulateWT1,即可得到 WT1 样本回答情况的频 数(Freq)、 百 分 比(Percent) 及累计百分比(Cum)指标(Stata 输出结果见表 1)。从 Freq 输出结果可见,样本企业对 WT1 的回答情况为:选择答案 A、B、C、D 的企业数量分别为1000、3000、4000 和 2000 个。Percent结果给出了选择答案 1、2、3、4 的比重分别为 10%,30%、40% 和 20%.
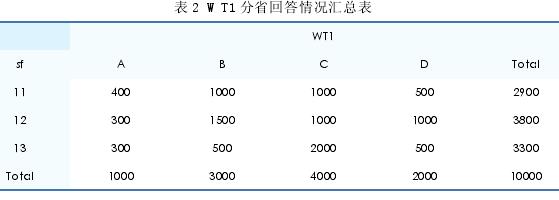
同 时,“tabulate” 命 令 还 可 以生成 2 维列联表,比如,需要对问题WT1 做分省回答结果的汇总时,只需对省代码(sf)和 WT1 执行“tabulate”汇总。Stata 命令为:tabulate sf WT1,即 可 输 出 表 2 格 式 的 汇 总 结 果{ 假设调查只涉及北京市(代码 11)、天 津 市( 代 码 12)、 河 北 省( 代 码13)}.
类似的,可以对每一个问题的调查结果分行业、分登记注册类型、分控股情况等做交叉分组汇总。
汇总生产经营情况调查结果
现行的统计报表制度更多的是对调查单位的生产经营情况开展年度、季度或者是月度调查。日常的数据汇总工作更多的是对生产经营指标做各种交叉分组汇总。
与问卷调查结果不同,生产经营情况的调查结果需要对调查指标数据加总或者通过计算生成新的指标,因此,我们首先要生成新的变量,来记录相应指标的汇总结果。Stata 生成新变量的命令为“generate”及其扩展命令“egen”.“generate”用来生成一般变量,“egen”可以生成包含函数表达式的变量。比如,我们对规模以上服务业企业“财务状况(F103 表)”中“营业收入”指标的本年(yysr1)和上年同期(yysr2)数据进行汇总,并计算两年的同比增速(d),用到的Stata 语句为:
egen a=sum(yysr1)
egen b=sum(yysr2)
gen d=(a/b)*100-100
其中:“sum()”为求和函数,变量 a 用来记录“营业收入”本年的合计数,变量 b 用来记录“营业收入”上年同期的合计数,变量d用来记录“营业收入”的同比增速。
统计调查表中通常包含多个指标,我们可以使用 Stata 的循环语句“forvalues”同时对多个指标汇总。比如,我们对规模以上服务业企业“财务状况(F103 表)”涉及的 31 个财务指标汇总。31 个指标的本年和上年同期数据我们分别用 ai 和 bi(i=1,2,…,31) 表示。汇总语句为:
forvalues i=1/31{
egen suma`i'=sum(a`i‘)
egen sumb`i'=sum(b`i’)
gen d`i'=(suma`i'/sumb`i‘)*100-100}
31 个指标的本年和上年同期汇总数据分别记录于 sumai 和 sumbi 变量,di 为同比增速(i=1,2,…,31)。
我们还可以用“by+ 变量名”实现各种交叉分组汇总。比如,分省汇总“营业收入”本年(yysr1)和上年同期数(yysr2)指标的 Stata 语句为:
by sf,sort:egen a=sum(yysr1)
by sf,sort:egen b =sum(yysr2)
其中:“sort”命令为排序命令,对省代码(sf)变量按照从小到大排序。在用“by”命令对变量进行分类汇总前,必须要对分类变量进行排序。运用“by+变量名”我们还可以进一步实现分行业分指标、分登记注册类型分指标及分省分行业等交叉汇总工作。比如,分省分行业大类汇总“营业收入”指标的语句为:
sort sf hydl :egen suma=sum(yysr1)
sort sf hydl :egen sumb=sum(yysr2)
综上可见,运用 Stata 语句,可以快速、灵活的完成统计数据的各种交叉汇总工作,为数据的审核及后续的分析研究工作带来便利。同时,Stata的数据汇总结果既可以以文本格式直接粘贴进 Word 等文字编辑器,也可以以表格的形式粘贴进 Excel 等数据表格处理器,便于存储和使用。