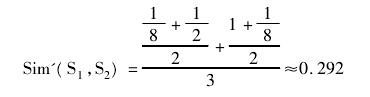【摘要】针对同义词识别方法中因重心后移造成的语义相似度计算偏差问题,提出一种基于句法结构分析的同义词识别方法。首先采用句法结构分析方法处理需要做同义词识别的词(或短语) ,然后基于同义词词林来计算词(或短语) 间的相似度。该方法等价地分析词(或短语) 中的各个原子词,从而消除重心后移方法所造成的识别偏差。实验证明,该同义词识别方法性能良好,具有较高的可行性,可以为文本挖掘和语义检索领域提供新思路。
【关键词】同义词识别 句法结构分析 文本挖掘。
1 引 言
当前的知识经济时代下,利用计算机提高组织的知识管理水平,必须有高效的文本挖掘方法和算法。文本挖掘在知识管理领域有广阔的应用前景,是管理学界的研究热点之一。同义词识别是进行文本挖掘的基础技术之一,其主要任务是: 对于给定的两个词(或短语) ,自动计算两者的语义相似度。
本文在分析中文同义词识别方法研究现状的基础之上,提出了一种新的同义词识别方法,引入句法结构分析方法,解决因语义相似度计算的重心后移所造成的同义词识别偏差问题。需要说明的是,本文的同义词识别均指中文同义词的语义相似度识别,包括中文词和短语的识别。
2 研究现状
中文同义词识别方法大体上可以分为两类: 基于汉语构词的识别方法和基于语义的识别方法。
(1) 基于汉语构词的识别方法的基础假设和主要思想是: 汉语构词的特征是意义相同或相近的词语大多包含相同的字; 且复合词的中心词一般在后面,中心词由复合词中的其他词素层层限定。国内对此方法的研究比较成熟,如文献[1,2]等。基于汉语构词的识别方法操作简便、识别效率尚可,是一种较为经济的方法。但是,这类方法往往强调构词的重心后移规律,限定了方法的适用范围,不能用来识别短句之间的语义相似度。
(2) 基于语义的识别方法比较成熟,应用也较广泛。刘群等[3]提出了一种基于 HowNet 的词汇语义相似度计算方法; 朱毅华等[4]基于语义计算词汇间的相似度,用来提高搜索引擎的检索效率; 王兰成等[5]和余刚等[6]改进了基于语义的识别方法,修改了词表结构,强调语义相同或相近的词或短语即可视为同义词; 穗志方等[7]利用同义词词林来计算词语间的语义相似度,主要解决表示主题概念的非规范词语向主题词转化过程中的词汇转化问题; 田久乐等[8]分析并利用同义词词林的编码结构特点,考虑词语的相似性和相关性,设计了一种改进的语义相似度识别方法; 于娟等[9]先把领域术语切分为原子词词素,然后利用同义词词林判断来自两个术语的词素是否都同义,从而判断领域术语是否同义等。以上文献分析词相关性或相近性特点,往往局限于同义词典的性能,且没有对基于语义的识别方法中因重心后移规律带来的同义词识别偏差问题进行改进研究。
为解决上述问题,对基于语义的同义词识别方法加以改进: 首先采用句法结构分析方法处理需要做同义词识别的词(或短语) ,然后基于同义词词林来计算词(或短语) 间的相似度。该方法等价地分析词(或短语) 中的各个原子词,从而消除了重心后移方法所造成的识别偏差。
3 方法描述
本文提出的基于句法结构分析的同义词识别方法,主要步骤是:
(1) 将要做同义词识别的词(或短语) 预处理为标准化文本,分别进行词语切分和词性标注处理,即依据词性和《哈工大停用词表》[10]去除那些不可能构词的词素(如"啊"、"哎呀"、"需要"等) ,生成标准化的文本;(2) 对标准化文本进行句法结构分析,建立文本依存关系集合,形成含信息结构的文本;(3) 对同义词词林做无用行删除处理,生成标准词林;(4) 把含信息结构的文本和标准词林作为输入,计算两个文本的相似度,并生成相似度集合。
该方法的框架如图 1 所示:
(1) 词语切分与词性标注处理模块遍历每一个文本,将其切分为单个词语,并在相应位置标注词性;(2) 句法结构分析处理模块对经过词性标注后的文本进行句法结构分析,生成含依存关系信息的文本;(3) 同义词词林清理模块首先遍历同义词词林,删除对同义词识别意义不大的行,然后寻找单个词语对应在同义词词林中的编码;(4) 语义相似度计算模块对经过句法结构分析的文本进行相似度计算。
4 方法实现
4.1 预处理。
该模块将初始输入的词(或短语) 标准化成统一的文本对,主要是去除图片、公式、数字等无法自动处理的元素,以及空行、换行符等无意义的符号,输出的标准文本中仅保留汉语字和标点符号。
本文对标准化文本的格式要求是半角标点符号统一改为全角符号,例 1 是初始输入的文本对,例 2 是经过预处理后的标准文本对,该文本对不具有特殊性。
例 1 "中国 1 进口@ 设备"与"国家引 进技术设备".
例 2 "中国进口设备"与"国家引进技术设备".
4.2 词语切分与词性标注。
该模块主要将文本进行词语切分,并标注每个词的一级词性,根据词性和《哈工大停用词表》[10]对文本进行过滤处理。词语切分是先扫描文本,将其切分为词语的自然语言处理技术。本文使用的是中国科学院计算技术研究所研发的 ICTCLAS 系统[11,12],该系统的分词正确率高达 97%.
经过分词与词性标注后,过滤处理分两步删除那些一般不参与组合成词的词素,输出结果为由构成词的词语组成的一组词串的集合对:
(1) 首先根据词语词性删除无法构词的词语,即将标注为特定词性的词删除。本文设定的特定词性包含量词、叹词等,具体参考文献[9],依据文献[9]中表 2 的特定词性,可以对例1 和例2 的文本对进行删除处理。
(2) 过滤处理,即将第(1) 步处理的文本对再依据《哈工大停用词表》,删除那些一般不构成词的词素,由此生成新的词素串的文本对。其中,《哈工大停用词表》中的词含有第(1) 步特定词性的词,也含有其他词性的词,如,作为(v) 、照(v) 、有关(v) 等。例 2 标准文本对经过该模块处理后生成标准纯文本对,如下所示:
例 3 "中国/n 进口/v 设备/n"与"国家/n 引进/v 技术/n 设备/n".
4.3 句法结构分析。
句法结构分析模块基于文法依存原理,根据文本词性来分析文本语言单位内成分之间的依存关系,揭示出其句法结构。本文认为: 句子中核心的词性是动词,动词是支配其他词性成分的中心成分,而它本身却不受其他任何词性成分的支配,并且与上下文环境无关,所有受支配成分都以某种依存关系从属于动词词性成分[13,14].
在这一模块,使用了哈尔滨工业大学社会计算与信息检索研究中心的中文依存句法分析方法[15],该方法能够深入分析语言的内部结构,并根据词性标注信息,从大规模依存树库中获取词汇依存信息,建立一个词汇化的概率分析模型,进而生成句子中的依存结构信息。利用该方法研究有标记依存弧的准确率为75% 左右,无标记依存弧的准确率为 80% 左右。
例 3 经过依存句法分析后,生成的依存结构分析结果如图 2 所示:
由图 2,加上关系集合为 DGL (D) ,< EOS > 为空顶点,则可以得出句法结构关系分别如下所示:
DGL (D) = { (引进,国家) ,(< EOS > ,引进) ,(引进,技术) ,(技术,设备) }
DGL (D) = { (进口,中国) (< EOS > ,进口) ,(进口,设备) }
4.4 同义词词林清理。
同义词词林是一部对汉语词汇按语义全面分类的词典,收录近 7 万词语。该部词典主要根据汉语的特点和使用原则,确定了词分类原则: 以词义为主,兼顾词类,并充分注意题材的集中,将词义分为大类、中类和小类三级,共 12 个大类。
同义词词林清理模块,从头到尾遍历同义词词林,并分两步删除无用行: 删除行编码含有"@ "的字符,表示这一行没有同义词存在; 删除行编码的第一个字母含有"J"、"K"和"L"的行,在同义词词林中,行编码的第一个字母含有"J"、"K"和"L"分别代表关联类、助语类和敬语类,这三类词一般不构成关键词。该模块将同义词词林生成为标准词林,具体举例描述如表1 所示:
将例 3 生成的关系集合 DGL(D) 中的每个词语在标准词林中找到对应的语义编码,如下所示:
DGL (D ) = { (Hi16B01,Di02A27 ) ,(< EOS > ,Hi16B01) ,(Hi16B01,De04B07) ,(De04B07,Ba05B01) }
DGL (D ) = { (Cb20D01,Di02A03 ) (< EOS > ,Cb20D01) ,(Cb20D01,Ba05B01) }
4.5 语义相似度计算。
上述模块将初始输入的文本对处理为含有语义编码的关系集合。本模块主要是根据语义编码来计算文本对的相似度。该计算方法的设计基于语义编码距离,计算公式如下:
该算法对于搭配对匹配的总权数有如下定义:
(1) 假设有两个有效搭配对: ① W1_ W2和② W1'_ W2',且两者语义距离最相近,有效搭配对语义距离计算过程主要是: 先选定主参照的一个搭配对,然后遍历参照文本块中的每一个搭配对,分别根据标准词林计算它们的评价语义距离值,选择值最小的作为这个搭配对的有效搭配对;(2) 如果 W1= W1'且 W2= W2'则搭配对①和搭配对②的匹配权重为 1,这里"= "表示意义相近和相关; 如果 W1、W1'和 W2、W2'意义都不相近也不相关,则取两者的语义距离之和的平均数作为匹配权重;(3) 如果 W1≠ W1'且 W2= W2'或者 W1= W1'但W2≠ W2',则搭配对①和搭配对②的匹配权重为 1 与另一对语义距离两者之和的平均数,否则原理同上。
同理,上述几点也适用于搭配对 ① W1_ W2_ W3和② W1'_ W2'_ W3',需要注意的是: 当其中对应一个位置意义等价,其余不等价时,两者的匹配权重为 1 与其余两对语义距离这三者之和的平均数; 当其中对应两个位置意义等价,其余不等价时,两者的匹配权重为2 与其余一对语义距离这三者之和的平均数,本文重点研究的是类似 W1_ W2和 W1'_ W2'这样搭配对的计算,出现三个词的情况比较少,对这种情况不做研究。
例 1 所示文本对的语义相似度利用本文的方法计算结果如下:
观察公式计算过程,可以看出本文提出的计算方法未引入重心后移规律的计算规则,而是在计算文本对相似度时,平等赋予各个词语权重。如此,能有效克服基于语义的同义词识别方法中的重心后移规律带来的同义词识别偏差问题。
5 实验结果及分析
目前国内尚未出现测评同义词识别方法的金标准。为验证本文提出的新方法的可行性和合理性,基于网络检索技术设计了一种同义词识别方法的实验系统,比较了基于汉语构词的识别方法[1](简称"汉语构词法") 、基于语义的识别方法[7](简称"语义方法") 和本文提出的基于句法结构分析的同义词识别方法(简称"本文方法") .该实验系统运行步骤为:
(1) 根据输入的主题句,通过网络检索系统(如Baidu、SOSO 等) 获取相关主题和对应的主题摘要;(2) 采用三种同义词识别方法分别计算主题及主题摘要与主题句的相似度值,并按值的降序显示;(3) 人工对显示出来的每条检索信息进行满意度评价,给出评价值,本文满意度评价分 4 个等级: 1 表示不相关,2 表示相关但不相近,3 表示相近,4 表示等价;(4) 综合平均相似度值和平均满意度值判断方法的性能。
其中,主题句与某一检索词条的相似度由主题句与主题的相似度、主题句与主题摘要的相似度两部分组成。假设主题语句与一检索词条的相似度值为SiMM,则: SiMM = aA1 + bA2,其中 A1 表示检索主题与主题文本的相似度值,A2 表示检索主题与主题摘要文本的相似度值,a 和 b 分别代表各部分的权重,本文设a 为 6,b 为 4.
随机选取 4 组实验数据进行测试,分别是主题"国家技术设备引进,这一举措将会大大促进国内经济的发展"、"在当代,爱因斯坦是一个才华出众的人"、"2012 年 9 月 6 日星期四伦敦奥运会,刘翔摔倒退赛,代言上市公司或受影响"和"大密度立体化军演排山倒海,解放军四大军区加紧备战"作为测试数据。利用SOSO 检索引擎工具进行检索,并分别选择检索结果的前 100 条数据进行同义识别和性能分析,实验系统如图 3 所示,实验结果如表 2 所示。
从表 2 可以看出,总体上,本文方法比已有的基于汉语构词的识别方法和基于语义的识别方法在网络检索系统的同义词识别方面的效果更优良。不管是从平均 SiMM,还是从人工平均满意度值来看,本文提出的基于句法结构分析的同义词识别方法均表现更令人满意。
6 结 语
针对基于语义的同义词识别方法中重心后移造成的识别偏差问题,提出了一种基于句法结构分析的同义词识别方法。采用句法结构分析方法对词和短语中的原子词进行等价分析,不存在计算权重问题,从而克服了因重心后移带来的同义词识别偏差问题,使得本文提出的方法具有较好的同义词识别效果。实验证明该方法更符合人的主观判断、更有效。
未来研究将继续完善句法结构分析方法,改进方法的流程,进一步提高同义词识别效果,使同义词识别自动化程度更高。
参考文献:
[1]宋明亮。 汉语词汇字面相似度性原理与后控制词表动态维护研究[J].情报学报,1996,15(4) : 261 -271.(Song Mingliang.Research on Principle of Literal Similarity Among Chinese Wordsand Maintaining Post - controlled Vocabulary[J].Journal of theChina Society for Scientific and Technical Information,1996,15(4) : 261 -271.)。
[2]王源,吴晓滨,涂从文,等。 后控规范的计算机处理[J].现代图书情报技术,1993(2) : 4 - 7.(Wang Yuan,Wu Xiaobin,TuCongwen,et al.Computer Processing of Post - control Indexing[J].New Technology of Library and Information Service,1993(2) : 4 -7.)。
[3]刘群,李素建。 基于《知网》的词汇语义相似度计算[EB/OL].
[2013 -08 - 22].(Liu Qun,Li Sujian.Word Similarity Computing Based on How-Net [EB / OL].[2013 - 08 - 22].)。
[4]朱毅华,侯汉清,沙印亭。 计算机识别汉语同义词的两种算法比较和测评[J].中国图书馆学报,2002,28(4) : 82 - 85. (Zhu Yihua,Hou Hanqing,Sha Yinting.A Comparison of TwoAlgorithms for Computer Recognition of Chinese Synonyms[J].Journal of Library Science in China,2002,28(4) : 82 - 85.)。
[5]王兰成,李超。 改进的中文同义词相似匹配方法[J].中国图书馆学报,2005,31(3) : 61 - 64.(Wang Lancheng,Li Chao.An Improved Chinese Synonym Similarity Matching Method[J].Journal of Library Science in China,2005,31(3) : 61 - 64.)。
[6]余刚,裴仰军,朱征宇,等。 基于词汇语义计算的文本相似度研究[J].计算机工程与设计,2006,27(2) : 241 - 244.(YuGang,Pei Yangjun,Zhu Zhengyu,et al.Research of Text Simi-larity Based on Word Similarity Computing[J].Computer Engi-neering and Design,2006,27(2) : 241 - 244.)。
[7]穗志方,俞士汶。 主题概念规范化研究中的自然语言处理策略[EB/OL].[2013 -08 -22].(Sui Zhi-fang,Yu Shiwen.Natural Language Processing Strategy in theStandardization of Theme Concepts[EB / OL].[2013 - 08 - 22].)。
[8]田久乐,赵蔚。 基于同义词词林的词语相似度计算方法[J].吉林大学学报: 信息科学版,2010,28(6) : 602 -608.(Tian Ji-ule,Zhao Wei.Words Similarity Algorithm Based on Tongyici Ci-lin in Semantic Web Adaptive Learning System[J].Journal of Ji-lin University: Information Science Edition,2010,28 (6 ) : 602 -608.)。
[9]于娟,党延忠。 结合词性分析与串频统计的词语提取方法[J].系统工程理论与实践,2010,30 (1) : 105 - 111.(YuJuan,Dang Yanzhong.Chinese Term Extraction Based on POSAnalysis & String Frequency [J].Systems Engineering-Theory &Practice,2010,30(1) : 105 - 111.)。
[10]哈尔滨工业大学社会计算与信息检索研究中心。 哈工大停用词表 [EB/OL].[2013 - 05 - 30].(Research Center for Social Computing and Information Retrieval,Harbin Institute of Technology.StopWords List[EB / OL].[2013- 05 - 30]. )。
[11]张华平,刘群。 基于 N - 最短路径方法的中文词语粗分模型[J].中文信息学报,2002,16(5) : 1 - 7.(Zhang Huaping,Liu Qun.Model of Chinese Words Rough Segmentation Based onN - Shortest - Paths Method[J].Journal of Chinese InformationProcessing,2002,16(5) : 1 - 7.)。
[12]刘群,张华平,俞鸿魁,等。 基于层叠隐马模型的汉语词法分析[J].计算机研究与发展,2004,41(8) : 1421 - 1429.(LiuQun,Zhang Huaping,Yu Hongkui,et al.Chinese Lexical Analy-sis Using Cascaded Hidden Markov Model[J].Journal of Comput-er Research and Development,2004,41(8) : 1421 - 1429.)。
[13]张艳。 汉语句法分析的理论方法的研究及其应用[D].北京:中国科学院自动化研究所,2003.(Zhang Yan.Research andIts Application of Chinese Syntactic Analysis Theoretical Methods[D].Beijing: Institute of Automation,Chinese Academy of Sci-ences,2003.)。
[14]Liu T,Ma J,Li S.Building a Dependency Treebank for ImprovingChinese Parser[J].Journal of Chinese Language and Computing,2006,16(4) : 207 - 224.
[15]哈尔滨工业大学社会计算与信息检索研究中心。 中文依存句法分析[EB/OL].[2013 - 01 - 16].(Research Center for Social Computing and Information Retrieval,Harbin Institute of Technology.Chinese Dependency Parser[EB /OL].[2013 - 01 - 16].