摘 要: 抄袭源是指1篇被检测文档中抄袭的部分所在的文档集合, 抄袭检测源检索的任务就是检测文章时, 用最小的代价检测出尽可能多的潜在抄袭源。通过对中文抄袭检测源检索方法的研究, 探索基于web的中文抄袭源检索的解决策略、具体方法和技术。
关键词: 源检索; 抄袭检测; 关键词提取; 下载过滤技术;
Abstract: The source refers to a detected plagiarism in one document which is in the document collections.Plagiarism detection source retrieval task is based on retrieving as much potentially plagiarized source as possible with the minimum cost.This paper explores the solution strategy, specific method and technology of the retrieval of Chinese plagiarism source based on web through the research of the source retrieval method of Chinese plagiarism detection.
Keyword: source retrieval; plagiarism detection; keywords extraction;
随着科学技术的飞速发展, 互联网已成为抄袭和重复使用的文字最常见的来源之一。抄袭检测源检索任务是给定一个可疑的文档和网页搜索引擎, 根据存在抄袭现象的文本检索到所有的源文件, 同时最大限度地降低成本。
1、 研究现状及分析
目前, 中文抄袭检测的源检索研究的重点内容:一是中文抄袭源检索查询关键词提取。关键词提取步骤在源文档检索中非常重要, 因为这个过程将直接影响到文档检索的综合指标, 抽取的关键词越少, 选择的关键词越好, 搜索引擎反馈的源文档质量越高, 因此, 关键词提取方法是研究的重点。二是抄袭源获取, 即利用搜索引擎, 获取检索到的备选抄袭源文档。并对获取的源码进行解析, 对疑似抄袭源部分应用检索结果获取技术进行下载保存, 通过实验得出最稳定的下载方法, 并得到疑似抄袭源文本集合, 对疑似抄袭源文本进行详细比对, 最终得到抄袭源。
源检索性能的评估:对于源检索任务, 国际抄袭检测大赛的评测方给出一个衡量源检索性能的算法, 并且表明在衡量源检索性能的时候, 近似抄袭的检测结果不可小视。
在历届国际抄袭检测大赛上, 源检索任务都被视作能否取得更好成绩的重点, 自然在这个国际性的大舞台上会产生许多种源检索策略, 对这些策略进行分析不难发现源检索任务分为以下5个步骤:分块、关键词提取、查询构建、检索控制和下载过滤。而国内知名的学术不端文献检测系统 (AMLC) 自主研发的多阶指纹特征检测技术, 具有检测速度快、准确率、召回率较高、抗干扰性强等特征。但是检测基于web的文本抄袭现象的能力是AMLC不具备的。
2、 研究内容
本文应用提取关键词的方法来解决这一问题。在中文上, 提取关键词解决基于web的抄袭问题的相关研究比较匮乏。对于语料库方面, 虽然没有CNKI那样庞大的语料库, 但是可以应用百度搜索获取动态的语料库。

本文通过实验比较关键词提取技术, 在基于文本子块的关键词提取技术上, 根据词性提取每一块的名词和动词, 经过比较百度和CNKI的性能, 选择本次研究的搜索引擎。
2.1、 源检索的介绍
抄袭源是指一篇被检测文档中抄袭的部分所在的文档集合, 抄袭检测源检索的任务就是依据被检测论文以最小的代价检索出尽可能多的潜在抄袭源。通过标识文档、分析文档内容, 检测可能抄袭的部分, 若可以获得抄袭源, 那么就返回相似源文档的过程。抄袭检测中的源检索任务可以看作是一项信息检索任务, 在文本检索中, 检索系统根据文档所提供的查询词进行检索, 查询词可能小到几个关键字大到一个文档。同样地, 在抄袭检测中, 从源文档的语料库集合中, 检索与一个查询文档相似的全部文档列表。从另一个角度来看, 无论是信息检索研究还是抄袭检测研究, 其核心问题都是基于文本块的关键词提取, 将其组合成查询, 从检索库中进行检索。图1所示为源检索的核心流程。
由图1可知, 源检索大体分为5个步骤:分块、关键词提取、查询构建、检索控制和下载过滤技术。
分块:分块的原则就是在不改变原文章、原段落意思的基础上将文章切分为若干个子文本块。将文章分成若干个子块的目的是为了方便关键词的提取和构建查询。
关键词提取:对于给定的文本块, 关键词提取是为了与其他提取出来的关键词组成查询。关键词提取的基本原理是选择一些能够将检索的源文档与可疑文档匹配最大化的短语或者词, 也就是说, 选择的词组成的查询要尽可能地获取到与可疑文档相匹配的源文档。关键词的提取也可以作为限制组成查询量的手段, 从而减少使用搜索引擎的整体成本。
查询构建:给定从文本块中提取的关键词的集合, 它们满足于查询构建所使用的搜索引擎的API。基本原理是:满足于搜索引擎施加的限制, 并在搜索特点的基础上对关键字进行搜索 (如Indri的短语搜索) 。
图1 源检索核心流程
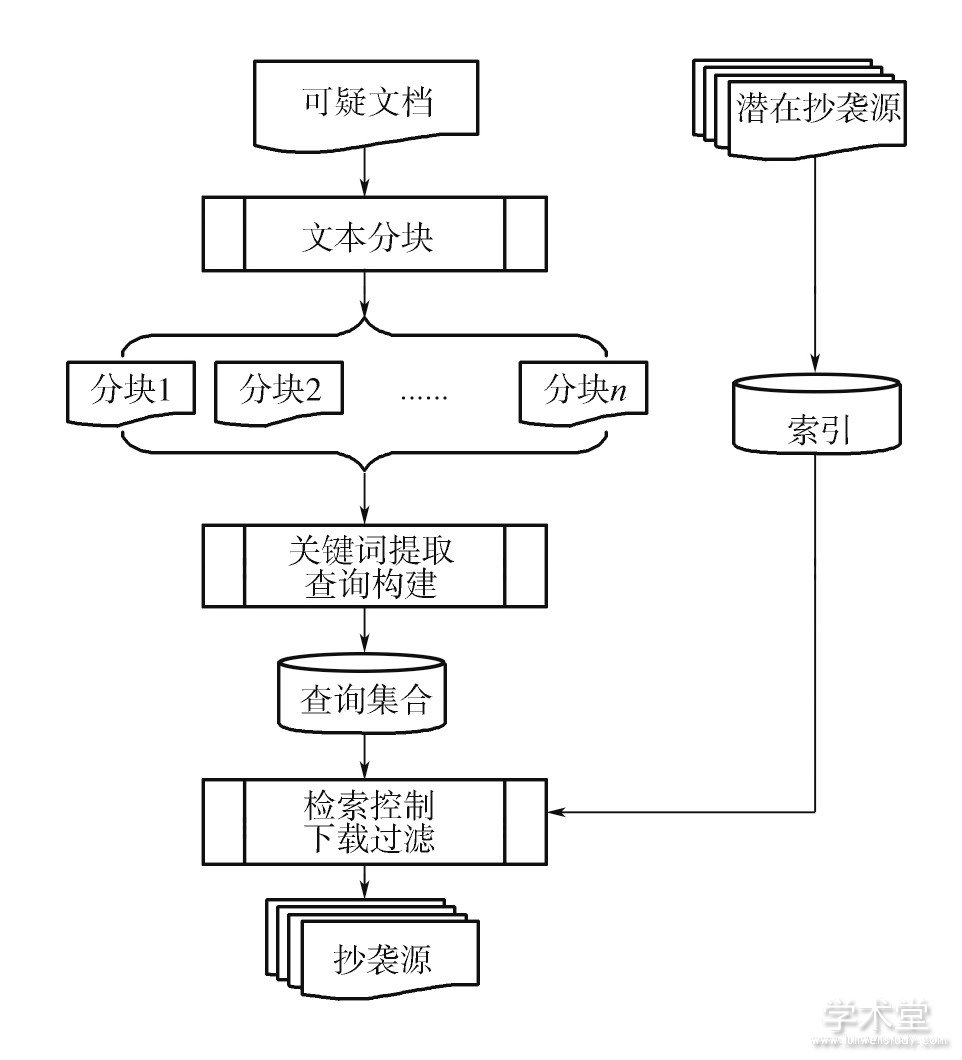
搜索控制:给定一组查询, 搜索控制器调度其提交给搜索引擎, 并指定搜索结果的下载。基本原理是动态地调整基于每个查询结果的搜索, 可以包括丢弃查询、重新组织现有的查询词或基于从搜索结果中所获得的相关反馈组织新的查询。
下载过滤:过滤给定的一组下载文件, 下载过滤器排除这些可能是不值得的所有文件进行比较详细的可疑文件。基本原理是进一步降低候选集, 并保存在随后详细的比较步骤的调用。
2.2 、现有源检索方法
随着互联网的出现, 抄袭已经成为一个普遍存在的问题, 影响了大学和其他学术机构。虽然早期的检测方法包括搜索在本地数据库源, 现在现实的方法也必须是寻找万维网来源。这是通过检查可疑文档和生成查询其随后造成对一个或多个搜索引擎, 如谷歌或雅虎完成。根据对源检索的介绍, 下面总结现有的英文源检索的主要策略。
1) 分块策略。给定一篇可疑文档, 根据一定的原理切分成若干个文本子块, 从而得到意想不到的特征。其中, 基于Elsayed和Lin的方法将接近的数据编码成一个长数据, 以限制其大小。因此, 块的数目由数位 (64) 限制, 使用可变块长度的限制。上述的分块方法只是众多分块方法中的一种。
2) 关键词提取策略。其中, 基于Elsayed和Lin的方法将接近的数据编码成一个长数据, 以限制其大小。因此, 块的数目是由数位 (64) 限制, 使用可变块长度的限制。上述的分块方法只是众多分块方法中的一种。
3) 查询构建策略。通过3次国际抄袭检测大赛来看, 所有的参赛者使用的搜索引擎或是ChatNoir或是indri。
4) 搜索控制策略。根据3次国际抄袭检测大赛, Prakash和Saha舍弃一些使用条件60%以上包含在另一个查询的查询。Suchomel和Brandejs按计划查询, 取决于其提取的关键词的优先顺序是对应于它们已经在上面介绍的顺序。
5) 下载过滤策略。下载过滤器排除这些可能是不值得的所有文件进行比较详细的可疑文件。基本原理是进一步降低候选集, 并保存为在随后详细的比较步骤的调用。
2.3 、研究框架
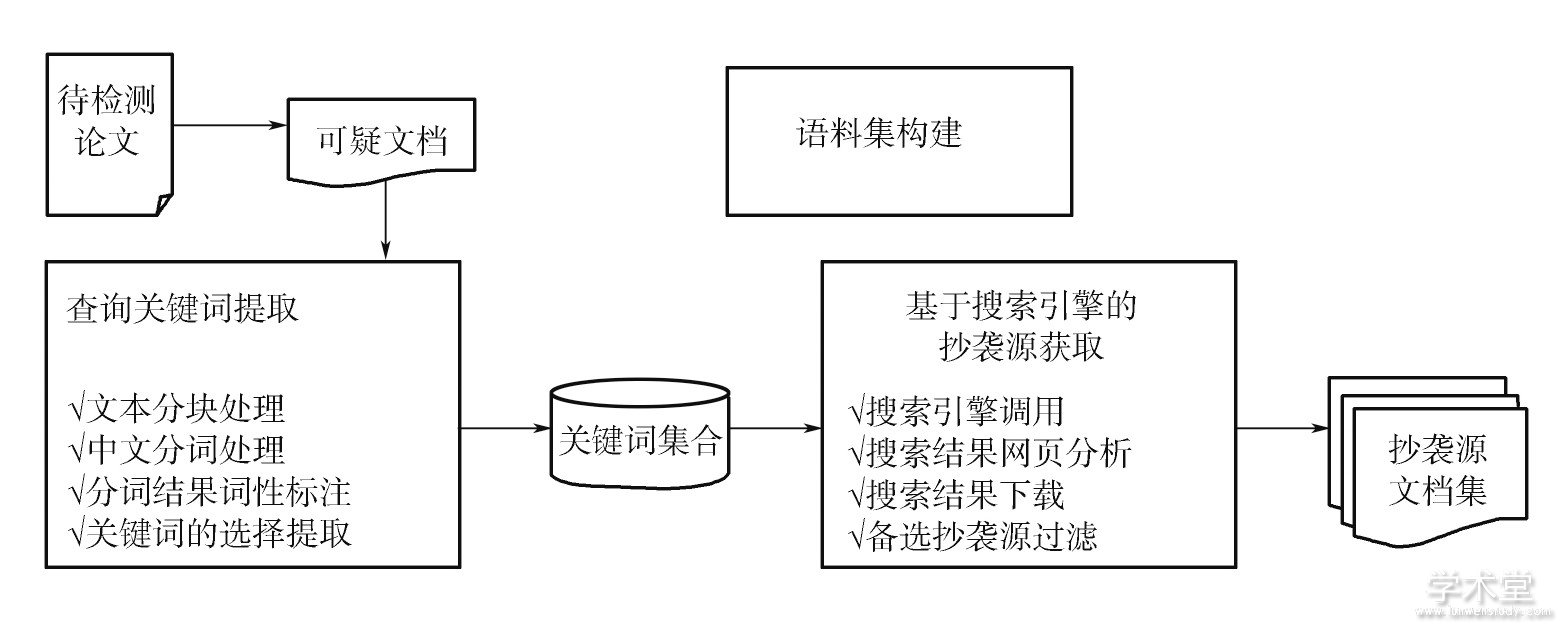
源检索任务大体上分为两部分:第一部分是查询关键词提取, 主要内容包括:文本分块处理、中文分词处理、分词结果词性标注、关键词的选择提取;第二部分是基于搜索引擎的抄袭源获取, 主要内容包括:搜索引擎调用、搜索结果网页分析、搜索结果下载、备选抄袭源过滤。研究框架如图2所示。
图2 研究框架
本文将在每一步的研究策略上, 借鉴现有的英文抄袭检测源检索策略以及现有的中文抄袭检测源检索策略, 总结出适合于解决基于web抄袭现象的源检索方法。
1) 源检索任务的重点是关键词提取, 提取的关键词质量直接影响后续的检索质量, 以及下载源文档的质量, 所以关键词提取的策略是本次研究的重点内容。关键词提取策略需要以下步骤, 如图3所示。
图3 关键词提取步骤
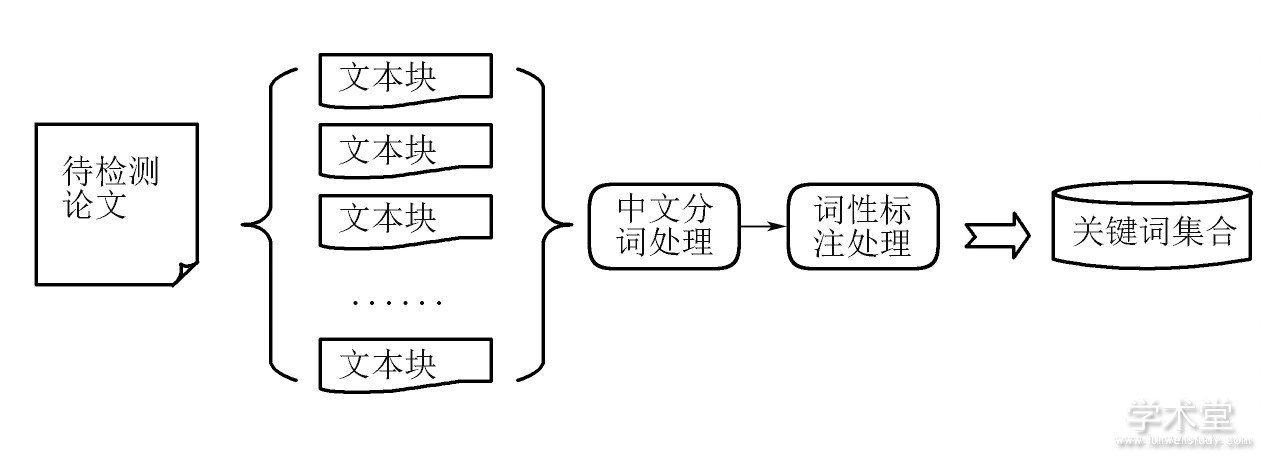
2) 关键词提取策略实施。关键词提取部分应用中科院分词工具包和TF-IDF算法提取关键词的策略。其中, 中科院分词工具包具有词性标注功能, 本次研究取名词和动词作为关键词, 应用TF算法之前先要应用lucene中文分词工具包将中文文档进行分词处理。
2.4、 数据采集及实验结果分析
抄袭检测源文档集数据的采集与信息的加工是抄袭检测的基础。数据采集完成对论文抄袭常用源文档数据的获取, 数据加工用于完成对采集的海量数据进行相应的预处理操作。
1) 数据采集。所谓抄袭备选文档是指与可疑文档具有一定相似度的文档, 抄袭备选文档集是抄袭备选文档的集合。获得抄袭备选文档的过程可以描述为:将可疑文档在离线参考文档集中进行文档检索, 以获得抄袭备选文档, 在抄袭备选文档中进行详细分析, 如果发现可疑文档中存在抄袭片段, 则报告具体的抄袭片段, 否则, 则利用文档检索系统基于Internet进行检索以获得抄袭备选文档。例如, 针对本科生论文抄袭来源的主要特征, 首先为本科生论文抄袭的主要来源构建抄袭检测系统的离线参考文档集, 该文档集的主要来源包括: (1) Internet上学生抄袭的主要来源网页; (2) 各种学术论文、会议论文、学位论文资源; (3) 项目申请者拥有的数据。
对于Internet上学生抄袭的主要来源网页, 将使用网络爬虫爬取这些网页的内容。
2) 数据的加工。对数据信息进行预处理, 主要包括:格式转换、文档块结构的分割、中文分词、去停用词
本次试验数据加工对上述数据预处理采取的具体策略。
将备选文档集拆分为不同的块结构目的在于为不同的块创建索引, 解决论文在不同层次上的抄袭程度判断问题, 块结构可以以自然段为单位, 也可以以论文的自然结构 (如标题、摘要、正文等) 为单位。
3) 本实验的数据来源为黑龙江工程学院计算机科学与技术学院2014届毕业生的毕业设计 (论文) , 当学生论文抄袭比例较高时, 其不可能对论文进行重写, 只可能通过各种修改来逃避抄袭检测, 基于此, 本实验采用的原始可疑文档为毕业生第一次抄袭检测提交的论文, 同时CNKI的检测报告也对应保留, 还有经过修改后第二次提交的论文, 第二次抄袭检测时学术不端检测系统生成的检测报告也对应保留作为参考抄袭源。经过对比发现, 学生两次提交的报告除了少数片段进行重写, 意思已经完全改变, 除此之外的大部分抄袭片段或者章节都没有重写而是通过一定的手段进行修改来躲避抄袭检测, 因此, 选用那些经过一定修改来躲避抄袭并且在第二次提交时没有检测出来的文本对作为可疑文档的来源。
本次试验所使用的评价指标为:精确率P (precision) 、召回率R (recall) 和F值。在抄袭检测的源检索任务阶段主要使用这3个评测指标进行评测, 检查结果如表1所示。
表1 检验结果
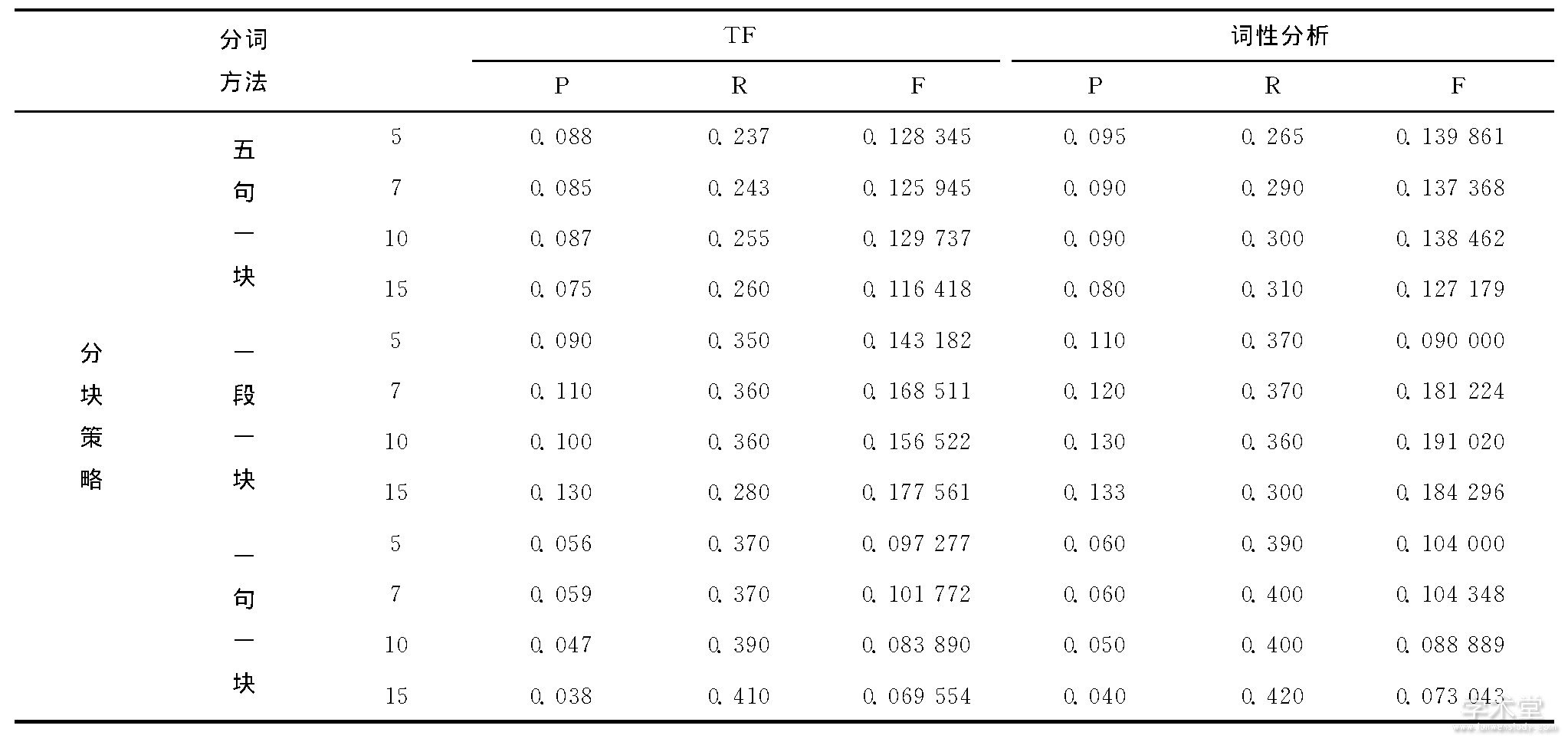
由表1可以比较出两种主流分词工具性能的差异, 也为本次中文抄袭检测分词工具的选取提供数据支持。比较不同分块策略和不同查询构建方法组合之间各项评价指标的不同。从表中可以看出词性分析策略下, 按段落分块和10个关键词构成的查询F值最高, 所以本次研究的最优方法是基于中科院分词工具的方法, 按段落分块、词性标注提取名词、动词和10个关键词构建查询的方法。然而在本次研究中, 精确率普遍较低, 这是由于实验提交大量的查询, 下载大量的结果导致召回率高, 精确率低的现象。
3 、结束语
本文在原有的中文抄袭检测源检测算法的基础上, 通过实验分析比较各种分词工具和词性标注工具的优缺点, 选取针对高模糊抄袭以及网络抄袭的行之有效的关键词提取方法。CNKI虽然能检测出大部分的中文抄袭, 但面对基于web抄袭的现象显得力不从心。本文总结基于web抄袭的特点, 并对文本按段落进行分块, 并在每段中提取关键词。这种方法既不改变文章、段落的大意, 又能有效地提取关键词。经过实验研究, 结果证明本文的关键词提取方法能够有效地检测基于web的抄袭现象。
参考文献
[1] KONG L, QI H, WANG S, et al.Approaches for candidate document retrieval and detailed comparison of plagiarism detection.2012Cross Language Evaluation Forum Conference, Working Notes Papers of the CLEF 2012 Evaluation Labs, CEUR Workshop Proceedings, Rome, Italy, 2012:1-6.
[2] GILLAM L, NEWBOLD N, COOKE N.Educated guesses and equality judgements:using search engines and pairwise match for external plagiarism detection[J].LNCS, 2012.
[3] OBERREUTERG, CARRILLO-CISNEROSD, SCHERSON I D, et al.Submission to the 4th international competition on plagiarism detection[J].Notebook Papers of PAN CLEF, 2014.
[4]李维刚, 刘挺, 张宇, 等.基于长度和位置信息的双语句子对齐方法[J].哈尔滨工业大学学报, 2006, 38 (5) :689-692.
[5] 王大玲, 刘振鹿, 冯时, 等.一种基于TF-IDF的潜在语义区划分及Web文档聚类算法[J].中文信息学报, 2011, 25.
[6]黄承慧, 印鉴.一种结合词项语义信息和TF-IDF方法的文本相似度量方法[J].计算机学报, 2011 (5) .
[7]汪敏, 肖诗斌.一种改进的基于《知网》的词语相似度计算[J].中文信息学报, 2009, 22 (5) .
[8]徐戈, 黄厚峰.自然语言处理中主题模型的发展[J].计算机学报, 2011 (8) :1423-1437.
[9] 霍华, 冯博琴.基于压缩稀疏矩阵矢量相乘的文本相似度计算[J].小型微型计算机系统, 2009, 26 (6) .





