卷积神经网络论文范文第六篇:基于注意力机制的安全帽检测卷积神经网络建立
摘要:在复杂的施工环境中,基于机器视觉技术的安全帽佩戴检测算法常常出现漏检、误检,其检测能力有限。为提高安全帽佩戴检测的精度,本文建立了一种基于注意力机制的双向特征金字塔的安全帽检测卷积神经网络。为兼顾卷积神经网络中的浅层位置信息和深层语义信息的表达能力,实现对弱小安全帽目标的检测能力,该网络将跳跃连接和注意力机制CBAM技术引入双向特征融合的特征金字塔网络PANet模块中,构建基于注意力机制的双向特征金字塔模块CPANet.为提高模型的收敛能力,采用了CIoU来代替IoU进行优化锚框回归预测,降低该网络的训练难度。对比实验表明,本文建立的检测网络比YOLOv3、RFBNet、SSD、Faster RCNN的mAP值分别提高了0.82,4.43,23.12,23.96,检测速度达到21frame/s,实现了施工现场安全帽佩戴实时高精度检测。
关键词:目标检测;特征融合; PANet; CBAM; CloU;
作者简介:李天宇(1996-),男,硕士研究生,2018年于四川轻化工大学获得学士学位,主要从事计算机视觉、目标检测方向的研究。E-mail:litianyu207@163.com;*陈明举(1982-),男,重庆人,博士研究生,副教授,2007年于重庆邮电大学获得硕士学位,主要从事智能信息处理、图像处理和机器学习研究。E-mail:chenmingju@suse.edu.cn;
基金:国家电网公司科技攻关项目(No.521997180016);四川省科技厅项目(No.2017JY0338,No.2019YJ0477,No.2018GZDZX0043,No.2018JY0386,No.2020YFG0178);人工智能四川省重点实验室项目(No.2019RYY01);四川轻化工大学研究生创新基金项目(No.y2020020);
Abstract:In a complex construction environment,the helmet wearing recognition algorithm based on machine vision technology often fails and misdetects,and its recognition ability is limited.In order to improve the accuracy of helmet wearing recognition,this paper establishes a helmet recognition convolutional neural network based on the bidirectional feature pyramid of the attention mechanism isproposed.In order to improve the expression ability of shallow position information and deep semantic information in the convolutional neural network,and increase the recognition rate of vague and small helmets,the network introduces the jump connection and the attention mechanism CBAM technology into the bidirectional feature fusion feature pyramid network PANet module,and bidirectional feature pyramid module based on the attention mechanism is constructed.In order to improve the convergence ability of the model,CIoU is used instead of IoU to optimize the anchor frame regression prediction,which reduces the complexity of the network training.The results of comparative experiment show that the mAP value of our proposed recognition network is 0.82,4.43,23.12 and 23.96 higher than that of YOLOv3,RFBNet,SSD,Faster RCNN,respectively,and its detection speed reaches 21 frame/s,thus satisfy with height real-time accuracy of helmet recognition in the construction environment.
Keyword:target detection; feature fusion; PANet; CBAM; CIoU;
1 引言
在施工环境中,施工人员佩戴安全帽可以有效避免或减小安全事故的伤害。通过人工巡检监控视频实现安全帽佩戴检测费时费力,且容易造成误检和漏检。利用机器视觉技术对施工现场工作人员是否佩戴安全帽进行检测,可有效地代替人工巡检,提高识别的精度,避免安全事故的发生。
传统的安全帽检测主要通过对监测视频进行目标检测,提取目标的几何、颜色等特征进行对比识别。刘晓慧等人[1]利用肤色检测实现人头区域的定位,再采用SVM分类器对安全帽的Hu矩特征进行识别;周艳青等人[2]将人头区域的统计特征、局部二进制模式特征和主成分特征训练分类器,建立了多特征的安全帽检测算法;贾峻苏等人[3]结合局部二值模式直方图、梯度直方图和颜色特征,利用SVM对安全帽进行检测。基于目标图像特征提取的传统检测方法,泛化能力较差[4],而实际施工环境复杂多样,通常存在雨雾、遮挡等的影响。因此,基于目标图像特征提取的传统检测方法检测能力有限。
近年来,基于深度学习的目标检测技术能够利用卷积网络自动学习大样本数据有用的特征,建立的检测网络模型泛化能力较强,有效地实现了特殊环境下的安全帽识别。基于深度学习的目标检测技术主要为基于区域建议和基于回归策略的目标检测网络。基于区域建议的目标检测网络需要先生成可能含有待检测物体的预选框,然后再利用主干网络提取特征信息进行分类和回归。基于回归策略的单阶段目标检测算法则直接在网络中提取特征预测出物体的类别以及位置[5].通常二阶段的检测算法精度高,但检测速度远低于单阶段的检测速度。经典的二阶段网络Faster RCNN[6]采用RPN预选框生成网络和主干特征提取网络,实现目标的准确识别,但检测耗时较大。徐守坤等人[7]在二阶段检测算法Faster RC-NN的基础上利用多层卷积特征优化区域建议网络,建立改进的faster-RCNN算法,虽然提高了网络检测的准确率,但是延长了检测时间,其检度时间仍然远大于一阶网络,未能达到实时检测的要求。基于回归策略的目标检测网络主要是YOLO、SSD、RFBNet等[8,9,10,11,12].为提高单阶段网络的检测精度,董永昌等人[13]在SSD检测算法的基础上,引入了DenseNet作为主干网络提取特征,充分利用了各层的特征信息,提高了网络的检测精度。陈柳等人[14]在RFBNet检测算法的基础上,引入SE-Ghost模块来轻量化检测模型,并利用FPN提高网络对小目标检测的鲁棒性。唐悦等人[15]针对单阶段算法YOLOv3的缺点,引入GIoU代替IoU来优化锚框选取,但是GIoU具有在锚框包含时会退化为IoU的缺点。同时检测网络采用了密集连接结构来加强特征的传递,所得到算法的检测效果优于传统YOLOv3.以上改进的单阶段网络虽然都提高了检测精度,但是检测速度有所下降。
本文针对施工现场的复杂环境与实时性要求,以YOLOv3网络为基础建立一种基于回归策略的高精度安全帽检测网络。该网络在YOLOv3的检测网络中,构建特征金字塔网络CPANet模块提高弱小安全帽目标的检测精度,同时采用了CIoU来代替IoU进行回归预测,在优化锚框回归的同时能够提高模型的收敛能力。通过对比实验证明,在有遮挡的复杂施工环境下,该网络能实现弱小安全帽目标的准确检测,且检测速度较快,满足实时检测的要求。
2 YOLOv3目标检测网络
YOLOv3是基于回归策略的目标检测算法,网络包括Darknet53特征提取网络和检测网络两部分,其中Darknet53主要用来提取图像特征信息,检测网络用来进行多尺度的目标预测。DarkNet53是全卷积网络,共有53个卷积层,采用1×1和3×3的卷积组成带有跳跃连接的残差块来构建残差网络,减少了因网络太深而带来的梯度消失现象,能够提取更加深层的语义信息。同时,使用步长为2的卷积来代替最大池化进行下采样,降低了池化带来的梯度负面效果。
为了提高网络对目标的检测能力,YOLOv3检测层中使用了类似特征金字塔网络的上采样和特征信息融合的做法。当输入图像归一化到416×416送入网络进行检测时,Darknet53会输出3个检测尺度,分别为13×13,26×26,52×52.根据特征金字塔网络结构,13×13与26×26大小的特征图要依次经2倍上采样操作与26×26和52×52大小的特征图进行信息融合,将深层的语义信息通过快捷连接传入到浅层,得到3个带有语义和位置信息融合的特征图。YOLOv3的网络结构如图1所示。
图1 YOLOv3算法结构示意图
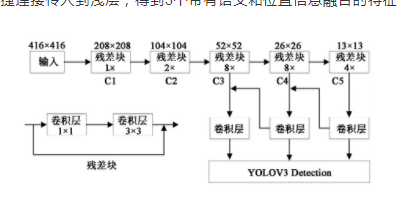
Fig.1 Diagram of YOLOv3algorithm structure
YOLOv3网络能够快速实现目标的检测,并利用FPN引入多尺度的目标预测来提高其检测能力。但其FPN网络只采用3个尺度,只进行了一次自上而下的特征融合,各层信息利用不足,对于一些小目标和有遮挡目标,其检测能力有限。
YOLOv3在实现边界框预测时,通过kmeans算法对数据集中的目标框进行维度聚类,得到9组不同大小锚框,将锚框平均分配到3个检测尺度上,每个尺度的每个锚点分配3组锚框。但是这样操作会带来大量的锚框,于是YOLOv3采用了最大交并比(IoU)来对锚框进行回归。IoU计算的是预测边界框和真实边界框的交集和并集的比值,一般来说预测边界框和真实边界框重叠度越高,则其IoU值越大,反之越小。并且IOU对尺度变化具有不变性,不受两个物体尺度大小的影响。其计算公式如式(1)所示:
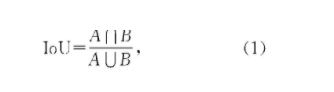
其中,A属于真实框,B属于预测框。
但是IoU无法精确地反应真实框和预测框重合位置的关系,存在两个较大的缺点,第一,无法衡量两个框之间的距离,如图2所示,图2(a)明显要比图2(b)中的距离近,但仅从IoU数值上无法判断两框的远近;第二,无法反映真实框与预测框的重叠方式,如图2(c)与图2(d)的重叠方式完全不一样,从IoU的数值上无法判断其重叠方式。当上述情况出现时,会导致网络没有梯度回传,造成模型难以收敛等问题的出现。
图2 真实框与预测框位置表示图
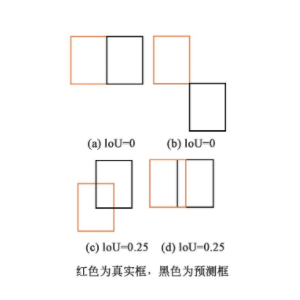
Fig.2 Representation of the position of the prediction frame and the real frame
3 一种高精度的卷积神经网络安全帽检测方法
为了实现施工现场的复杂环境中弱小目标与遮挡目标的有效检测,并提高网络的收敛能力,本文在YOLOv3网络的基础上引入CPANet与CIoU,建立一种高精度的安全帽检测网络(YOLO_CPANet_CIoU)来提高检测精度与模型收敛能力。
3.1 CPANet的特征金字塔网络
在检测网络中,YOLOv3采用一次自上而下单向特征融合的特征金字塔网络(图3),利用C3~C5的输入层经上采样得到P3~P5三个不同尺度的输出特征层。从C5到P5的过程经过了5次卷积,再经过一次3×3的卷积和一次1×1的卷积调整通道数后输出;C3-P3、C4-P4的过程,首先要与上一层特征图的两倍上采样结果进行特征融合,然后再经过和C5到P5同样的运算过程并输出对应的特征图;最后特征金字塔网络会输出3个不同尺度的特征图进行目标预测。一般来说,低层的特征图包含更多的位置信息,高层的特征图则拥有更好的语义信息,FPN网络就是将这个两者特征结合,增强网络的检测准确率。但是YOLOv3中自上而下的特征金字塔网络,只将深层的语义信息通过便捷通道送入浅层,提高浅层特征的分类准确率,但并没有利用便捷通道将浅层的位置信息传入深层,深层特征的定位准确性有限。
图3 YOLOv3算法特征金字塔网络
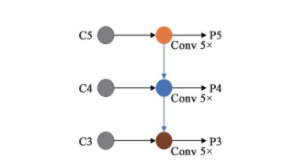
Fig.3 YOLOv3algorithm feature pyramid network
于是,为了实现对佩戴安全帽的工人准确检测,减少网络特征损失,并有效利用高低层的特征信息来提高网络的定位准确率,本文引入了双向特征融合的特征金字塔网络PANet[16],在原始单向特征融合的FPN后加入了一条位置信息特征通道,使得浅层的特征能够通过便捷通道在损失较小的情况下将位置信息传送到深层进行特征融合,进一步提高了对弱小目标的定位准确性。PANet结构如图4所示。
相应的研究表明[17],与多次学习冗余的特征相比,特征重用是一种更好的特征提取方式。于是本文在特征金字塔上的横向传播通道添加3条跳跃连接,直接将主干网络C3、C4、C5层的特征传入到最后的输出部分进行融合,使得最终输出能够得到前几层特征图上的原始信息。这样做也能够在一定程度上加快网络的收敛速度,提高网络结构的表征能力,增强对安全帽这类小目标物体的检测效果。
图4 PANet双向特征金字塔结构
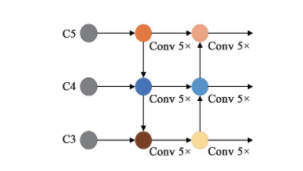
Fig.4 PANet bidirectional feature pyramid structure
为了进一步减少遮挡目标的误检,提高安全帽检测精度,在特征金字塔网络的输出部分引入CBAM[18]注意力模块建立CPANet特征金字塔网络,如图5所示。利用CBAM分别从通道和空间的角度来增强特征信息,在一定程度上扩大特征图对全局信息的感知范围,增强特征的表达能力。CBAM模块首先通过通道注意力模块,对每个通道的权重进行重新标定,使得表达小目标和遮挡目标的区域特征通道对于最终卷积特征有更大的贡献,从而在背景中突出小目标和遮挡目标,并且抑制一些对分类作用不大的通道,减少网络计算量;再利用空间注意力机制来突出目标区域,通过统计特征图的空间信息得到空间注意图用于对输入特征进行重新激活,从而引导网络关注目标区域并抑制背景干扰。
图5 CPANet特征金字塔结构
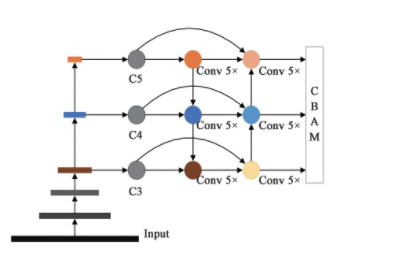
Fig.5 CPANet feature pyramid structure
3.2 CIoU边界框损失函数
YOLOv3中使用了IoU对锚框进行回归,但是根据前文分析,IoU无法衡量两个框之间的距离和重叠方式,会导致模型收敛能力较弱。所以,一个好的回归框应该考虑重叠面积、中心点距离、长宽比3个集合因素,文献[19]针对这些问题首先提出了DIoU,同时考虑了真实框与预测框之间的距离和重叠面积,DIoU Loss的计算公式如下所示。
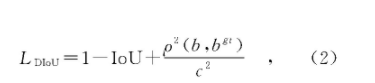
其中:b和bgt分别为预测框和真实框的中心点,ρ(·)为两中心点之间的欧氏距离计算公式,c为在同时包含预测框和真实框的最小闭包区域的对角线距离。
其距离示意图如图6所示,d为预测框与真实框中心点距离,c为两框对角点距离。可知DIoU能够同时考虑中心点距离与重合两框的对角点距离,改进了IoU存在的缺点,能够在两框未重合情况下为模型提供优化方向。
图6 距离示意图
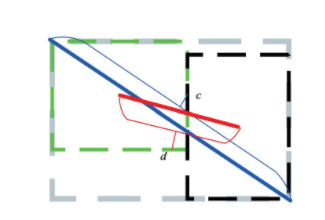
Fig.6 Distance diagram
同时,CIoU在DIoU的基础上进一步考虑长宽比因素,在DIoU Loss的计算公式中加入惩罚项,CIoU Loss计算公式如式(3)所示。
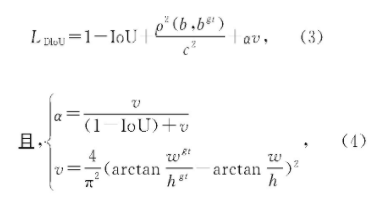
其中,α是正权衡参数,v是衡量长宽比一致性的参数。所以,CIoU同时考虑了重叠面积、中心点距离、长宽比三要素,能够直接最小化两个目标框的距离,并且在真实框与预测框不重合时,为预测框提供移动的方向。而且CIoU能替换NMS中的IoU算法,加快模型的收敛速度。
因此,在保持网络的检测性能不下降的前提下,本文利用CIoU来代替IoU进行锚框的回归,实现真实框和预测框无重合时的梯度回传,提高模型收敛能力。同时,使用CIoU能够降低模型的训练难度,提高对于安全帽检测的准确率。
4 实验结果与分析
4.1 实验环境与训练过程
本次实验在服务器上搭建环境并进行训练,服务器硬件配置为CPU(Inter Xeon E5-2695)、GPU(Nvidia TITAN Xp)、主板(超微X10DRG-Q);操作系统为Windows10专业版;软件配置为Anaconda、Pycharm;编程语言为Python,深度学习框架为Keras.
实验数据为网上收集的开源安全帽检测数据集[20],共有5 000张施工现场照片。所有的图像用"labelimg"标注出目标区域及类别,共分为两个类别,佩戴安全帽的标记为"helmet",未佩戴安全帽的标记为"head".并将数据集按8∶1∶1的比例分成训练集、验证集、测试集,分别用于模型的训练、验证以及测试过程。
本文采用安全帽数据集对检测网络进行训练,为了提高本文算法的鲁棒性并防止模型过拟合,在训练集数据输入模型训练前使用图像缩放、长宽扭曲、图像翻转、色域扭曲以及为图像多余部分增加灰条等操作对训练集进行预处理,同时采用了标签平滑策略来防止模型过拟合。
训练时,输入图片尺寸设置为416×416,采用预训练模型,优化器为Adam.网络训练分两次进行,第一阶段训练冻结Darknet53主干部分,初始学习率(Learning rate)设置为0.001,batch size(一次训练所选取的样本数)设置为32,训练50轮,使用学习率下降策略,连续2轮验证集的损失值未改善,学习率将乘以0.5;第二阶段训练释放冻结部分微调模型,初始学习率设置为0.000 1,batch size设置为6,训练60轮,使用学习率下降和提前终止策略,连续2轮验证集的损失值未改善,学习率将乘以0.5,连续10轮验证集损失未改变将提前中止训练。损失下降曲线如图7所示。
图7 损失下降曲线图。(a)前50轮;(b)后60轮。
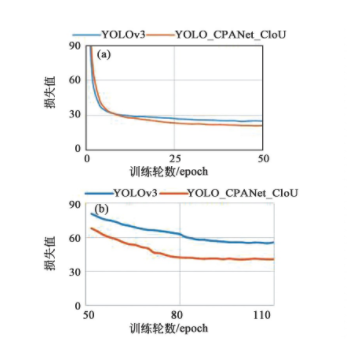
Fig.7 Loss decline graph.(a)The first 50rounds;(b)The last 60rounds.
图7(a)为前50轮冻结主干网络Darknet53的损失下降曲线,图7(b)为后60轮模型微调训练损失下降曲线,可以看出本文算法的收敛能力较改进前的YOLOv3强,最终本文算法损失下降至13左右便不再继续下降。
4.2 实验结果与分析
为了验证本文算法的有效性,选取了Faster RCNN、SSD、RFBNet、YOLOv3网络在相同的实验环境下利用相同的训练方式和数据集进行训练,得到相应的安全帽检测模型。
为了说明本文YOLO_CPANet_CIoU网络的性能,选取了4张不同施工环境、遮挡以及人群密集程度的图片,用上述训练好的模型进行测试,并对测试结果进行对比分析。图8为4张不同环境下的测试图片,图9(a)、(b)、(c)、(d)从左至右分别为Faster RCNN、SSD、RFBNet、YOLOv3以及YOLO_CPANet_CIoU网络下的测试结果。从图9中可以看出,Faster RCNN检测效果较好,可以将大部分的远处小目标安全帽以及有遮挡的安全帽目标检测出来,但是存在一些误检现象,如测试图1、测试图2和测试图4中,Faster RCNN都将一些相似的目标判定为安全帽,这是由于检测网络学习能力不足造成的误检测。其次,SSD算法在4幅不同场景的测试图片中的检测性能最差,如测试图1未检测出目标,测试图2和测试图4则未检测出远处小目标,测试图3未检测出一些遮挡目标。这是由于主干网络的特征提取能力不强,且对于小目标和遮挡目标学习能力不足造成的。RFBNet的检测效果要优于SSD,虽然测试图1、测试图2、测试图4都对远处弱小安全帽目标存在少量漏检,但是能够针对大多数的显著目标和有遮挡的安全帽进行检测,造成漏检的原因是其未利用FPN网络对高底层特征进行融合,导致对小目标的检测不够鲁棒。YOLOv3是检测性能仅次于本文算法,由于其拥有较深的特征提取网络和FPN网络,对弱小安全帽目标检测的性能较好,能对大部分的远距离以及近距离的安全帽进行检测。但是针对测试图1和测试图3中存在一定遮挡的安全帽,YOLOv3并不能准确地检测出来,存在漏检现象。
图8 原始测试图片

Fig.8 Original test pictures
图9 不同网络测试结果对比图

Fig.9 Comparison chart of different network test results
图9 不同网络测试结果对比图

Fig.9 Comparison chart of different network test results
本文的YOLO_CPANet_CIoU是4种网络中检测效果最好的,能够针对测试图1到测试图4中所有的远处弱小安全帽目标和有遮挡安全帽目标进行准确检测,这说明了本文所提出的安全帽检测方法能够很好地融合高低层的特征信息,高效引导网络注意目标区域,从而提高了算法对于弱小以及有遮挡安全帽目标的检测准确率。
为了进一步说明YOLO_CPANet_CIoU的性能,本文从模型的精确率、检测速度和参数量等评价指标来验证改进网络的优越性,利用相同的测试样本对4种网络进行测试。图10给出检测网络的模型精度对比,表1给出检测网络的模型参数对比。图10给出了4种检测网络的各类别的安全帽(Helmet)和未佩戴安全帽(Head)平均精确率(Average Precision,AP)以及平均精确率均值(mean Average Precision,mAP)。由图中可知,本文检测网络的mAP值相较于YOLOv3、RFBNet、SSD、Faster RCNN分别增长了0.82,4.43,23.12,23.96,其中helmet和Head的AP值相较于改进前的YOLOV3分别提高了0.18和1.46.这说明YOLO_CPANet_CIoU中的CIoU以及提出的CPANet特征金字塔模块能够提高网络对安全帽的检测精度。
图1 0 模型精度对比图
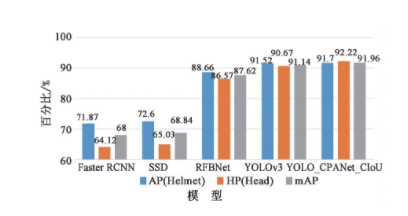
Fig.10 Model accuracy comparison chart
由表1可知,虽然YOLO_CPANet_CIoU的参数量最大有298 M,但是其检测速度仅次于YOLOv3,能够达到21frame/s的速度,完全满足实时性的要求。针对视频图像,能够实时在视频图像中定位与追踪佩戴安全帽和未佩戴安全帽的工作人员,到达施工现场安全帽检测的要求。
表1 模型参数对比表
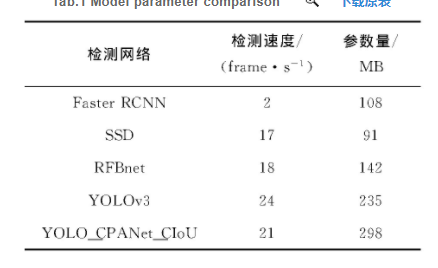
表1 模型参数对比表
5 结论
为实现施工现场安全帽快速高精度检测,本文在YOLOv3基础上引入CPANet和CIoU构建安全帽检测算法YOLO_CPANet_CIoU.首先该网络为了减少特征损失,有效利用高低层的特征信息,引入了双向特征融合的特征金字塔网络PANet,并在检测网络中添加了跳跃连接和CBAM注意力机制,形成了新的特征金字塔网络CPANet,使得浅层的位置信息与深层的语义信息能够损失较少地在网络中传递,增强网络对小目标以及有遮挡目标的检测能力。同时在保持网络的检测精度不下降的前提下,将CIoU来代替IoU,优化锚框的回归并提高模型的收敛能力。经过实验验证,本文检测算法mAP值为91.96%,检测速度达到21frame/s,能够实现复杂施工环境下对安全帽的精确检测,满足实时性的要求,比其他检测算法拥有更高的检测精度和检测效果。因此,本文提出的安全帽检测算法YOLO_CPANet_CIoU具有较大的学术参考价值和工程应用价值。
参考文献
[1]刘晓慧,叶西宁。肤色检测和Hu矩在安全帽识别中的应用[J] .华东理工大学学报(自然科学版) , 2014. 40(3):365-370.LIU X H,YE X N. Skin color detection and Hu moments in helmet recognition research[J].Journal of East China University of Science and Technology (Natural Science Edition),2014,40(3):365-370 (in Chinese )
[2]周艳青,薛河儒,姜新华,等。基BP统计特征的低分辨率安全帽识别J] .计算机系统应用, 2015.247);211-215.ZHOU Y Q,XUE H R,JIANG X H.et al.Low-resolution safety helmet image recognition combining local binary pattern with statistical features[J] Computer Systems&Applications ,2015,24(7):211-215.(in Chinese )
[3]贾峻苏,鲍庆洁,唐慧明。基于可形部件模型的安全头盔佩戴检测[J] .计算机应用研究, 2016,33(3):953-956 JIAJ S,BAO Q J,TANG H M. Method for detecting safety helmet based on deformable part model[J]. Applic ation Research of Computers,2016,33(3):953-956. (in Chinese )
[4]储岳中,黄勇, 张学锋,等。基于自注意力的SSD图像目标检测算法却[I] .华中科技大学学报(自然科学版) , 2020.48(9):70-75.CHU Y Z,HUANG Y,ZHANG X F,et al. SSD image target detection algorithm based on self- attention[J].Jourmal of Huazhong University of Science and Technology (Nature Science Edition),2020 48(9)-:70-75. (in Chinese )
[5]罗元,王薄宇,陈旭。基于深度学习的目标检测技术的研究综述[0] .半导体光电, 2020,41(1):1-10.LUO Y,WANG B Y,CHEN X. Research progresses of target detection technologybased on deep learning[J] Semiconductor Optoelectronics,2020,41(1):1-10. (in Chinese )
[6] REN S Q,HE K M,GIRSHICK R,et al. Faster R-CNN:towards real-time object detection with region proposal networks[J]IEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6)1137-1149.
[7]徐守坤,王雅如,顾玉宛。基于改进区域卷积神经网络的安全帽佩戴检测[J] .计算机工程与设计, 2020,41(5):1385-1389.XU S K,WANG Y R,GU Y W.Construction site safety helmet wearing detection based on improved region convolutional neural network[J]Computer Engineering and Design,2020,41(5):1385- 1389. (in Chinese )
[8] REDMON J,DIWALA S, GIRSHICK R,et al.You only look once:unified,real-time object detection[C]/2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)。Las Vegas,NV,USA:IEEE ,2016:779-788.
[9] LIU W,ANGUELOV D ,ERHAN D,et al. SSD:single shot multibox detector[C]/14th European Conference on Computer Vision Amsterdam,The Netherlands :Springer,2016:21-3
[10] REDMON J,FARHAD A.YOLO9000: btter,faster, stronger[C]/2017 IEEE Conference on Computer Vision and Pattem Recognition (CVPR)。 Honolulu,HI,USAIEEE,2017:6517-6525.
[11] LIU S T,HUANG D,WANG Y H.Receptive field block net for accurate and fast object detection[C]/15th European Conference on Computer Vision. Munich ,Germany:Springer,2018:404-419 .
[12] REDMON J,FARHAD A.YOL Ov3:an incremental improvement[C//2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Salt Lake City,UT,USAIEEE,.2018:2767-2773.
[13]董永昌, 单玉刚,袁杰。基于改进SSD算法的行人检测方法[] .计算机工程与设计, 2020,41(10):2921-2926 .DONG Y C,SHAN Y G,YUAN J Pedestrian detection based on improved SSD[J]Computer Engineering and Design,2020,41(10)-:2921-2926 (in Chinese )
[14]陈柳,陈明举, 薛智爽,等。轻量化高精度卷积神经网络的安全帽识别方法[J/OL] .计算机工程与应用, 1-8[2020-11-25] http : https /ns-cnkinet-ncu1.naihes cn/kcms/detail/11.2127.TP.20201023.1727.009. html.CHEN L,CHEN M J,XUE Z S,et al.Lightweight and high-precision convolutional neural network for helmet recognition method[J/OL] Computer Engineering and Applications,1-8[2020-11-25]. http : hts:/kns- cnki-net--ncu1.naihes .cn/kcms/detai/11.2127.TP. 20201023.1727.009 html. (in Chinese )
[15]唐悦,戈,朴燕。改进的GDT-YOLOV 3目标检测算法却[J].液晶 与显示, 2020.35(8);852- 860. TANG Y,WU G,PIAO Y.Improved algorithm of GDT-YOLOV 3image target detection[J.Chinese Journal of Liquid Crystals and Displays,2020,35(8):852-860.in Chinese )
[16] LIU S,Ql L,QIN H F,et al. Path aggregation network for instance segmentation[]/Proceedings of 2018IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,UT,USA:IEEE,2018:8759-8768 .
[17] HUANG G,LIU Z,VAN DER MAATEN L,et al .Densely connected convolutional networks[C]/2017 IEEEConference on Computer Vision and Pattern Recognition.Honolulu,HI,USA:IEEE,2017:2261-2269.
[18] WOO S, PARK J,LEE J Y,et al.CBAM:convolutional block attention module[C]/2018 15th European Conference on Computer Vision. Munich, Germany:Springer,2018:3-19.
[19] ZHENG Z H,WANG P,LIU W.et al. Distance-loU loss faster and better learning for bounding box regression[J] Proceedings of the AAAI Conference on Artificial Itelligence,2020,34(7):12993-13000.
划线 高亮 笔记 摘录 词典 复制





