4.6 实验验证。
4.6.1 分析的数据集特性。
(1)darknet dataset 数据集属性。
当前,网络环境中常常会遭受 DDoS 等网络攻击。例如,其中一个在英国的一个非常著名的反欺诈网站,这个网站专注于和洗钱斗争,Bobbear 在 2008 年 11 月 12 日被 DDoS 攻击被破产,根据鲍勃哈里森网站的拥有者,每年大约有 300 万到 400 万攻击对东欧和亚洲的主机发起[48].
鉴于上述恶意行为,我们从 CAIDA 的存档使用公开可用的后向散射数据[49].此数据集是从 2008 年 11 月是时间期间,当上述袭击事件在互联网上发生。这些流量文件被 UCSD 捕获,他们只包含单向流量,例如进入的流量,根据 CAIDA 的揭示,这些数据集包括最多 DDoS攻击类型。并且也有以下扫描攻击。所以,这个一般的异常数据不同,表 1 展示了我们使用的反向散射数据的主要特征。这个数据集的大小为 102.7G.总共有 1317888867 个包,而且96%的包属于 TCP,尽管剩下的是 ICMP,端口号码 1032210717 和 80 个顶部使用的端口[50].
(2)kdd99 数据集。
kdd99 数据集是在 MIT 林肯实验室 DARPA 入侵检测数据集的基础上采用数据挖掘技术进行处理的数据集,在 MIT 林肯实验室 1999 年的数据集的原始流量中采集了 9 周数据集,数据集原本是模拟美国空军局域网所产生的网络流量。
kdd 的数据集分别纪录为 labeled 和 unlabeled 数据集,对于已标记的数据集,这些数据集被标记为正常连接和攻击连接,其中网络攻击被分为四种:
○1 DOS:拒绝服务攻击。
○2 R2L:未经授权的远程访问。
○3 U2R:未授权的访问。
○4 Probing:监视其他探测(3)数据集格式kdd99 中 labeled 数据被分为多个独立的流量,每一条流量为一条数据,多个特征值组成流量数据,最后一个特征值代表流量的所属类别。
举例一条典型的 ddos 攻击数据为例子,其数据格式:1032,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,511,511,0.00,0.00,0.00,0.00,1.00,0.00,0.00,255,255,1.00,0.00,1.00,0.00,0.00,0.00,0.00,0.00,smurf.
从数据集的最后标签可以看出该流量属于 smurf 攻击,前面的 41 项代表流量的其他特征值,该流量没有出现直接的 ip 等地址信息,因为已经被清洗。可以从三个方面描述数据特征:协议头的基本特性(主要为 TCP 包头信息)、内容特性、特定时间窗内的流量特性,其中时间窗内的流量特性可以分为源主机流量特性以及目的主机的流量特性。
4.6.2 衡量实验精度的性能指标。
混淆矩阵是一种特殊的表,包括实际和预测类信息来帮助分析评估人员评估使用分类器的性能通过检查 TP,TN,FP,FN.
在这项研究中,TP 代表被模型正确预测为正样本,TN 被模型正确预测到的负样本,另一方面,FP 被模型错误预测到的正样本,FN 被模型错误预测负样本。Accuracy 代表整体检出率,Precision 代表准确率,Recall 代表检出率。例如一个攻击数据包是错误配置的包。由上述计算分类器后,我们测量整体准确率,准确度,检出率,和 f 值通过混淆矩阵。
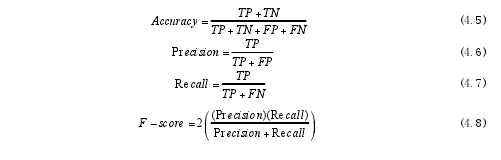
精度是指正确识别攻击数据包率超过只预测攻击数据包。回想展示了正确识别攻击报文在实际攻击数据包的百分比。特异性给人错误的标记非攻击报文在实际攻击数据包的比率。
F-得分是通过计算的精度和召回调和平均数计算。最后,精确度是正确的预测包括对整个数据集都正确地识别和拒绝值的比率。请注意,对于上述所有的条件,最好的结果始终是 1(100%)和最差的结果总是 0(0%)。我们的主要目标是设计一个分类,其结果可能和召回(灵敏度)准确和特异性比率越高越好,因为分类的目的是达到全面召回和特异性。这里应指出,错误预测的负样本(FNR)和错误预测的正样本(FPR)的分数通过使用等式测定。
FNR 1recall= (4.9)FPR 1specificity= (4.10)观察训练和测试组的数据划分如何影响一个监督分类器的性能,我们还通过分离数据集作为 80%的培训,20%的测试和 20%的培训,80%试验采用我们的数据集。据我们所知,这是第一次工作分析上述分类器的性能,并与两个著名的开源入侵检测系统的后向散射(地下网络)的数据集进行比较。在这项研究中,比较是通过评估使用上面以及给出比较它们的功能和复杂性的性能指标不同系统的性能进行。我们还采用的训练集不同尺寸以及不同的特征集来演示数据处理是如何在通过使用监督分类检测恶意活动是至关重要的。一个建设机器学习模型作为分类的主要挑战是使用一个精心准备的训练数据集,在那里发现大型数据集,与地面实情很难这种挑战成为网络和安全相关的问题明显。
在这一节中,我们评估 NIDSs 的性能,即临 brov 和 CORSARO V2.0.0,通过测量其精度和计算成本。此外,我们分析他们所使用的签名,事件或功能。因此,我们的目标是发现影响这些需求在两种处理时间和恶意流量检测成功率方面性能的主要因素。然后,我们利用spark,这是统计分析一个众所周知的工具实现 CART 决策树和朴素贝叶斯分类器。
4.6.3 实验环境的搭建。
(1)硬件配置实验平台的集群系统在实验楼机房中搭建而成,集群由三台服务器组成,在实验机器上安装了 Ubuntu12.04 系统。表 4.5 描述了机器的具体配置。
(2)软件支持实验中,在三台服务器中安装了三套 Ubuntu14.04,上面分别搭建了 spark 集群模式和 hadoop 完全分布式模式以便于实验测试,同时部署集群底层文件系统为 HDFS.每台机器的软件配置。
为了方便后面的平台搭建,我们对 3 台机器进行网络 IP 规划和机器名修改,并且配置了节点之间的 SSH 无密码连接。
(3)安装配置 Hadoop YARN从官网下载 hadoop2.6.0 版本,这里给个我们学校的镜像下载地址。
同样我们在~/workspace 中解压tar -zxvf hadoop-2.6.0.tar.gz配置 Hadoopcd ~/workspace/hadoop-2.6.0/etc/hadoop 进入 hadoop 配置目录,需要配置有以下 7 个文件:hadoop-env.sh,yarn-env.sh,slaves,core-site.xml,hdfs-site.xml,maprd-site.xml,yarn-site.xml(a)在 hadoop-env.sh 中配置 JAVA_HOME#<configuration>sbin/start-dfs.sh(e)将配置好的 spark-1.3.0 文件夹分发给所有 slaves输出:分类的流量Step1:加载和解析数据文件,该数据文件地址为(data/mllib/darknet_data.txt)Step2:把数据按比例分为 20%训练集和 80%测试集,80%训练集和 20%测试集进行试验。
Step3:获得训练朴素贝叶斯模型,第一个参数为数据,第二个为平滑参数。
Step4:对模贝叶斯模型进行准确度分析。
Step5:保存并加载模型,模型地址为("target/tmp/myNaiveBayesModel");





