一、多组样本检验
管理研究常会遇到两个以上的样本检验问题,要判断这些样本是否来自同一总体。参数检验时,一般采用基于方差分析( analysis of variance)的F检验法。
t检验用于判断两组样本均值间的差异,而F检验是用方差分析来判断两组以上样本的均值是否存在差异。t检验判断因变量的两均值差异是来自样本随机误差还是自变量的差异。F检验的思路类似,将误差分为两种,一种是样本组内误差,一种是源于自变量不同处理带来的组间误差。F值也是个比例值,分子代表组间差异,分母则代表组内误差,如组间处理误差显著大于随机误差,F值将拒绝对立假设。下面用示例来说明F检验的算法。
算例某连锁超市,有18个店面。对蔬菜销售价格采取三种打折策略:九五折、九折和八五折。每种策略随机分配到6个店面去实施,一个月后,管理者根据销售额的信息,判断不同打折策略的效果是否有显著差异。相应数据见表5-8。
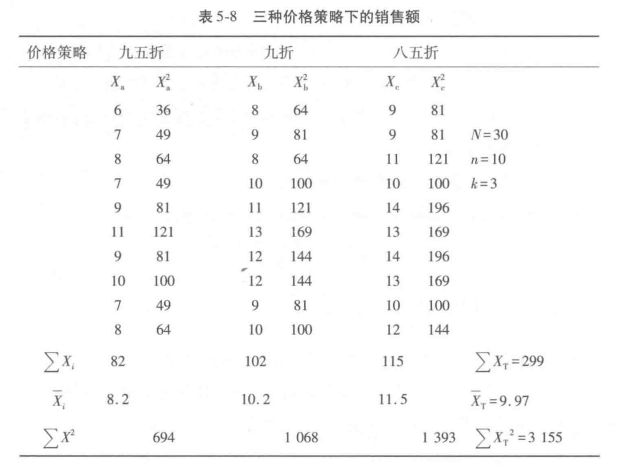
①假设表述。对立假设H0:三种价格策略下的销售额无差异。
研究假设Ha:三种价格策略下的销售额有差异。
②选择统计检验方法。由于是三个独立样本,定比尺度,选择F检验。
③选择适当的显著度。a=0.05 ,n=200,df=n-1。
④计算统计值F。算式为:
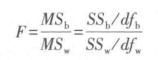
式中,组间方差:
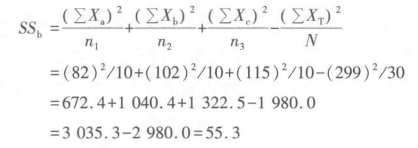
总体方差: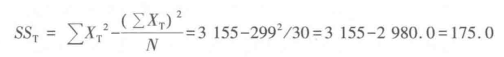
组内方差:
组间均方差:组间方差SSb=55.3,自由度为k-1=3-1=2,MSb=27.65
组内均方差:组内方差SSw=119.7, 自由度为3(10-1)= 27,MSw=4.43
总体方差自由度为29
算出F值: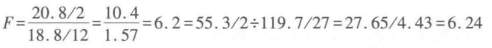
⑤确定临界值。按显著度a=0.05查F分布表(附表3),表中n1示组间自由度,n2表示组内自由度,本例中相应为2和27,查得F临界值为3.35。
⑥判断。计算统计值大于临界值(6.24>3.35),拒绝对立假设,表示不同的折扣会引起销售额的变化。
上述判断只能说明三种价格策略下的销售额均值存在差异,至少有一对策略如此。但它们之间的相互差异状况,可能是d1=d2而d1≠d3,也可能是d1和d2、d3,及d2、d3,之间均有差异。F检验无法得知任意两对策略之间是否有显著差异,为了弥补该缺陷,可进而使用t检验。对于三个样本组, 按排列组合的方式要做三次t检验,当组数增加时,就更为复杂。应用统计学者研究出不少方法来解决这类多重两两比较问题,如Scheffe检验法、Tukey检验法等。如论文工作需要,可参阅应用统计教材。
二、注意问题
专业研究生学位论文的实证研究常离不开上述的统计检验。如同自然科学中的实验,只有对实验数据误差的影响程度作出判断,才能得出正确结论,论文的数据分析结果只有经过统计检验,才能作为论证的证据。正确运用统计检验,是符合科学性的标志。从专业学位论文的实际来看,统计检验运用不当的情况并不少见,主要表现有以下几点。
1.应用目的不明确
t检验或F检验是推论环节,打算推论出什么样的结论,即判断哪两个或多个均值之间的差异,须说清楚。
现在有许多应用统计软件如SPSS等,研究者不必人工计算,也不用去查表选临界值,只要输人数据,计算机就能输出结果,工作效率很高。但这会导致有的研究生未弄懂统计检验的道理,不了解t和F等统计量的含义,也能得出形式上规范的结果。研究生应用这些软件之前,必须弄清为什么要进行这项统计检验,该用参数检验还是非参数检验,单组样本还是多组样本,样本是独立的还是相关的,所检验的对立假设和研究假设是什么,为什么选t、F或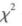 作为判据的统计量等,弄清以后才能得到正确的结果。
作为判据的统计量等,弄清以后才能得到正确的结果。
2.混淆显著度水平a和概率p的概念
首先,是将显著度水平a和概率p混为一谈。实际上a是研究者选定的允许“对立假设为真而予拒绝”的事件发生的概率,而p值是根据抽样样本数据算出来的、实际出现的对立假设为真的事件概率。研究者一般都希望p<a,这样就可得出拒绝对立假设而接受研究假设的结论。
其次,是把显著度a的大小理解成含有差异程度的意思。其实,显著度只是一种判断的依据,表示在对立假设的检验中对误差的容许程度,并不涉及该统计值与参数值差异的大小强弱,不是说p值越小,两个均值之间的差异越显著。例如,比较两种训练方法的效果,当假设检验水平定为a=0.05,且p≤0.05时,或a=0. 01,且p≤0.01时,都只是说明检验结果拒绝对立假设所对应的无差别判断。研究者选择a=0.01 ,并非是指预期统计值与参数值的差异,要比选择a=0. 05时来得大或更显著,只不过是容许误判事件出现的概率更小。两者都只能作出“差异有统计学意义”的结论。
最后,当计算出的p值大于给定的a值时,就认为可以得出两组结果无差异的结论,那也是误解。一般情况下都依据p≤a,而不是依据p>a来作结论。p≤a情况下是拒绝对立假设,即无差别假设,然而p>a时,并不意味着接受对立假设,如a=0.05 ,p>a,只是说明对立假设为真而被拒绝的事件概率大于0.05罢了。并不等于证实对立假设为真。
3.忽视对样本的要求
统计检验前,未考量数据是否符合t检验和F检验的要求,包括独立性和符合正态分布等条件。有的将配对设计的非独立样本当作随机样本来推论,这就降低了检验的有效性。
当观测的样本数很大时,即便是统计值与参数值差异很小,也容易得到p≤0.01的结果,此时还需要关注差异本身的大小( efective size)。观测样本很小时,即便统计值差异很大,也容易得出p>0.05的结论,此时就需要收集足够的样本。
实际应用中,样本数一般大于50就可不必作正态性检验,如样本较少,可根据样本均值与标准差的关系来判断,若原始数据均为正数,如果2倍标准差之值小于均值,则可用t检验。对于两组样本数据比较,还要求较大方差与较小方差之比应小于2。





