4. 3 语义标注算法
经过初步加工后的领域语料,已经形成了段落、句子两个级别的文本片段。语义标注需要运用领域本体知识库中的相关资源,实现文本片段内容的语义化标注。
定义: 对于一篇领域文档片段 D,按照文本向量空间模型,将 D 切分成词的组合 D = { w1,w2,w3,…,wn} ,其中这组词是已经经过《领域专业词典》切分过的,并且过滤了停用词,对于领域本体知识库 S = { P→Q;P∈语义概念集合,Q∈语义概念之间的关系} ,最后标注的结果是文档 D 的语义 T = { wi,wj; wi∈P × D,wj∈Q × D} .语义标注算法是试图分析领域文本片段所表现的语义,在标注过程中,主要参考的是领域概念实体或概念实体属性在文本片段中的共现,描述相关概念的文本片段一般会在文本中出现该概念相关的内容,而这部分内容是描述概念和概念的属性,所以会出现与概念和概念的属性相关的词汇。
语义标注算法同时也使用了领域本体知识库的领域数据进行标注,主要将领域本体中概念的属性 2 作为判断段落语义相关程度的因素。以铝行业本体库为例,多功能天车是一个概念,它拥有一些属性,其中包括结构 1 和结构 2.这两个属性中都有属性值,结构 1的属性值是领域文本中对多功能天车结构的专业描述,结构 2 的属性值是对结构 1 的属性值进行切分后,自动选出与该属性最相关、且被包含在本体词表中的词语。
具体的标注特征规则如下:
? 如果领域文本片段中出现概念实体,则相较于未出现该概念实体的文本片段,该段文本与该概念实体更相关。
? 如果领域文本片段中出现概念实体,则文本片段中出现的概念实体次数越多,该段文本与该概念实体越相关。
? 如果领域文本片段中出现概念实体及其属性,则该文本片段与未出现属性的文本片段相比,更加全面地表述概念实体。
? 如果领域文本片段中出现概念实体,并且出现概念实体的属性更多,则该文本片段与出现属性比较少的文本片段相比,更加全面地表述概念实体。
? 如果领域文本片段中出现概念实体及其属性,则概念实体和概念实体属性出现的文本距离较近的文本片段,比文本距离较远的概念实体更能较为准确地表现实体。
? 如果领域文本片段中出现了多个概念实体及其属性,则概念实体本身及其属性出现次数较多的概念实体,则更能表达该段文本的语义。
? 如果领域文本片段中出现了概念实体,则文本片段中出现的概念实体的属性 2 的次数越多,覆盖越全,该文本片段与该概念实体越相关。
语义标注算法如下:

在针对段落的标注过程中,可能有领域文本片段出现多个概念实体的情况,在语义标注的过程中,也将该段文本标注为不同概念实体索引到的文本片段。但是,也会根据前面的标注规则,将特征更为明显的语义赋予更高的权重,这样,一份文本片段也可能被多个语义概念所索引。
语义索引中对于文档的语义索引分数计算方式如下:

其中,word_count 是标注文档中词的个数,class_count 是标注文档中出现的实体的个数,property_count是文档中出现的属性的个数,paragraph_dis 是标注文档的距离( 以词为单位) ,semantic_dis 是标注文档中最近的语义关键词的距离,property2_count 是该属性的属性 2 的词数,occur_property2_count 是出现的属性 2 的词数。因而,SemanticScore 的计算参考了类名、属性名、类和属性距离、属性 2 这 4 种因素,其中 α,β,δ,γ是权重因子。
同时,对文本进行语义索引时,利用本体概念属性词表,通过循环查找词表提取关键词,按提取的关键词从倒排索引中提取文本集合,获得文本集合并计算文本的语义分数。然后通过信息检索的向量空间模型和布尔模型计算的得分进行加权计算,得出综合分数来对倒排索引中的文件进行排名,并存储至索引库中供用户进行检索。

coord( q,d) : 一次搜索可能包含多个搜索词,一篇文档中也可能包含多个搜索词,若一篇文档中包含的搜索词越多,则此文档打分越高;queryNorm( q) : 计算每个查询条目的方差和,此值并不影响排序,而仅仅使得不同的 query 之间的分数可以比较。
4. 4 语义标注结果
语义标注的结果是形成领域的语义索引,语义索引主要保存了一个文档文本片段的 3 个主要信息: ①文本粒度,分成层次级别( 篇章、段落、句子) ; ②文本片段的内容; ③文本片段的语义。
当通过语义标注算法标注过一篇文档之后,根据标注出的对应实体对应属性,向对应的标注索引文件中添加文档的记录,由于文档是经过分段处理后进行标注的,所以,实验中实际存储的是标注文档的对应位置及段落。同时,也要存储根据算法得到的对应文档对应于该本体属性的语义索引分数值。
这样,在具体的数据结构表示上,保存为一个倒排表,这个表的键为概念语义,表的值为这些索引的相关文档片段以及这组相关文档片段的语义索引分数值,文档的分数越高,表明其与该实体属性的语义越相关。
5 结果分析与应用
实验将针对语义标注的性能和结果作分析,一方面,利用领域本体标注领域语料,使用铝行业本体去标注铝行业领域文档,并且对结果作了评价,排序质量较搜索引擎有所提高。另一方面,利用标注后的语料更新领域本体,对标注后的语料进行加工处理后,生成了新的属性 2,可以填充和丰富本体,达到进化本体的目的; 同时,利用本体中的概念及其属性描述,在自动撰写方面开展了应用。
5. 1 利用领域本体标注领域语料
通过搜狗搜索引擎检索铝行业领域的特定检索词,利用返回的前 10 页结果作为铝行业领域的领域标注语料。检索词由两部分组成: 第一部分是领域概念实体的名称,第二部分是该领域概念实体的属性,如图2 所示:
利用现有的铝行业本体资源,分析语料内容语义之间的关系,对语料进行语义标注。针对铝行业文本资源的特点,通过分析研究和计算,将语义索引分数中的几个权重设置为 α =1,β =1,δ =0.7,γ =1.5.
通过对搜狗搜索引擎返回的结果文档进行标注,按照计算好的语义索引分数进行排序,得到关于该实体属性的一组排好序的领域文档片段集合。人工整理语料中文档语义内容与语义检索词的关联程度,按照语义相关性进行排序后,得到一组排序好的与语义检索词相关的领域文档。然后根据人工整理的语义文档顺序,分别计算搜狗搜索引擎返回的文档顺序和语义标注算法的文档顺序的逆序数,实验结果见表 1( 逆序数越小越好) .

可以看到,语义标注算法将搜狗引擎与人工排序的结果的逆序数降低了 55%,可以较好地提升语义相关文档的排序。其中主要原因是语义标注算法考虑了文档内容与语义之间的关联,利用领域本体库中语义实体属性2 的值,可以有效地统计片段对于实体属性2的覆盖程度,同时也考虑了语义实体、属性共现和距离等因素。
5. 2 利用标注后领域语料更新领域本体
通过领域本体库进行语料标注之后,得到了语义索引,即一组与实体的属性语义相关的经标注后的领域文档,按照语义索引的分数,将最能够表现领域实体属性语义的文档片段进行切分标注,即可得到该实体属性的属性 2.这一组属性 2 是通过语义标注学习获得的,可以有效地填充本体,达到本体进化的目的。
在对铝行业领域文档进行标注之前,可以看到平台中有了初始本体属性 2 的相关数据,这次试验主要使用的是铝行业本体。语义标注前,统计相关的属性2 的结果,如表 2 所示:
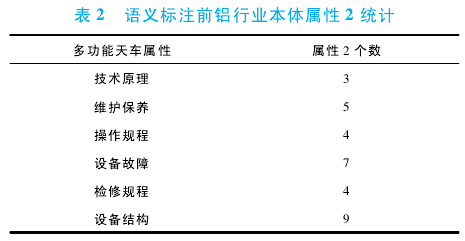
经过上一节实验的语义标注之后,平台会根据语义标注的分数自动选出语义最相关的文档,经过领域专业切分之后,根据属性 2 所定义的作用范围查看相关的实体,符合要求的被增加到平台的属性 2 之中,如图 3 所示:
语义标注后增加的属性 2 的统计结果如表 3 所示:

可以看到,经过语义标注后的语料可以更新领域本体库的数据,这样,本体知识库的内容也就得到了进化。更新后的领域本体知识库又可以更好地提升语义标注算法的性能,通过网络获得更多的领域文档。这样,领域本体库的内容和语义标注的语料都得到不断的更新、进化,形成互动,达到一体化的目的。
5. 3 自动撰写
根据本体库中概念的属性组织结构来表现本体知识,而本体知识本身的属性内容是一组经过语义标注的表现该属性的领域语料集合,选出最能表现该属性的语料内容作为自动撰写生成页面的内容。利用本体中的概念及其属性描述,将索引库里现有的文件以及结合爬虫抓取专业的结构化语料作为信息来源,利用TextRank 的打分思路提取摘要,在自动撰写方面开展应用研究。TextRank 的打分思路是从 PageRank 的迭代思想中衍生的[9].

等式左边表示一个句子的权重( WS 是 weight_sum的缩写) ,右侧的求和表示每个相邻句子对本句子的贡献程度; 求和的分子 wji表示两个句子的相似程度,分母又是一个 weight_sum,而 WS( Vj) 代表上次迭代 j 的权重,整个公式是一个迭代的过程。
相似度的计算则采用 BM25 算法计算文件集的相关度矩阵[10],对 Query 进行语素解析,生成语素 qi; 对于每个搜索结果 D,计算每个语素 qi 与 D 的相关性得分; 将 qi 相对于 D 的相关性得分进行加权求和,从而得到 Query 与 D 的相关性得分; 以本体中概念及其属性为基础,对相关句子进行迭代投票,计算排序后输出并生成自动撰写结果,如图 4 所示:
6 结语
本文研究了智能搜索引擎关键技术---语义标注的相关内容,提出了利用结构化语义概念资源或集合对文本进行自动标引的方法。从语义标注的整体框架和思路开始,阐述了建立语义索引的整个流程,评价了智能搜索引擎的检索结果,还阐述了智能搜索引擎的应用,体现了本体库与语义标注语料不断更新、进化、形成互动的过程,为专业领域的语义自动标注及智能搜索引擎的构建提供了有益的参考。目前,笔者只在铝行业相关领域开展了智能搜索引擎的研究及应用,今后,计划在更多的领域及行业开展研究与应用。
参考文献:
[1]Liu Yao,Sui Zhifang,Zhao Qingliang,et al. On automatic con-struction of medical ontology concept 's description architecture[J]. International Journal of Innovative Computing,Informationand Control,2012,8( 5) : 3601 - 3616.
[2] Liu Yao,Chen Xuefei,Li Sujian,et al. A semantic analyzingmethod in the field of technological literature[J]. ICIC ExpressLetters,2011,5( 9) : 3225 - 3230.
[3]Liu Yao,Zhao Yazhen. Research on ancient literature corpus crea-tion and development of chinese traditional medicine[J]. ICIC Ex-press Letters,2009,3( 4B) : 1227 - 1232.
[4]Sui Zhifang,Liu Yao,Hu Yongwei. Extracting hyponymy relationbetween chinese terms based on term types ' commonality[J].ICIC Express Letters,2009,3( 4) : 1233 - 1238.





