
1引 言
SIGIR(Special Interest Group on Information Retrieval)年会是国际上信息检索(Information Retrieval,IR)领域最高水平的学术会议,自1978年至2012年已成功举办了35届.针对SIGIR会议主题及论文的统计分析可以在一定程度上反映出信息检索的发展动态。2002年,爱尔兰学者A. F. Smeaton等通过对SIGIR过去25届年会的主题和合着情况作分析,概要地展示了SIGIR25年中不同主题的分布及作者发文情况;2007年,荷兰学者D. Hiemstra等人对过去30年中SIGIR会议文献作分析并揭示了研究主题、作者分布及合着情况.在我国,马少平等于2006年以S IGIR三十年所收录的论文及其主题的发展变化为切入点,尝试映射出整个信息检索领域相关研究发展变化的历程和趋势;刘茜则通过对2006年SIGIR接收论文分析当年SIGIR最新的研究动向;窦永香等于2010年通过对SIGIR过去32届年会的主题归纳分析,总结了信息检索的主要方向和研究热点.
近年来,由于新技术的发展,以及新的信息检索需求出现,信息检索领域的研究也呈现出新的特点。因此在当前重新对过去一段时间SIGIR会议相关主题及发表的论文进行多角度的分析,可帮助信息检索领域的研究人员对该学科发展情况有所了解。本文将在前人的基础上,以2003年起至2012年间的十届SIGIR年会相关主题及文献、作者等信息作为研究对象,综合应用包括网络调查法、文献计量法、科学知识图谱、社会网络分析法、统计分析和比较分析等多种方法开展研究,以揭示在过去十年中SIGIR研究状况,从而以管窥豹地了解信息检索研究动向。为了有效地处理和分析论文和作者相关数据,本文主要使用BibExcel和Pajek两个工具辅助研究工作,BibExcel用于整理和统计作者合着数据,然后生成网络文件导入到Pajek,通过Pajek来生成作者合着关系网络知识图谱,并计算节点的度数和中心度,以此来分析在作者群体中的核心作者。
2 SIGIR近十年来年会的主题分析
SIGIR每年年会征稿时都会公布当年主要研究议题,面向全球的信息检索学者征集最新的研究成果。本文通过网络调查法统计了过去十年的大会主题,即从2003年召开的第26届SIGIR年会到2012年召开的第35届年会。
SIGIR年会的主题划分体现了主办方对信息检索研究方向的判断和预期,从2010年的第33届年会开始,SIGIR会议主题调整划分为11类,如表1所示。由于该主题划分方法已经连续三年保持不变,显示了该分类方法得到了全球信息检索领域研究人员的广泛认同。
对过去十年的年会主题分析比较,可以总结出以下三个特点。
(1)部分研究主题呈现动态变化。部分主题在早期多次列出而在后期变更描述方法,例如文本数据挖掘、词汇习得、面向信息检索的机器翻译、面向信息检索的机器学习、面向信息检索的自然语言处理等主题,在2010年至2012年的主题分类表中已经没有直接体现,而在早期的2003至2006年间则多次被提及。认真分析,发现这部分主题并非完全被排除在SIGIR会议主题中,而大部分通过分是通过调整、拆分、合并等方式融入到新的主题分类中,如文本数据挖掘,则被具体化为文本分类、文本聚类等多个更为具体的主题,从而使得文本数据挖掘这一研究方向更为突出。
(2)个别主题昙花一现。有些主题仅在个别年份出现,显示了该研究领域未受到足够的关注,或者随时间的发展相关主题的研究价值有所下降。如2003年的检索策略、2005年的Ad Hoc检索、2007年的面向化学结构的信息检索以及2008年的信息检索隐私等主题都是在当年出现一次,在随后的历届SIGIR年会中都不再被列为研究主题。
(3)SIGIR主要研究主题近年渐趋稳定。
2003年至2009年间SIGIR年会主题划分上与2010至2012年的分类有区别,但具体主题内容仍可可重新归入以上后期确定的11个主题分类中,显示出在过去十年里SIGIR研究主题较为稳定,尤其是近三年来保持不变,反映了以SIGIR为代表的信息检索研究领域已进入了较为成熟的发展阶段。
3 SIGIR近十年论文分析
3.1 论文数量分布
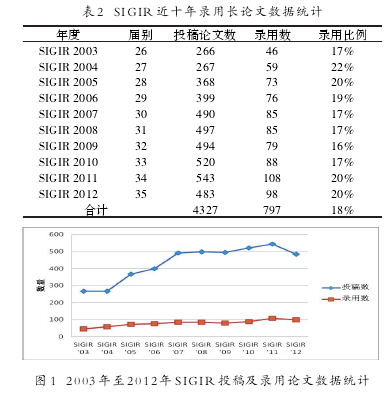
根据SIGIR官方公布的论文投稿及年会文集数据,其正式长论文(long paper)的投稿接收率通常在20%以下,每年接录用论文从2003年的不足50篇发展到近两年的100篇左右,自2007年以来SIGIR收到的论文投稿数量为500篇左右。过去十年,SIGIR收到的论文投稿总数为4327篇,正式录用论文为797篇,平均录用率为18%,表2列出了SIGIR近十年录用长论文数据统计情况,图1显示了历年投稿及数用文章数量变化。由于SIGIR历史悠久,且保持较低的长论文录用率,保证了收录论文的质量,使其多年来一直被公认为信息检索领域的顶级学术会议。【1】
3.2 论文主题分布
通过分析2003至2012年间SIGIR论文集的专题(topic session)设置,整理出58个主题(topic)。由于部分专题同时涉及多个主题或不属于任何已有主题的内容,需要对该专题下的论文进一步分析,通过鉴别论文的标题、摘要后按其实际研究内容重新进行主题划分,划归到58个研究主题之一,完成后得到近十年来SIGIR研究主题及相应主题论文数量统计表(见表3)。
对表3进行分析,可以发现过去十年SIGIR研究主题的特点,具体包括以下几个方面。
(1)主题类别发文量比较。“检索模型与排序”以147篇论文成为发文量最高的主题类别,其次是“文档表示与内容分析”以145篇占据第二位,“Web信息检索与社交媒体检索”和“检索评估”分别以86篇和81篇位列第3和第4位,后面的排序依次为“查询分析”(79篇)、“信息检索人机交互及用户行为”(73篇)、“信息过滤与推荐”(61篇)、“多媒体信息检索”(54篇)、“搜索引擎架构与可伸缩性”(51篇)、“信息检索与结构化数据”(19篇);发文量最少的类别是“其他应用”,只有1篇。
(2)研究主题发文量比较。在58个研究主题中,发文量大于等于20篇的主题为19个,约占全部主题的1/3;发文量在10到20篇之间的主题为13个;发文量小于10篇的主题为26个,占全部主题的一半。发文量在20篇以上的主题相关论文总数为516篇,占总论文数的64%,因此这部分主题是信息检索近年来的主要研究热点。最受关注的研究主题按其发文量排序依次为:机器学习与排序、综合评估、基于Web的信息检索、文本分类、文本聚类、查询分析(扩展、提炼、纠正等)、图像检索、人机交互与用户行为、检索模型、推荐系统、信息过滤/协同过滤、自动问答、语言模型(形式模型、概率模型)、效率评估、自动摘要、跨语言检索、分布式信息检索、信息检索理论、Web2.0(社交网络、媒体与社区)以及搜索引擎架构(伸缩与性能)。
(3)研究主题变化趋势。SIGIR已经成功举办过35届会议,相关研究主题也随着时代的变化而呈现出相应的特点。部分主题在过去十年中一直保持着较高的关注度,如文本分类、文本聚类、自动摘要、跨语言检索、自动问答、人机交互与用户行为、机器学习与排序学习、分布式信息检索、信息过滤、综合评估、基于Web的信息检索以及图像检索。有些主题出现时间较晚,是近年新的研究方向,如Web2.0(社交网络、社交媒体与社区)、社会化标签等主题都是在2008年之后才出现,个性化检索、效用评估、查询分析、垂直与本地检索等也是近年兴起的研究主题。此外,还有一部分主题的论文主要集中在2006年之前,此后已较少被研究,如基于XML的检索、歧义消除和Web结构与链接分析等主题。
(4)有关信息检索应用研究主题的论文偏少。
在主题分类中“其他应用”直接相关的论文数较少,该分类下只有一篇文章被分为数字图书馆主题。原因之一是部分针对具体应用的论文主要研究内容为信息检索理论与方法,因此被划分到相关度更高的其他主题中,另一方面原因是针对具体领域的信息检索应用和研究未能得到SIGIR的重视。
4 SIGIR论文作者分析
SIGIR过去十年接受的正式长论文共有797篇,相关作者共计2661人次,排除重复后,共有1568位研究人员曾在SIGIR发表论文,这是一个规模较大的信息检索研究学者群体。
4.1 作者发文分析
通过对SIGIR过去十年发文的作者进行统计,按发文数量多少排序,发文量及作者数量如表4所示。【2】
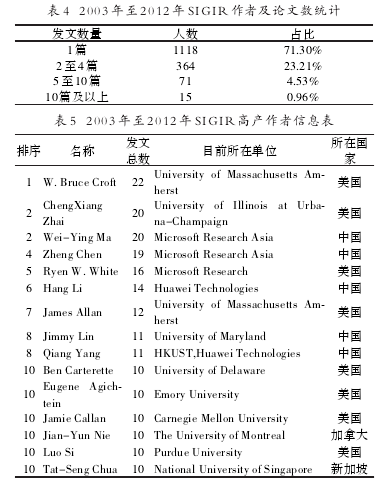
在过去10年中合计发文数量在10篇及以上的作者共15人,这15位作者人均每年至少在SIGIR发表论文1篇,组成了SIGIR高产作者群体,如表5所示。其中,W. Bruce Croft是最高产的作者,在过去10年 共 发 文22篇 ,其 次 是ChengXiang Zhai和Wei-Ying Ma均发表了20篇论文,并列第二。从作者当前所在单位看,目前工作单位主要集中在美国和中国,其中在美国工作的有9人,在中国工作的有4人。与美国主要科研人员均集中在大学不同,目前在中国工作的研究人员主要集中在工业界中顶尖企业的科研机构,其中Wei-Ying Ma(马维英)和Zheng Chen(陈正)在微软亚洲研究院,Hang Li(李航)和Qiang Yang(杨强)在华为诺亚方舟实验室,杨强同时还在香港科技大学任教。另一方面,15位高产作者中,华裔学者人数达到8人之多,由此也体现了华裔学者在该研究领域取得了突出成就。4.2 作者合着分析==4.2.1 合着统计论文的合着体现了研究人员之间的合作,如果把每个作者看作一个点,作者之间如果有合着关系则在两者之间添加一条连线,从而可将整个作者群体绘制成一幅合着关系图。借助文献题录分析工具BibExcel和社会化网络可视化分析工具Pajek,可以生成可视化合着网络图谱,并计算各节点的度数,度数越高表明该作者与越多的学者存在合作关系。
在2003年至2012年SIGIR年会发表的在所有论文中,只有38篇文章是个人独着的,其余759篇均为合着论文,这其中单篇论文合人数最多的达到12人,平均起来SIGIR每篇论文作者人数为1.97人。表6列出了具有合着关系的作者组合排序,反映的是在SIGIR研究和论文发表中保持稳定合作关系的学者组合,其中排名前三的组合分别是Wei-Ying Ma和Zheng Chen、Hua-Jun Zeng和ZhengChen以及Qiang Yang和Zheng Chen.【3】

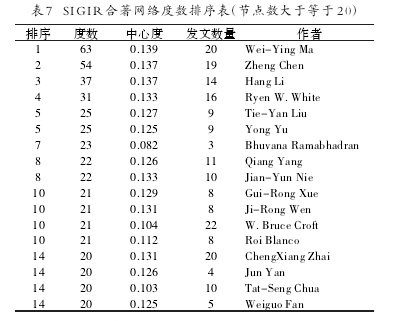
表7列出了2003年至2012年间SIGIR合着网络中节点度数大于等于20的作者列表,该表反映的是每位作者具体与多少位其他作者产生过论文合着关系,一般情况下度数越大表明该作者具有越广泛的学术合作圈。合着网络中度数排名前三的分别是Wei-Ying Ma、Zheng Chen和Hang Li,度数分别高达63、54和37.结合表7和表5进行分析,可以发现一般情况下发文量高的作者通常也具有较大的合着关系圈,表明这批作者是SIGIR过去十年中的核心作者群体。不过也有例外情况,从表7中可以看到Bhuvana Ramabhadran以高达23的度数排在合着网络排行榜的第7位,但该作者仅发表过3篇论文,这三篇论文的作者人数数分别为3、11和12,平均每篇论文的作者数高达7.7人,该指标远远高于所有论文平均作者人数。类似的情况还有在合着网络度数排行榜中排名并列第14的JunYan,同样是发表论文数量较少,但合作关系较广的典型。【4】
4.2.2 合着图谱将所有作者合着数据通过BibExcel生成合着图文件后导入到Pajek中,可以绘制出2003年至2012年SIGIR论文合着图谱(见图2),由于节点及连线较多未设置显示节点名称。从全中着图谱中,可以直观地发现分成两大组团,通过Pajek可以确定其中右侧组团以华裔学者为主,处于中心住置的分别是Wei-Ying Ma、Zheng Chen、Hang Li、Tie-Yan Liu、Yong Yu和ChengXiang Zhai等人;处于左侧的组团主要是非华裔学者,处于中心位置的分别是RyenW. White和W. Bruce Croft.为便于分析高产作者的论文合着情况,选取发文量为5篇及以上的作者共计87位,通过BibExcel生成作者合着网络文件,再通过Pajek进行可视化分析,生成合着网络图谱(见图3)。
通过对合着图谱分析,可以发现SIGIR高产作者具有如下的特点:
(1)高产作者群体中具有较好的合着关系,除了4个较小规模的合着关系网为独立网络之外,其余74位作者共同构成一个连通图。
(2)图谱显示合着作者聚类形成两个较大模型的组团,其中一个是华裔学者组团(图3左侧),另一个为非华裔学者组团(图3右侧)。这表明华裔学者在信息检索研究领域已占据得较为重要的地位,形成了多个高产的研究团队,足以和非华裔学者抗衡,这一现象从表5也有所体现,表5列出的15位高产作者中就有8位为华裔学者。另一方面也表明,华裔学者较少与非华裔学者进行论文合着,这是一个值得注意的现象。
(3)通过合着图谱可以直观地确定核心作者,分别有Wei-Ying Ma、Zheng Chen、Qiang Yang、Stephen Robertson和Emine Yilmaz等人。
(4)发文量最高的两位作者W. Bruce Croft和ChengXiang Zhai在合着图谱中并未占据中心位置,显示他们只是稳定地与少数作者开展论文合着合作。
5 结 语
对信息检索的研究现状进行分析,可以为这一学科的学者提供一个全面的视角,为开展新的研究和选题都有一定的借鉴意义。本文选取了信息检索领域最有影响力的学术会议SIGIR年会作研究对象,主要采用文献计量学、知识图谱和社会网络分析等方法对最近10年SIGIR年会的研究主题及论文和作者进行分析。首先通过对比分析整理了10年中SIGIR的研究主题,然后对过去十年里SIGIR所收录的正式长论文按研究主题进行重新划分,得到论文与主题统计表,以此来直观地研究各主题的受关注程度及演变趋势。然后分对别论文作者进行直接统计分析,以及基于社会网络分析及知识图谱的可视化方法对作者合着关系网络进行分析,确定了过去十年SIGIR的高产作者以及最具影响力的核心作者。
由于研究数据获取存在一定的困难,ACM数据库中无法便利地导出文献的引文、关键词、作者所属机构、国家等重要信息,从而限制了分析研究工作开展的便利程度和研究深度,诸如面向引文分析的各种研究均受此限制无法开展。下一步值得开展的研究工作包括整理SIGIR论文的引文数据、关键词、摘要等信息,并进行基于内容和引文的分析,从而更清晰地掌握信息检索的发展脉络。





