
0、 引言
设计基于免疫的入侵检测系统的首要问题在于如何生成高质量的检测器, 检测器生成算法的好坏直接影响入侵检测系统是否值得使用。 小生境技术是模拟生态平衡的一种仿生技术, 基于小生境策略的检测器生成算法能够尽可能保留较好的基因遗传给下一代,并维持种群的多样性。 在此基础上,本文借鉴复杂网络的免疫策略, 改进成熟检测器的进化过程, 提出一种基于复杂网络免疫策略的检测器进化算法,并通过仿真实验对比两种算法的漏检率、误检率以及数据编码较长情况下对性能的影响,为该算法用于 IPv6 环境打下基础。
1、 复杂网络
计算机网络的迅猛发展给人类社会与生活带来巨大便利的同时,也带来一定隐患,例如各种不良信息和行为入侵计算机系统以及计算机病毒的大面积传播等。为了应对计算机网络环境的种种挑战,研究人员已经针对传统、 单一的入侵检测模型和算法存在的缺陷与不足, 将一些新的理论与入侵检测相结合,例如,借助自然免疫系统对入侵抗原表现出的高度鲁棒性、 自组织性和分布性以提高对未知模式的实时监测能力、 对异常行为的识别能力以及智能灵活的反应能力,提出更优化、高效的算法和模型,并已取得了一些成果,但真正高效、成熟的检测算法和模型还未出现,仍存在较大的研究和提升空间。
复杂网络理论通过研究各类互不相同的复杂网络之间的共性,寻找如何进行处理的普适方法。 复杂网络的研究正渗透到数理学科、 生命学科和工程学科等众多不同的领域,其复杂性体现在:
a) 结构复杂性:连接结构复杂、混乱,可能随时间发生变化。
b)节点复杂性:节点具有分岔、混沌等复杂非线性行为,可能存在多种类型的节点。
c)复杂性因素的影响:会受到各种影响和作用,网络之间存在密切联系。
自然免疫系统与计算机网络都属于复杂网络的范畴,可以通过对双方共性和个性的研究,探寻更好的基于自然免疫系统体系结构和原理的入侵检测方法,为计算机安全系统的设计与维护提供新的途径。
2、 复杂网络的免疫策略度
是单独节点属性中非常重要的概念, 在某种意义上,度越大,节点越重要。大量研究表明,许多实际网络的度可用幂律分布 P(k)∝k-γ来描述,也称无标度分布。 这样的网络中, 多数节点的度相对较低,少量节点的度很高。 人们通过实证性研究发现,Internet 的和 WWW 的幂指数 γ 均位于 2 与 3 之间,属于无标度网络,而无标度网络很容易受到攻击和入侵,因此选择合适的免疫策略尤为重要。无标度网络目前有三种免疫策略:
1)随机免疫
随机免疫,也称均匀免疫。随机免疫策略就是通过完全随机的方式选取网络中的部分节点。 度大的节点(感染风险高,即连接的节点多)和度小的节点(相对安全,连接的节点少)被选取的机会是平等的。若在无标度网络中采用这种策略,需要对几乎所有节点都实施免疫才能杜绝病毒传染的途径,并且需要获取全部节点的特征信息,难以在效率和可行性之间取得平衡。 这种方式类似于生物免疫学理论中的非特异性免疫,主要应用于个体进化的初始阶段。
2)目标免疫
目标免疫,也称选择免疫。 根据 Internet 的无标度特性,可以选择目标免疫策略,对少数度较大的节点进行免疫,降低与高感染风险节点相连的风险,大大降低病毒的感染规模。 目标免疫策略的效率要比随机免疫策略更高。 这种方式类似于生物免疫学理论中的非特异性免疫, 主要应用于群体进化的全部过程。
3)熟人免疫
目标免疫策略需要事先对网络中所有节点的度即特征信息进行全面了解, 才能准确选择度大的节点实施免疫。 这对于庞大、复杂、多变的 Internet 来说可行性较低。因此,Cohen 等人提出一种熟人免疫策略,从 N 个节点中随机选出比例为 p的节点,再随机选择每个被选节点各自的一个邻居节点实施免疫,被免疫节点占总节点数的比例为 f(可能存在共同邻居节点)。这种方式不需要了解所有节点的特征信息, 并且使得度大的节点被选中的概率高于度小的节点。
文献经过实验发现,熟人免疫和目标免疫的效果要远好于随机免疫, 而目标免疫的效果略好于熟人免疫。
3、 基于复杂网络免疫策略的检测器进化算法
3.1 算法改进思路
经仿真验证, 基于小生境策略的检测器生成算法能够改善未成熟检测器的生成效率和性能, 并且更适用于自体模式编码较长的情况, 具体见参考文献。
对于基于免疫的入侵检测来说, 检测器性能的优劣主要取决于检测器对非自体空间的分布效果,包括检测器对非自体空间的覆盖率(识别区域)和检测器间的重叠率。 亲和力反映了检测器与非自体模式之间的相似程度,即识别能力,亲和力越大,两者的相似度越高,检测器的识别能力越强;反之,识别能力越弱。因此,在原算法中,选取 Hamming 相似度计算亲和力函数作为算法搜索的依据, 并用于生成检测器的过程, 若待选字符串与非自体集合的亲和力越高,成为检测器的可能性就越高;反之,可能性越小。 若 i 与 j 有 q 个位上的值相同,则 i 对 j 的亲合力函数 g(i,j)值为:g(i,j) = q如果将复杂网络的免疫策略应用于生物个体和群体的免疫进化,在随机免疫中,所有个体发生进化的机会是一样的;在目标免疫中,群体进化的方向是可以选择的;而熟人免疫中,避免了对所有个体进行特征信息的了解, 并且能够提高选取与非自体之间的相似程度(即亲和力)的可能性。因此,本文利用基于小生境的检测器生成算法生成未成熟检测器,对原算法中成熟检测器的进化做出改进, 借鉴复杂网络的免疫策略, 提出基于复杂网络免疫策略的检测器进化算法。
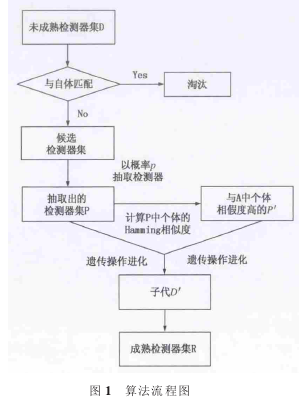
3.2 算法描述
再次利用亲和力函数优化父代检测器的选择。
选择部分检测器, 是为了通过遗传操作有针对性地提高部分个体的适应度;采用随机的方式选择,是为了保持种群的多样性; 再次选择与被选检测器亲和力高的检测器, 是为了避免在遗传操作中出现严重的退化现象。因此,基于复杂网络免疫策略的检测器进化算法描述如下: a)通过基于小生境的检测器生成算法生成未成熟的检测器集 D,见文献。 b)阴性选择:淘汰与自体发生匹配的未成熟检测器。c)成熟检测器的进化: 在余下的未成熟检测器中随机抽取比例为 p 的检测器集合 P, 再针对 P 中的每一个检测器随机选择一个与其亲和力最大的检测器,形成检测器集合 P′。 将它们作为父代,对父代进行交叉、变异、选择等遗传操作之后得到子代 D′。 将子代插入到父代中,得到成熟检测器集合 R。
基本的遗传操作同原算法一致:交叉、选择和变异。分别采用随机竞争选择、单点交叉和基本位变异的方式 。 在仿真实验中, 采用英国设菲尔德(Sheffield)大 学编写的遗传算法工具箱 ,交叉点数Npt=1, 交叉概率 XOVR=0.7, 变异概率 Pm=0.7/Lind,Lind 为个体的长度。 算法流程如图 1 所示。
算法伪码如下:Procedure Mature DetectorsBegin对 lmmature detectors D 中的 detectors 进行阴性选择,对与自体集合 S 发生匹配的detectors 进行删除;在 D 中余下的 detectors 随机抽取概率为 p的 detectors,得到 P;计算 P 中 detectors 与其它 detectors 之间的亲和力 g(i,j),选择与 P 中 g(i,j)最大的detectors,得到 P′;P+P′作为父代,进行交叉、变异、选择遗传操作,生成子代 D′;将子代插入父代,得到 Mature detectors R;End
3.3 仿真验证
检测器检测抗原的过程中可能出现两种错误,一种是将异常行为当作正常,即漏检;一种是将正常的行为当作异常,即误检。漏检率和误检率是评价入侵检测系统性能的重要指标。
实验环境:CPU:Intel(R) Pentium(R) Processor1.73 GHz; HD:160 GB; RAM:1.25 GB。 方便起见,未成熟检测器集合为 A, 本文算法进化得到的成熟检测器集合为 B, 原算法进化后得到的成熟检测器集合为 C。 对自体集合 S 取补产生非自体训练数据集合 testdata。 实验中,为在父代检测器的数量和多样性之间求得平衡,选择 p = 0.5。
3.3.1 漏检率与误检率
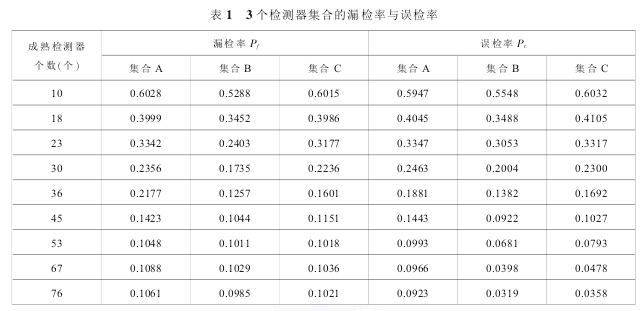
实验条件:非自体训练数据 testdata=10000 个,自体集合 S = 10 000 个,进制 m = 2,匹配阈值 r = 8,数据编码长度 l = 32, 检测器集合规模 NR=10,18,23,30,36,45,53,67,76;算法各独立执行 50次,求漏检率 Pf与误检率 Pt的平均值。 实验结果见表 1。
实验分析:通过表 1 可知,3 个检测器集合检测非自体训练数据 testdata 得到的漏检率 Pf和误检率Pt的变化趋势均随检测器规模 NR的增大而降低。检测器达到一定数量之后,Pf和 Pt降低的趋势变缓,B集合的 Pf和 Pt均低于 A 与 C 集合。 在上述情况下,B 集合的 Pf低于 A 集合 19.17%,Pt低于 14.30%;Pf低于 C 集合 20.05%,Pt低于 12.47%。
3.3.2 编码长度对漏检率与误检率的影响
实验条件:非自体训练数据 testdata =10 000个,自体集合 S = 10000 个 , 进制 m = 2, 匹配阈值r = 8,数据编码长度 l = 16,32,64,128,256,296,检测器集合规模 NR= 76;算法各独立执行 50 次,求漏检率 Pf与误检率 Pt的平均值。 实验结果见表 2。
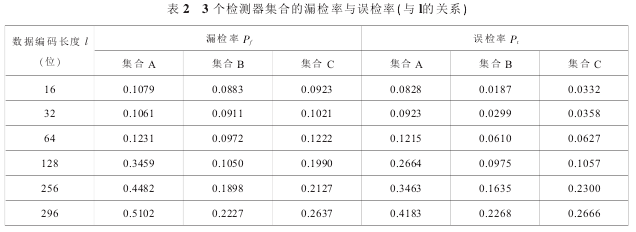
实验分析:通过表 2 可知,随着数据编码长度 l的增长,3 个检测器集合检测非自体训练数据 test-data 得到的 Pf和 Pt表现为增长趋势。A 集合的 Pf和Pt增长较快,B 与 C 集合增长较缓,B 集合 Pf的平均增长率为 24.3%,C 为 24.8%;B 集合 Pt的平均增长率为 66.04%,C 为 75.12%。总体上 B 集合的 Pf和Pt低于 A 与 C 集合。 在上述情况下,B 集合的 Pf低于 A 集合 56.99%,Pt低于 52.23%;Pf低于 C 集合20.68%,Pt低于 19.49%。
4、 结束语
本文在基于小生境策略的检测器生成算法的基础上进行改进, 提出了一种基于复杂网络免疫策略的检测器进化算法, 以期生成性能更好的成熟检测器。从实验结果来看,在检测器集合规模与数据编码长度相同的情况下,漏检率与误检率均低于原算法,并且漏检率与误检率的平均增长率也略低于原算法, 适用于 IPv6 环境下数据编码长度较长的情况,基本达到了算法最初的设计目标。
参考文献:
1. 刘海龙 , 张凤斌 , 席亮. 基 于 Monte Carlo 估 计的免疫检测器分布优化算法 [J]. 计算机应用, 2013, 33(3):723-726.
2. 汪小帆 , 李 翔 , 陈关荣. 复杂网络理论及其应用 [M].北京:清华大学出版社, 2006.
3. 李向华, 王 欣, 高 超. 复杂网络免疫策略分析[J]. 吉林大学学报:理学版, 2013, 51(3):444-452.
4. Madar N, Kalisky T, Cohen R, et al. Immunization andepidemics in complex networks [J]. The European PhysicalJournal B-Condensed Matter and Complex Systems,2004,38(2):269-276.
5. 时 晨, 申普兵, 沈向余, 等. 基于小生境策略的检测器生成算法[J]. 计算机技术与发展, 2011, 21(9):81-84.





